Lag Selection for Univariate Time Series Forecasting using Deep Learning: An Empirical Study

0
Sign in to get full access
Overview
- This paper investigates the impact of lag selection on the performance of deep learning models for univariate time series forecasting.
- The researchers conducted an empirical study to explore different techniques for determining the optimal lag length, including autocorrelation function (ACF), partial autocorrelation function (PACF), and deep learning-based approaches.
- The study evaluated the performance of these lag selection methods on various real-world time series datasets, comparing their forecasting accuracy and computational efficiency.
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/data-scaling-effect-deep-learning-financial-time">Time series forecasting</a> is a crucial task in many industries, from finance to supply chain management. It involves using historical data to predict future values of a variable, such as stock prices or demand for a product. One key aspect of time series forecasting is determining the optimal <a href="https://aimodels.fyi/papers/arxiv/rethinking-channel-dependence-multivariate-time-series-forecasting">lag length</a>, which refers to the number of past observations to include in the model.
In this study, the researchers explored different methods for selecting the optimal lag length when using deep learning models for univariate time series forecasting. They compared traditional statistical techniques, like the autocorrelation function (ACF) and partial autocorrelation function (PACF), with <a href="https://aimodels.fyi/papers/arxiv/adaptive-standardisation-methodology-day-ahead-electricity-price">deep learning-based approaches</a>.
The researchers tested these lag selection methods on various real-world time series datasets, such as stock prices and energy consumption data. They evaluated the forecasting accuracy and computational efficiency of the different approaches, aiming to identify the most effective way to determine the optimal lag length for deep learning models.
Technical Explanation
The paper presents an empirical study on the impact of lag selection on the performance of deep learning models for univariate time series forecasting. The researchers investigated three main approaches for determining the optimal lag length:
-
Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF): These traditional statistical techniques analyze the correlation between the current value of a time series and its past values, helping to identify the appropriate lag length.
-
Deep Learning-based Approaches: The researchers explored using deep learning models, such as <a href="https://aimodels.fyi/papers/arxiv/large-language-models-time-series-survey">Long Short-Term Memory (LSTM)</a> and Convolutional Neural Networks (CNNs), to automatically learn the optimal lag length from the data.
-
Hybrid Approaches: The study also considered combining the traditional statistical methods with deep learning-based techniques to leverage the strengths of both approaches.
The researchers evaluated the performance of these lag selection methods on various real-world time series datasets, including stock prices, energy consumption, and other economic indicators. They measured the forecasting accuracy using metrics like Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE), and also assessed the computational efficiency of the different approaches.
The results of the study provided insights into the effectiveness of the various lag selection techniques and their impact on the performance of deep learning models for time series forecasting. The findings can help practitioners and researchers make more informed decisions when selecting the appropriate lag length for their deep learning-based time series forecasting tasks.
Critical Analysis
The paper presents a thorough empirical investigation of lag selection methods for deep learning-based time series forecasting. The researchers have addressed an important practical challenge in the field and provided a comprehensive comparison of different approaches.
One potential area for further research mentioned in the paper is the exploration of <a href="https://aimodels.fyi/papers/arxiv/time-series-data-augmentation-as-imbalanced-learning">data augmentation techniques</a> to enhance the performance of deep learning models, especially when dealing with limited or imbalanced time series data.
Additionally, the authors acknowledge the need to assess the generalizability of their findings by applying the studied lag selection methods to a wider range of time series datasets and domains. This would help validate the robustness and practical applicability of the proposed techniques.
Another aspect that could be explored in future research is the impact of feature engineering and the incorporation of exogenous variables on the lag selection process and overall forecasting performance. This could provide additional insights into the factors that influence the optimal lag length for deep learning models.
Overall, the paper presents a valuable contribution to the field of time series forecasting, highlighting the importance of appropriate lag selection and providing a framework for evaluating different techniques. The findings can serve as a useful reference for practitioners and researchers working on deep learning-based time series forecasting applications.
Conclusion
This empirical study on lag selection for univariate time series forecasting using deep learning provides important insights for practitioners and researchers in the field. The researchers have explored various techniques, including traditional statistical methods and deep learning-based approaches, to determine the optimal lag length for time series forecasting tasks.
