Real3D: Scaling Up Large Reconstruction Models with Real-World Images

0
🛠️
Sign in to get full access
Overview
- The paper introduces Real3D, a novel system for training large reconstruction models (LRMs) using single-view real-world images, rather than relying solely on synthetic data or multi-view captures.
- Real3D uses a self-training framework that can leverage both existing synthetic data and diverse single-view real images to train the LRM.
- The system introduces two unsupervised losses that allow for pixel- and semantic-level supervision of the LRM, even without ground-truth 3D data or novel views.
- An automatic data curation approach is also developed to collect high-quality examples from in-the-wild images to further improve performance and scale.
Plain English Explanation
Large reconstruction models (LRMs) are machine learning systems that can generate detailed 3D models from 2D images. Traditionally, these models have been trained using large datasets of synthetic 3D assets or multi-view captures of real-world objects. While this simplifies the training process, it's difficult to scale these datasets beyond what already exists, and they may not accurately represent the true distribution of object shapes found in the real world.
To address these limitations, the Real3D system introduces a novel self-training framework that can leverage both existing synthetic data and diverse single-view real-world images to train LRMs. This means the model can learn from a much broader and more realistic range of object shapes, without requiring expensive and labor-intensive 3D data collection.
Real3D uses two new "unsupervised" training techniques that allow the model to learn from 2D images alone, without needing ground-truth 3D models or multiple views of the same object. The first loss function focuses on the pixel-level details of the image, while the second looks at the semantic-level understanding of the object's shape and structure.
To further improve the quality and diversity of the training data, the researchers also developed an automatic data curation system. This tool can identify high-quality, representative examples from a large pool of in-the-wild images, which are then used to train the LRM.
Through extensive experiments, the authors show that Real3D consistently outperforms previous LRM systems, both on synthetic benchmarks and when applied to real-world objects. This suggests the approach can lead to more accurate and versatile 3D reconstruction models, with applications in areas like augmented reality, scene understanding, and 3D design.
Technical Explanation
The default approach for training large reconstruction models (LRMs) has been to use fully supervised training on large datasets of synthetic 3D assets or multi-view captures of real-world objects. While effective, these datasets are difficult to scale beyond their current size and may not accurately represent the true distribution of object shapes.
To address these limitations, the Real3D system introduces a self-training framework that can leverage both existing synthetic data and diverse single-view real-world images. This is achieved through two novel unsupervised loss functions:
- A pixel-level loss that focuses on accurately reconstructing the fine-grained details of the input image, without requiring 3D ground truth.
- A semantic-level loss that aims to ensure the generated 3D model captures the overall structure and shape of the object, even when 3D data is unavailable.
To further improve performance and scale the training data, Real3D also includes an automatic data curation system. This tool identifies high-quality, representative examples from a large pool of in-the-wild images, which are then used to train the LRM.
The authors evaluate Real3D on a variety of synthetic and real-world benchmarks, including both in-domain and out-of-domain shapes. The results show that Real3D consistently outperforms prior work, demonstrating the benefits of the self-training approach and the unsupervised losses.
Critical Analysis
The Real3D paper presents a promising approach to training large reconstruction models using single-view real-world images, rather than relying solely on synthetic data or multi-view captures. The self-training framework and unsupervised losses are innovative and appear to yield significant performance improvements over prior methods.
That said, the paper does not provide a comprehensive analysis of the limitations or failure cases of the Real3D system. For example, it would be helpful to understand the types of objects or scenes where the unsupervised losses are less effective, or the extent to which the automatic data curation system may introduce biases into the training data.
Additionally, the authors do not discuss the computational and memory requirements of Real3D compared to other LRM training approaches. As these models become increasingly complex, understanding the resource trade-offs will be an important consideration for real-world deployment.
Further research could also explore ways to incorporate additional sources of supervision, such as language-based 3D understanding or unified scene representations, to further improve the capabilities of large reconstruction models trained on single-view real-world data.
Conclusion
The Real3D system represents an important step forward in training large reconstruction models (LRMs) using single-view real-world images, rather than relying solely on synthetic data or multi-view captures. By introducing a self-training framework and novel unsupervised losses, the authors have shown that LRMs can be effectively trained on a much broader and more realistic range of object shapes.
