LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
2405.15622
0
0

Abstract
Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
0
0
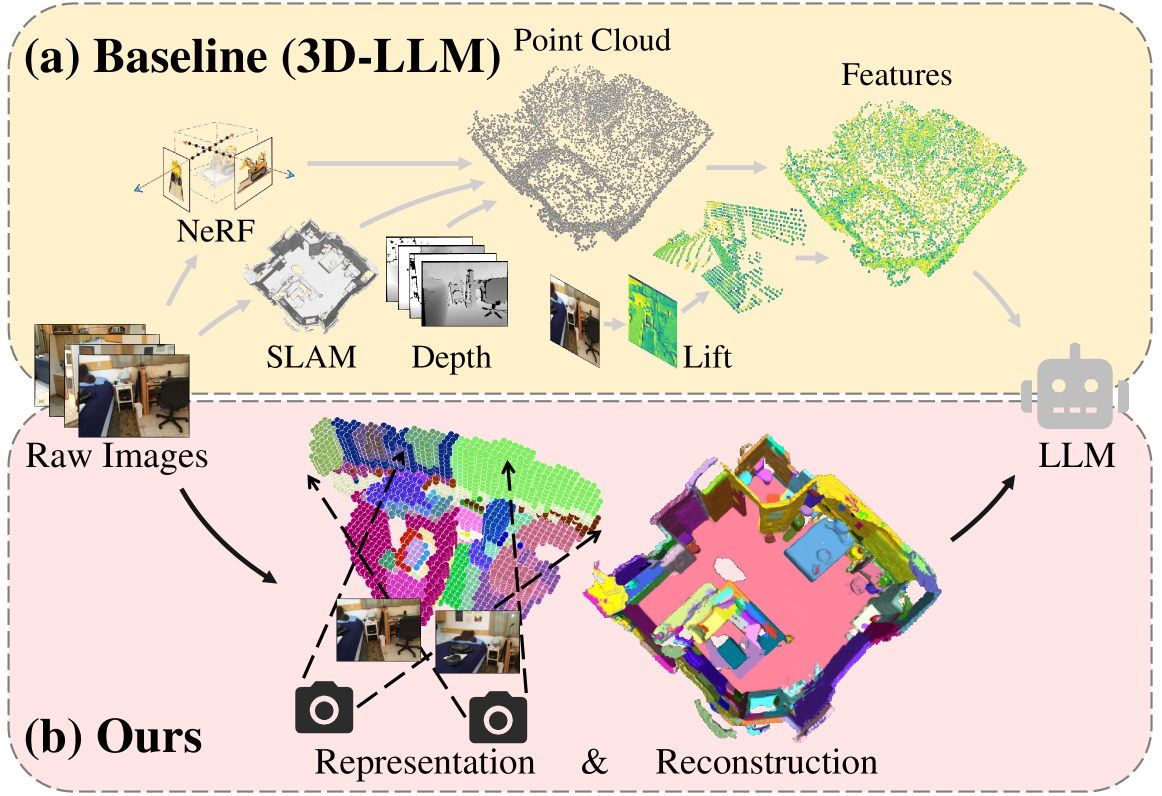
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
4/22/2024
💬
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Yixue Hao, Long Hu, Min Chen
0
0
Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
5/3/2024
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
0
0
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
6/24/2024
🛠️
Real3D: Scaling Up Large Reconstruction Models with Real-World Images
Hanwen Jiang, Qixing Huang, Georgios Pavlakos
0
0
The default strategy for training single-view Large Reconstruction Models (LRMs) follows the fully supervised route using large-scale datasets of synthetic 3D assets or multi-view captures. Although these resources simplify the training procedure, they are hard to scale up beyond the existing datasets and they are not necessarily representative of the real distribution of object shapes. To address these limitations, in this paper, we introduce Real3D, the first LRM system that can be trained using single-view real-world images. Real3D introduces a novel self-training framework that can benefit from both the existing synthetic data and diverse single-view real images. We propose two unsupervised losses that allow us to supervise LRMs at the pixel- and semantic-level, even for training examples without ground-truth 3D or novel views. To further improve performance and scale up the image data, we develop an automatic data curation approach to collect high-quality examples from in-the-wild images. Our experiments show that Real3D consistently outperforms prior work in four diverse evaluation settings that include real and synthetic data, as well as both in-domain and out-of-domain shapes. Code and model can be found here: https://hwjiang1510.github.io/Real3D/
6/13/2024