The findings demonstrate the significant impact of lag selection on the performance of deep learning models, highlighting the need for careful consideration of this aspect when designing and implementing time series forecasting solutions. The comparative analysis of the different lag selection methods can guide researchers and practitioners in selecting the most appropriate approach for their specific use cases and data characteristics.
The insights from this study can contribute to the development of more accurate and efficient deep learning-based time series forecasting models, with potential applications across a wide range of industries, from finance and supply chain management to energy and transportation. By understanding the importance of lag selection and the effectiveness of different techniques, practitioners can make more informed decisions and improve the overall performance of their time series forecasting systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lag Selection for Univariate Time Series Forecasting using Deep Learning: An Empirical Study
Jos'e Leites, Vitor Cerqueira, Carlos Soares
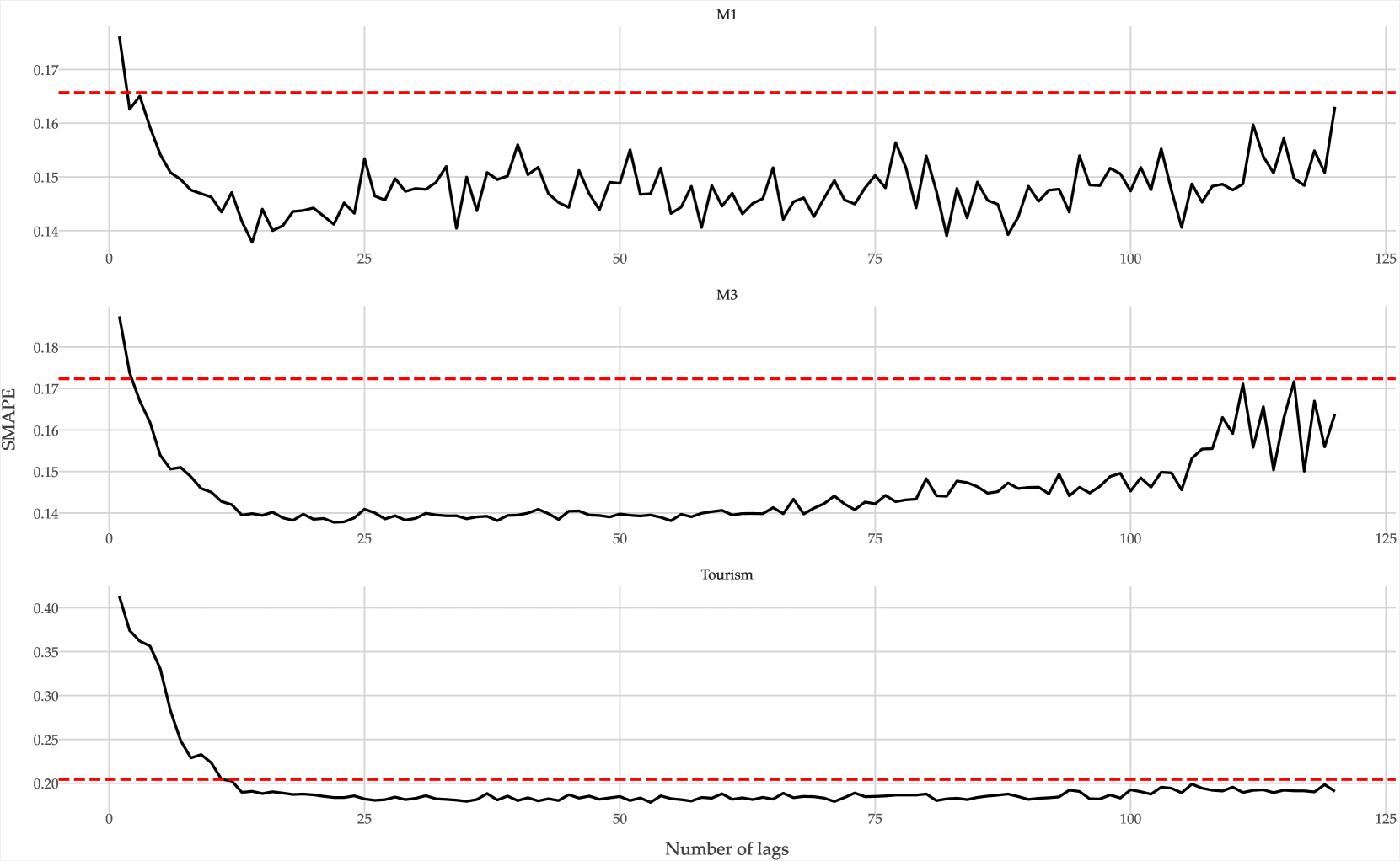
Most forecasting methods use recent past observations (lags) to model the future values of univariate time series. Selecting an adequate number of lags is important for training accurate forecasting models. Several approaches and heuristics have been devised to solve this task. However, there is no consensus about what the best approach is. Besides, lag selection procedures have been developed based on local models and classical forecasting techniques such as ARIMA. We bridge this gap in the literature by carrying out an extensive empirical analysis of different lag selection methods. We focus on deep learning methods trained in a global approach, i.e., on datasets comprising multiple univariate time series. The experiments were carried out using three benchmark databases that contain a total of 2411 univariate time series. The results indicate that the lag size is a relevant parameter for accurate forecasts. In particular, excessively small or excessively large lag sizes have a considerable negative impact on forecasting performance. Cross-validation approaches show the best performance for lag selection, but this performance is comparable with simple heuristics.