This advance has the potential to significantly expand the applicability of 3D reconstruction technology, enabling more accurate and versatile models for a wide range of use cases, from augmented reality to scene understanding and 3D design. As the field of large-scale 3D reconstruction continues to evolve, the insights and techniques introduced in the Real3D paper will likely play an important role in driving further progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Real3D: Scaling Up Large Reconstruction Models with Real-World Images
Hanwen Jiang, Qixing Huang, Georgios Pavlakos
The default strategy for training single-view Large Reconstruction Models (LRMs) follows the fully supervised route using large-scale datasets of synthetic 3D assets or multi-view captures. Although these resources simplify the training procedure, they are hard to scale up beyond the existing datasets and they are not necessarily representative of the real distribution of object shapes. To address these limitations, in this paper, we introduce Real3D, the first LRM system that can be trained using single-view real-world images. Real3D introduces a novel self-training framework that can benefit from both the existing synthetic data and diverse single-view real images. We propose two unsupervised losses that allow us to supervise LRMs at the pixel- and semantic-level, even for training examples without ground-truth 3D or novel views. To further improve performance and scale up the image data, we develop an automatic data curation approach to collect high-quality examples from in-the-wild images. Our experiments show that Real3D consistently outperforms prior work in four diverse evaluation settings that include real and synthetic data, as well as both in-domain and out-of-domain shapes. Code and model can be found here: https://hwjiang1510.github.io/Real3D/
Read more6/13/2024

0
M-LRM: Multi-view Large Reconstruction Model
Mengfei Li, Xiaoxiao Long, Yixun Liang, Weiyu Li, Yuan Liu, Peng Li, Xiaowei Chi, Xingqun Qi, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo
Despite recent advancements in the Large Reconstruction Model (LRM) demonstrating impressive results, when extending its input from single image to multiple images, it exhibits inefficiencies, subpar geometric and texture quality, as well as slower convergence speed than expected. It is attributed to that, LRM formulates 3D reconstruction as a naive images-to-3D translation problem, ignoring the strong 3D coherence among the input images. In this paper, we propose a Multi-view Large Reconstruction Model (M-LRM) designed to efficiently reconstruct high-quality 3D shapes from multi-views in a 3D-aware manner. Specifically, we introduce a multi-view consistent cross-attention scheme to enable M-LRM to accurately query information from the input images. Moreover, we employ the 3D priors of the input multi-view images to initialize the tri-plane tokens. Compared to LRM, the proposed M-LRM can produce a tri-plane NeRF with $128 times 128$ resolution and generate 3D shapes of high fidelity. Experimental studies demonstrate that our model achieves a significant performance gain and faster training convergence than LRM. Project page: https://murphylmf.github.io/M-LRM/
Read more6/13/2024
0
LRM-Zero: Training Large Reconstruction Models with Synthesized Data
Desai Xie, Sai Bi, Zhixin Shu, Kai Zhang, Zexiang Xu, Yi Zhou, Soren Pirk, Arie Kaufman, Xin Sun, Hao Tan
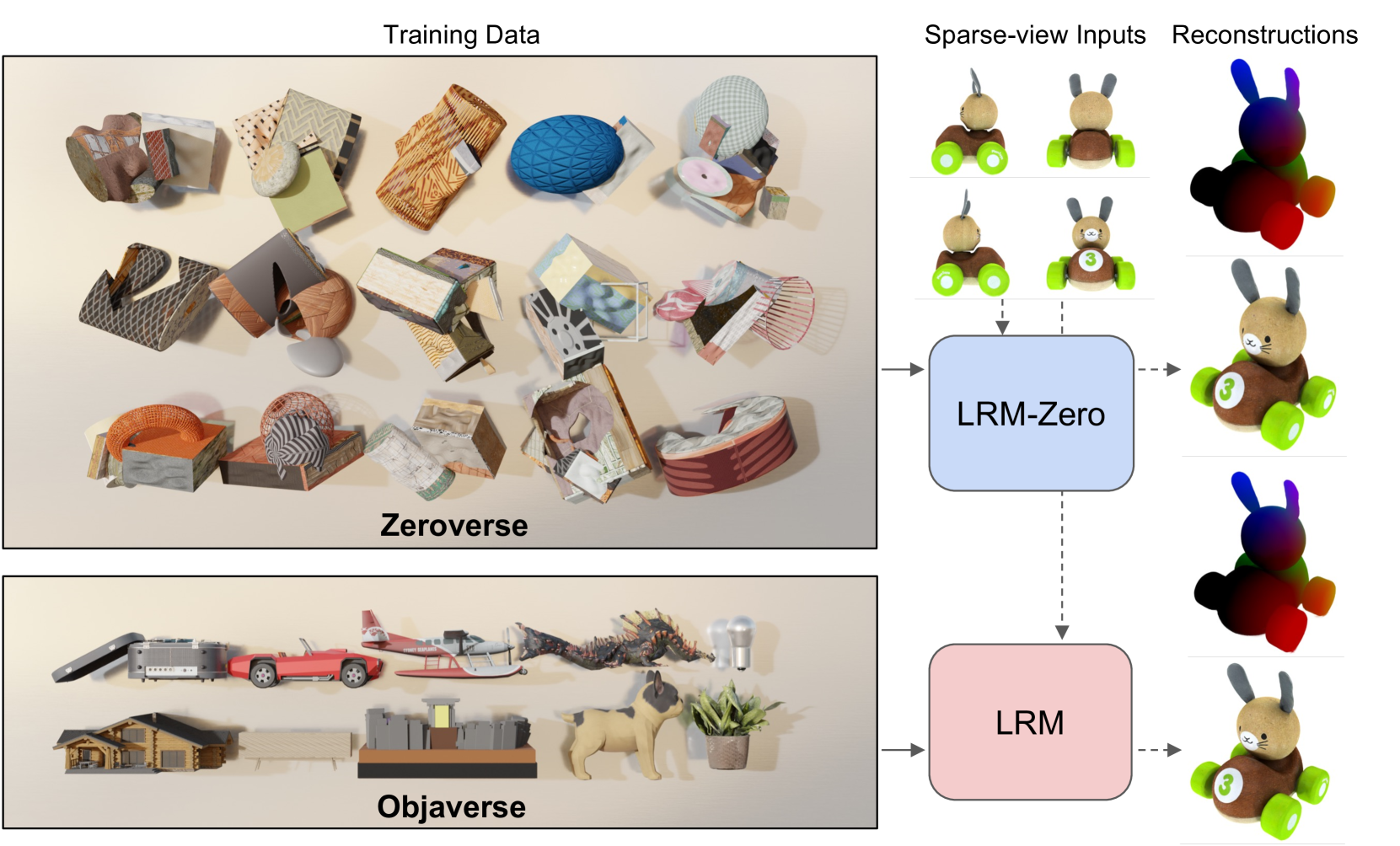
We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.
