Language-guided Detection and Mitigation of Unknown Dataset Bias
2406.02889
0
0
Abstract
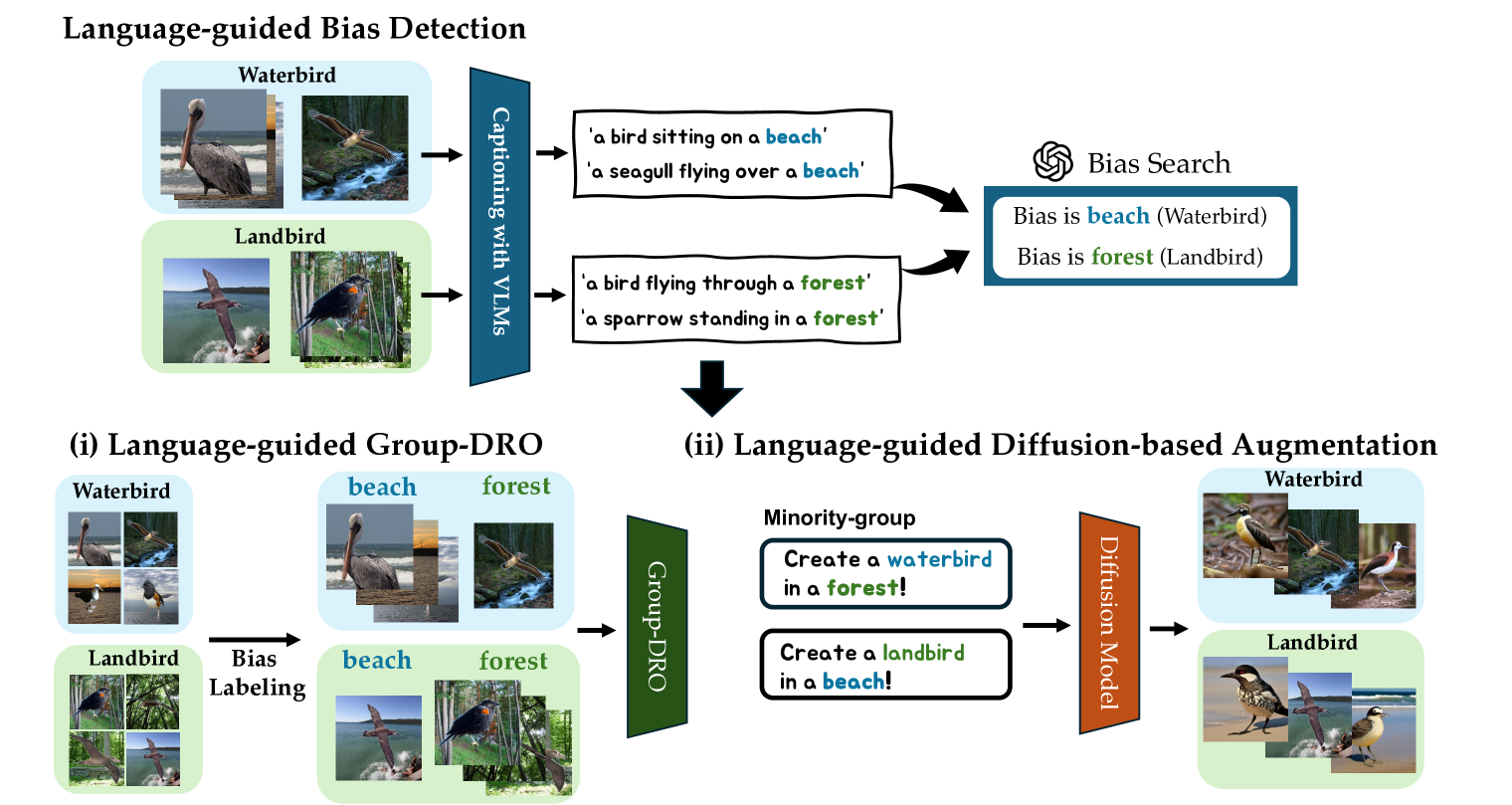
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Create account to get full access
Overview
- This paper presents a method for detecting and mitigating unknown dataset biases using language guidance.
- The approach leverages language models to identify biases in datasets that may not be obvious from the data alone.
- The researchers then use this language-guided bias detection to inform the development of mitigation strategies, helping to create more balanced and fair machine learning models.
- The paper explores the effectiveness of this language-guided approach on various real-world datasets and tasks.
Plain English Explanation
Machine learning models are often trained on datasets that contain hidden biases, which can lead to unfair or inaccurate predictions. Analyzing Mitigating Bias in Vulnerable Classes Towards Balanced and Are Bias Mitigation Techniques in Deep Learning Effective? have explored this issue and proposed ways to address it.
This paper introduces a new approach that uses language models to identify biases in datasets that may not be obvious from the data itself. The researchers start by training a language model on the dataset. They then use this model to analyze the language used to describe the dataset and identify any biases or imbalances.