Read more5/21/2024
📊
0
Data Scaling Effect of Deep Learning in Financial Time Series Forecasting
Chen Liu, Minh-Ngoc Tran, Chao Wang, Richard Gerlach, Robert Kohn
For years, researchers investigated the applications of deep learning in forecasting financial time series. However, they continued to rely on the conventional econometric approach for model training that optimizes the deep learning models on individual assets. This study highlights the importance of global training, where the deep learning model is optimized across a wide spectrum of stocks. Focusing on stock volatility forecasting as an exemplar, we show that global training is not only beneficial but also necessary for deep learning-based financial time series forecasting. We further demonstrate that, given a sufficient amount of training data, a globally trained deep learning model is capable of delivering accurate zero-shot forecasts for any stocks.
Read more6/4/2024

0
AALF: Almost Always Linear Forecasting
Matthias Jakobs, Thomas Liebig
Recent works for time-series forecasting more and more leverage the high predictive power of Deep Learning models. With this increase in model complexity, however, comes a lack in understanding of the underlying model decision process, which is problematic for high-stakes decision making. At the same time, simple, interpretable forecasting methods such as Linear Models can still perform very well, sometimes on-par, with Deep Learning approaches. We argue that simple models are good enough most of the time, and forecasting performance can be improved by choosing a Deep Learning method only for certain predictions, increasing the overall interpretability of the forecasting process. In this context, we propose a novel online model selection framework which uses meta-learning to identify these predictions and only rarely uses a non-interpretable, large model. An extensive empirical study on various real-world datasets shows that our selection methodology outperforms state-of-the-art online model selections methods in most cases. We find that almost always choosing a simple Linear Model for forecasting results in competitive performance, suggesting that the need for opaque black-box models in time-series forecasting is smaller than recent works would suggest.
Read more9/17/2024

0
Forecasting with Deep Learning: Beyond Average of Average of Average Performance
Vitor Cerqueira, Luis Roque, Carlos Soares
Accurate evaluation of forecasting models is essential for ensuring reliable predictions. Current practices for evaluating and comparing forecasting models focus on summarising performance into a single score, using metrics such as SMAPE. We hypothesize that averaging performance over all samples dilutes relevant information about the relative performance of models. Particularly, conditions in which this relative performance is different than the overall accuracy. We address this limitation by proposing a novel framework for evaluating univariate time series forecasting models from multiple perspectives, such as one-step ahead forecasting versus multi-step ahead forecasting. We show the advantages of this framework by comparing a state-of-the-art deep learning approach with classical forecasting techniques. While classical methods (e.g. ARIMA) are long-standing approaches to forecasting, deep neural networks (e.g. NHITS) have recently shown state-of-the-art forecasting performance in benchmark datasets. We conducted extensive experiments that show NHITS generally performs best, but its superiority varies with forecasting conditions. For instance, concerning the forecasting horizon, NHITS only outperforms classical approaches for multi-step ahead forecasting. Another relevant insight is that, when dealing with anomalies, NHITS is outperformed by methods such as Theta. These findings highlight the importance of aspect-based model evaluation.
Read more6/26/2024