LancBiO: dynamic Lanczos-aided bilevel optimization via Krylov subspace
2404.03331
0
0
🛠️
Abstract
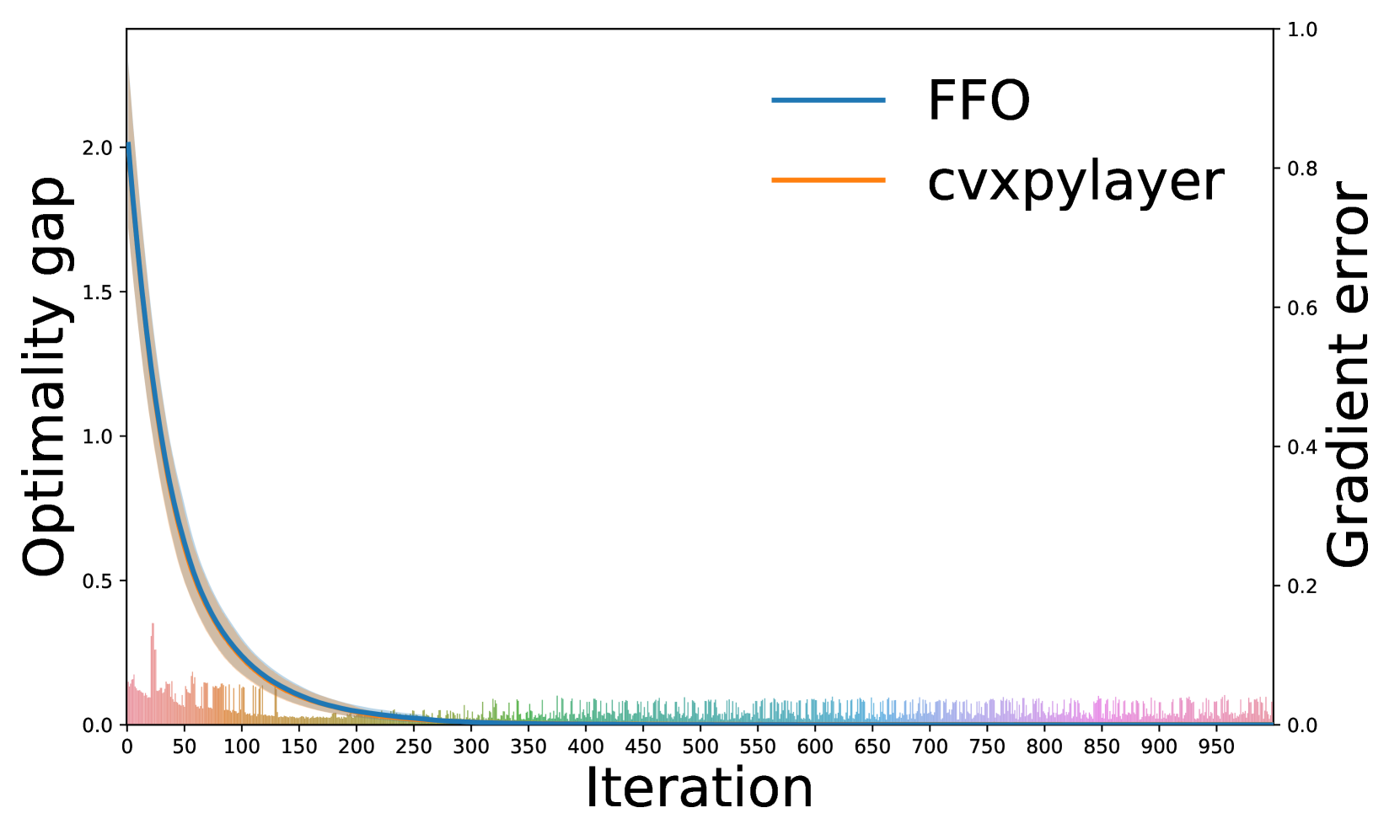
Bilevel optimization, with broad applications in machine learning, has an intricate hierarchical structure. Gradient-based methods have emerged as a common approach to large-scale bilevel problems. However, the computation of the hyper-gradient, which involves a Hessian inverse vector product, confines the efficiency and is regarded as a bottleneck. To circumvent the inverse, we construct a sequence of low-dimensional approximate Krylov subspaces with the aid of the Lanczos process. As a result, the constructed subspace is able to dynamically and incrementally approximate the Hessian inverse vector product with less effort and thus leads to a favorable estimate of the hyper-gradient. Moreover, we propose a~provable subspace-based framework for bilevel problems where one central step is to solve a small-size tridiagonal linear system. To the best of our knowledge, this is the first time that subspace techniques are incorporated into bilevel optimization. This successful trial not only enjoys $mathcal{O}(epsilon^{-1})$ convergence rate but also demonstrates efficiency in a synthetic problem and two deep learning tasks.
