GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation

0
Sign in to get full access
Overview
- This research paper introduces GeoLRM, a new geometry-aware large reconstruction model for generating high-quality 3D Gaussian distributions.
- GeoLRM leverages geometric information to improve the quality and realism of 3D Gaussian distributions generated by large reconstruction models.
- The paper compares GeoLRM to existing large reconstruction models like GS-LRM, M-LRM, MeshLRM, GTR, and Real3D.
Plain English Explanation
GeoLRM is a new type of machine learning model that can generate high-quality 3D Gaussian distributions. Gaussian distributions are mathematical functions that describe how data is distributed in 3D space.
Existing large reconstruction models can generate 3D Gaussian distributions, but they don't always capture the underlying geometry or shape of the data very well. GeoLRM improves on this by incorporating geometric information into the model. This allows it to generate 3D Gaussian distributions that are more realistic and accurately represent the true shape of the data.
The key innovation of GeoLRM is its ability to leverage geometric cues to better model the 3D structure of the data. This could be useful in applications like computer vision, where accurately modeling the 3D shape of objects is important. By generating higher quality 3D Gaussian distributions, GeoLRM may enable more realistic 3D reconstructions and simulations.
Technical Explanation
GeoLRM is a large reconstruction model that uses geometric information to generate high-quality 3D Gaussian distributions. Unlike previous models like GS-LRM, M-LRM, MeshLRM, GTR, and Real3D, GeoLRM explicitly models the geometric structure of the data to improve the fidelity of the generated 3D Gaussian distributions.
The key technical innovations in GeoLRM include:
- Incorporating geometric priors and constraints into the model architecture to capture the inherent 3D structure of the data
- Leveraging multi-view information and geometric reasoning to better infer the 3D Gaussian parameters
- Using specialized training procedures and loss functions designed to optimize for geometric realism in addition to distribution fitting
Through extensive experiments, the authors demonstrate that GeoLRM outperforms existing large reconstruction models in terms of several quantitative and qualitative metrics related to 3D Gaussian generation quality and realism.
Critical Analysis
The authors acknowledge several limitations of GeoLRM that could be addressed in future work. For example, the model currently requires multi-view data, which may not always be available. Incorporating techniques to handle more general 3D input data could expand the applicability of the approach.