Read more6/14/2024
0
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
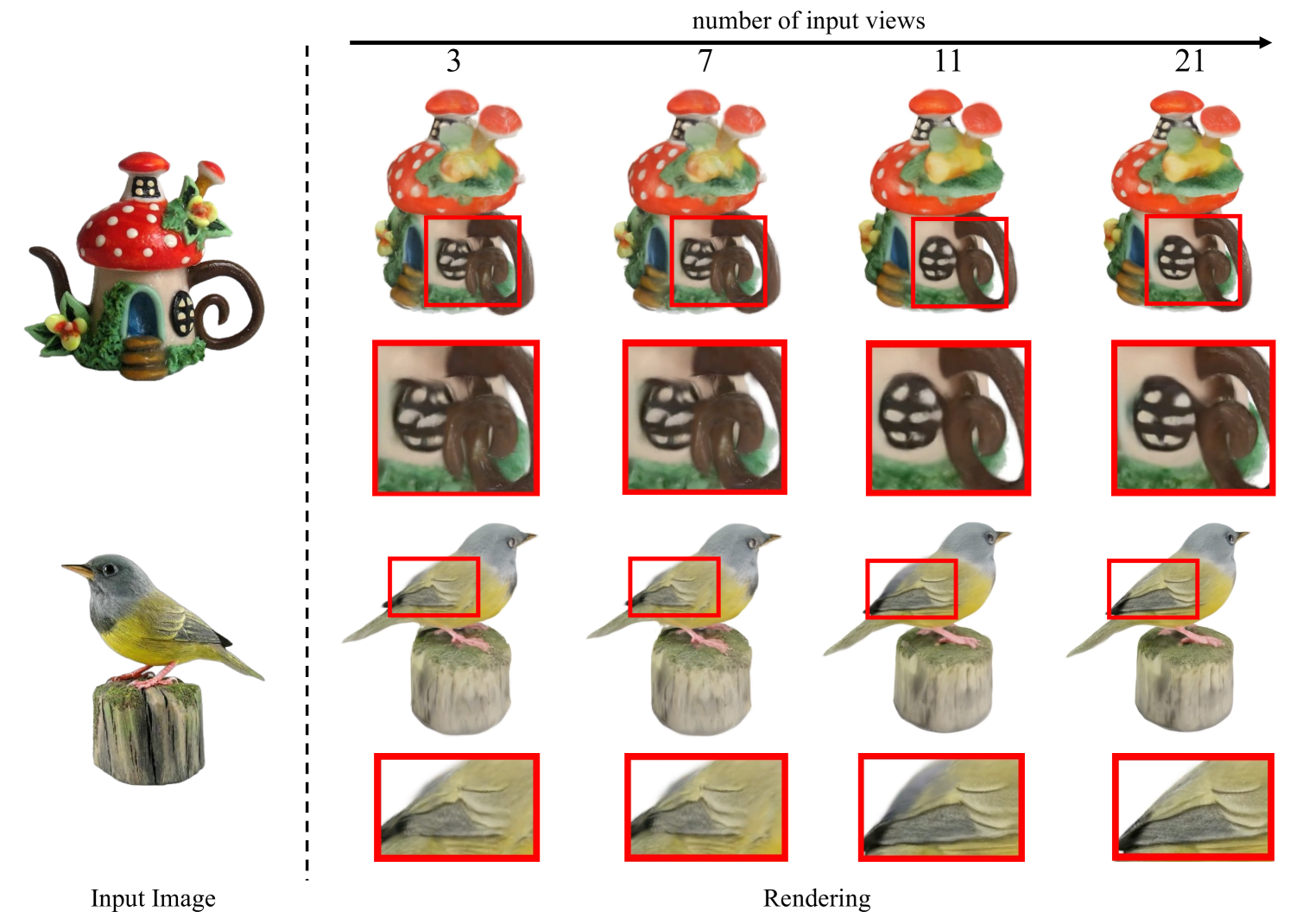
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
Read more6/24/2024