Create account to get full access
Overview
- Bilevel optimization is a complex hierarchical optimization problem with broad applications in machine learning.
- Gradient-based methods are commonly used to solve large-scale bilevel problems, but the computation of the hyper-gradient, which involves a Hessian inverse vector product, is a bottleneck.
- To address this issue, the paper proposes a subspace-based framework that constructs a sequence of low-dimensional approximate Krylov subspaces using the Lanczos process to dynamically and incrementally approximate the Hessian inverse vector product.
- The proposed approach demonstrates a favorable convergence rate and efficiency in synthetic and deep learning tasks.
Plain English Explanation
Bilevel optimization is a type of complex mathematical problem that has many applications in machine learning. In these problems, there is a hierarchy where one optimization problem is nested inside another. Gradient-based methods are commonly used to solve large-scale bilevel problems, but a key step called the "hyper-gradient" calculation is computationally intensive because it requires inverting a matrix.
To make this step more efficient, the researchers in this paper used a technique called the "Lanczos process" to construct a sequence of smaller, simpler subspaces that can approximate the matrix inverse. This allows them to estimate the hyper-gradient without directly inverting the matrix, which is much faster. They show that their subspace-based approach not only has strong theoretical guarantees, but also works well in practice on synthetic problems and deep learning tasks.
Technical Explanation
The paper proposes a subspace-based framework for solving bilevel optimization problems. Bilevel optimization has a hierarchical structure, where an "upper-level" optimization problem is constrained by the solution of a "lower-level" optimization problem. Gradient-based methods are commonly used to solve large-scale bilevel problems, but the computation of the "hyper-gradient" - which involves a Hessian inverse vector product - is a bottleneck.
To address this issue, the authors construct a sequence of low-dimensional approximate Krylov subspaces using the Lanczos process. This allows them to dynamically and incrementally approximate the Hessian inverse vector product with less computational effort, leading to a more efficient estimate of the hyper-gradient. Crucially, the key step in their approach is to solve a small-size tridiagonal linear system, rather than directly inverting the full Hessian matrix.
The paper provides a provable subspace-based framework for bilevel optimization that enjoys an O(ε^-1) convergence rate. The authors demonstrate the effectiveness of their approach on a synthetic problem and two deep learning tasks, showing that it outperforms existing methods in terms of efficiency.
Critical Analysis
The paper presents a novel subspace-based approach to bilevel optimization, which is an important and challenging problem with widespread applications in machine learning. The use of Krylov subspaces and the Lanczos process to approximate the Hessian inverse vector product is a clever and principled solution to the computational bottleneck in gradient-based bilevel optimization methods.
One potential limitation of the approach is that it may still require substantial computational resources, especially for large-scale problems, as the construction of the Krylov subspaces can be costly. Additionally, the authors do not provide a comprehensive comparison to other state-of-the-art bilevel optimization methods, which makes it difficult to assess the relative performance of their approach.
Furthermore, the paper does not delve into the potential limitations or failure modes of the subspace-based framework. It would be valuable to understand the types of bilevel problems for which this approach is most suitable, as well as any scenarios where it may struggle or perform poorly.
Despite these minor caveats, the paper represents an important contribution to the field of bilevel optimization. The authors' innovative use of subspace techniques is a promising direction for improving the efficiency and scalability of gradient-based methods in this domain. Readers are encouraged to think critically about the potential implications and limitations of this research, and to explore further developments in this area.
Conclusion
This paper presents a novel subspace-based framework for solving bilevel optimization problems, which are important in machine learning and have a complex hierarchical structure. The key innovation is the use of Krylov subspaces and the Lanczos process to efficiently approximate the Hessian inverse vector product, a computationally intensive step in gradient-based bilevel optimization methods.