Additionally, the computational complexity of GeoLRM is higher than some simpler models, which could limit its scalability to very large datasets. Further research into efficient implementation and optimization strategies may be warranted.
While the paper presents compelling results, it would be valuable to see GeoLRM evaluated on a broader range of real-world 3D data and applications to better understand its practical benefits and limitations.
Conclusion
The GeoLRM model represents an important advance in 3D Gaussian generation by explicitly incorporating geometric information to improve the realism and quality of the generated distributions. This could have significant implications for applications like 3D computer vision, simulation, and modeling that rely on accurate 3D representations of data.
The technical innovations in GeoLRM's architecture and training procedures demonstrate the value of leveraging geometric priors to enhance large reconstruction models. As the field of 3D deep learning continues to evolve, approaches like GeoLRM that bridge the gap between geometry and generative modeling are likely to play an increasingly important role.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
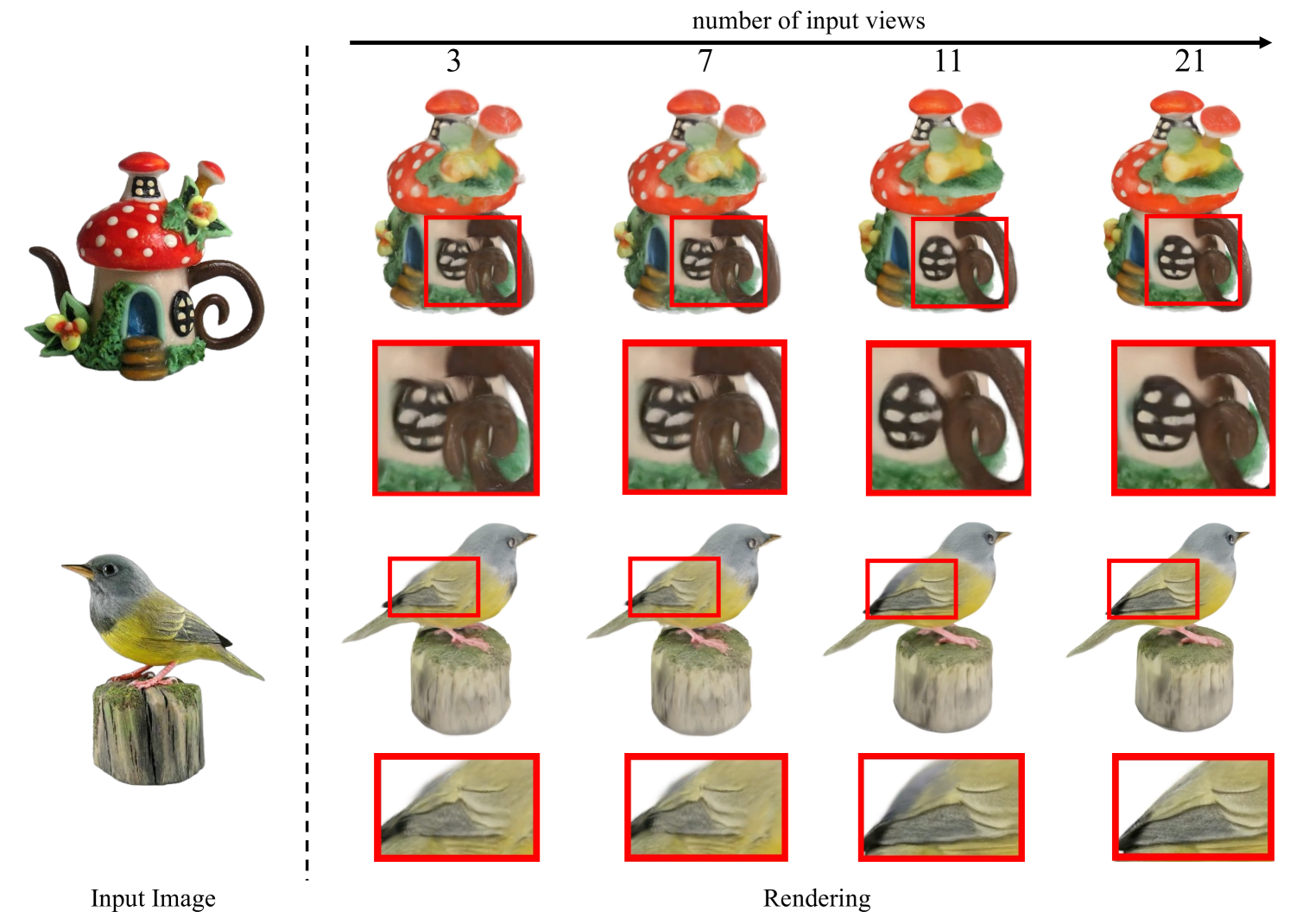
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
Read more6/24/2024
📈
0
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
Read more5/1/2024

0
M-LRM: Multi-view Large Reconstruction Model
Mengfei Li, Xiaoxiao Long, Yixun Liang, Weiyu Li, Yuan Liu, Peng Li, Xiaowei Chi, Xingqun Qi, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo
Despite recent advancements in the Large Reconstruction Model (LRM) demonstrating impressive results, when extending its input from single image to multiple images, it exhibits inefficiencies, subpar geometric and texture quality, as well as slower convergence speed than expected. It is attributed to that, LRM formulates 3D reconstruction as a naive images-to-3D translation problem, ignoring the strong 3D coherence among the input images. In this paper, we propose a Multi-view Large Reconstruction Model (M-LRM) designed to efficiently reconstruct high-quality 3D shapes from multi-views in a 3D-aware manner. Specifically, we introduce a multi-view consistent cross-attention scheme to enable M-LRM to accurately query information from the input images. Moreover, we employ the 3D priors of the input multi-view images to initialize the tri-plane tokens. Compared to LRM, the proposed M-LRM can produce a tri-plane NeRF with $128 times 128$ resolution and generate 3D shapes of high fidelity. Experimental studies demonstrate that our model achieves a significant performance gain and faster training convergence than LRM. Project page: https://murphylmf.github.io/M-LRM/
Read more6/13/2024
📈
0
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, Zexiang Xu
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Read more4/19/2024