The authors demonstrate that their approach enjoys strong theoretical guarantees and outperforms existing methods in terms of efficiency on synthetic and deep learning tasks. This work represents an important advancement in bilevel optimization and could have significant implications for a wide range of machine learning applications that rely on this type of hierarchical optimization problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
A Single-Loop Algorithm for Decentralized Bilevel Optimization
Youran Dong, Shiqian Ma, Junfeng Yang, Chao Yin
0
0
Bilevel optimization has gained significant attention in recent years due to its broad applications in machine learning. This paper focuses on bilevel optimization in decentralized networks and proposes a novel single-loop algorithm for solving decentralized bilevel optimization with a strongly convex lower-level problem. Our approach is a fully single-loop method that approximates the hypergradient using only two matrix-vector multiplications per iteration. Importantly, our algorithm does not require any gradient heterogeneity assumption, distinguishing it from existing methods for decentralized bilevel optimization and federated bilevel optimization. Our analysis demonstrates that the proposed algorithm achieves the best-known convergence rate for bilevel optimization algorithms. We also present experimental results on hyperparameter optimization problems using both synthetic and MNIST datasets, which demonstrate the efficiency of our proposed algorithm.
4/24/2024

An Accelerated Gradient Method for Convex Smooth Simple Bilevel Optimization
Jincheng Cao, Ruichen Jiang, Erfan Yazdandoost Hamedani, Aryan Mokhtari
0
0
In this paper, we focus on simple bilevel optimization problems, where we minimize a convex smooth objective function over the optimal solution set of another convex smooth constrained optimization problem. We present a novel bilevel optimization method that locally approximates the solution set of the lower-level problem using a cutting plane approach and employs an accelerated gradient-based update to reduce the upper-level objective function over the approximated solution set. We measure the performance of our method in terms of suboptimality and infeasibility errors and provide non-asymptotic convergence guarantees for both error criteria. Specifically, when the feasible set is compact, we show that our method requires at most $mathcal{O}(max{1/sqrt{epsilon_{f}}, 1/epsilon_g})$ iterations to find a solution that is $epsilon_f$-suboptimal and $epsilon_g$-infeasible. Moreover, under the additional assumption that the lower-level objective satisfies the $r$-th Holderian error bound, we show that our method achieves an iteration complexity of $mathcal{O}(max{epsilon_{f}^{-frac{2r-1}{2r}},epsilon_{g}^{-frac{2r-1}{2r}}})$, which matches the optimal complexity of single-level convex constrained optimization when $r=1$.
6/3/2024
First-Order Methods for Linearly Constrained Bilevel Optimization
Guy Kornowski, Swati Padmanabhan, Kai Wang, Zhe Zhang, Suvrit Sra
0
0
Algorithms for bilevel optimization often encounter Hessian computations, which are prohibitive in high dimensions. While recent works offer first-order methods for unconstrained bilevel problems, the constrained setting remains relatively underexplored. We present first-order linearly constrained optimization methods with finite-time hypergradient stationarity guarantees. For linear equality constraints, we attain $epsilon$-stationarity in $widetilde{O}(epsilon^{-2})$ gradient oracle calls, which is nearly-optimal. For linear inequality constraints, we attain $(delta,epsilon)$-Goldstein stationarity in $widetilde{O}(d{delta^{-1} epsilon^{-3}})$ gradient oracle calls, where $d$ is the upper-level dimension. Finally, we obtain for the linear inequality setting dimension-free rates of $widetilde{O}({delta^{-1} epsilon^{-4}})$ oracle complexity under the additional assumption of oracle access to the optimal dual variable. Along the way, we develop new nonsmooth nonconvex optimization methods with inexact oracles. We verify these guarantees with preliminary numerical experiments.
6/19/2024
🛠️
An adaptively inexact first-order method for bilevel optimization with application to hyperparameter learning
Mohammad Sadegh Salehi, Subhadip Mukherjee, Lindon Roberts, Matthias J. Ehrhardt
0
0
Various tasks in data science are modeled utilizing the variational regularization approach, where manually selecting regularization parameters presents a challenge. The difficulty gets exacerbated when employing regularizers involving a large number of hyperparameters. To overcome this challenge, bilevel learning can be employed to learn such parameters from data. However, neither exact function values nor exact gradients with respect to the hyperparameters are attainable, necessitating methods that only rely on inexact evaluation of such quantities. State-of-the-art inexact gradient-based methods a priori select a sequence of the required accuracies and cannot identify an appropriate step size since the Lipschitz constant of the hypergradient is unknown. In this work, we propose an algorithm with backtracking line search that only relies on inexact function evaluations and hypergradients and show convergence to a stationary point. Furthermore, the proposed algorithm determines the required accuracy dynamically rather than manually selected before running it. Our numerical experiments demonstrate the efficiency and feasibility of our approach for hyperparameter estimation on a range of relevant problems in imaging and data science such as total variation and field of experts denoising and multinomial logistic regression. Particularly, the results show that the algorithm is robust to its own hyperparameters such as the initial accuracies and step size.
4/12/2024