For example, the language model might notice that certain groups or concepts are described using more negative or stereotypical language. This could indicate that the dataset contains biases against those groups, even if the data itself doesn't explicitly show this.
Once the language-guided bias detection has identified these issues, the researchers use that information to develop strategies for mitigating the biases. This might involve techniques like Model-Agnostic Data Attribution or Epistemic Uncertainty-Weighted Loss to rebalance the dataset or adjust the model training process.
The paper demonstrates the effectiveness of this language-guided approach on several real-world datasets and tasks, showing how it can help create more balanced and fair machine learning models. This is an important step towards OpenBias: Open-Set Bias Detection in Text, which aims to build systems that are more robust to hidden biases.
Technical Explanation
The researchers start by training a language model on the dataset they want to analyze. They then use this language model to identify biases in the dataset by examining the language used to describe the data.
Specifically, the researchers use the language model to generate embeddings for each data point in the dataset. They then analyze the distribution of these embeddings to identify any clusters or patterns that may indicate biases. For example, if certain groups or concepts are consistently described using more negative or stereotypical language, this could suggest that the dataset contains biases against those groups.
Once the language-guided bias detection has identified these issues, the researchers use that information to develop strategies for mitigating the biases. This might involve techniques like Model-Agnostic Data Attribution, which assigns higher weights to data points that are underrepresented in the training set, or Epistemic Uncertainty-Weighted Loss, which adjusts the model training process to focus more on underrepresented groups.
The researchers evaluate the effectiveness of their language-guided approach on several real-world datasets and tasks, including image classification and natural language processing. They show that their method is able to identify biases that were not evident from the data alone, and that the resulting mitigation strategies can lead to more balanced and fair machine learning models.
Critical Analysis
The paper presents a novel and promising approach for detecting and mitigating dataset biases using language guidance. By leveraging language models to analyze the language used to describe the data, the researchers are able to identify biases that may not be obvious from the data itself.
One potential limitation of the approach is that it relies on the language model being able to accurately capture the nuances and connotations of the language used to describe the dataset. If the language model has its own biases or limitations, this could impact the effectiveness of the bias detection process.
Additionally, while the paper demonstrates the effectiveness of the language-guided approach on several real-world datasets and tasks, it would be valuable to see how the method performs on an even wider range of datasets and applications. This could help establish the generalizability and robustness of the approach.
Overall, the paper makes a valuable contribution to the field of bias detection and mitigation in machine learning. The language-guided approach offers a promising new tool for identifying and addressing hidden biases in datasets, which is an important step towards building more fair and equitable AI systems.
Conclusion
This paper presents a novel method for detecting and mitigating unknown dataset biases using language guidance. By leveraging language models to analyze the language used to describe the data, the researchers are able to identify biases that may not be evident from the data alone.
The researchers then use this language-guided bias detection to inform the development of mitigation strategies, helping to create more balanced and fair machine learning models. The paper demonstrates the effectiveness of this approach on various real-world datasets and tasks, and offers a valuable contribution to the field of bias detection and mitigation in AI.
As the use of machine learning systems becomes more widespread, it is crucial that we develop effective techniques for identifying and addressing hidden biases in the data and models we use. The language-guided approach presented in this paper represents an important step towards this goal, and could have significant implications for the development of more equitable and inclusive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Mitigating Bias Using Model-Agnostic Data Attribution
Sander De Coninck, Wei-Cheng Wang, Sam Leroux, Pieter Simoens
0
0
Mitigating bias in machine learning models is a critical endeavor for ensuring fairness and equity. In this paper, we propose a novel approach to address bias by leveraging pixel image attributions to identify and regularize regions of images containing significant information about bias attributes. Our method utilizes a model-agnostic approach to extract pixel attributions by employing a convolutional neural network (CNN) classifier trained on small image patches. By training the classifier to predict a property of the entire image using only a single patch, we achieve region-based attributions that provide insights into the distribution of important information across the image. We propose utilizing these attributions to introduce targeted noise into datasets with confounding attributes that bias the data, thereby constraining neural networks from learning these biases and emphasizing the primary attributes. Our approach demonstrates its efficacy in enabling the training of unbiased classifiers on heavily biased datasets.
5/9/2024
🤿
Are Bias Mitigation Techniques for Deep Learning Effective?
Robik Shrestha, Kushal Kafle, Christopher Kanan
0
0
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
4/24/2024

Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset
Dewant Katare, David Solans Noguero, Souneil Park, Nicolas Kourtellis, Marijn Janssen, Aaron Yi Ding
0
0
The accuracy and fairness of perception systems in autonomous driving are essential, especially for vulnerable road users such as cyclists, pedestrians, and motorcyclists who face significant risks in urban driving environments. While mainstream research primarily enhances class performance metrics, the hidden traits of bias inheritance in the AI models, class imbalances and disparities within the datasets are often overlooked. Our research addresses these issues by investigating class imbalances among vulnerable road users, with a focus on analyzing class distribution, evaluating performance, and assessing bias impact. Utilizing popular CNN models and Vision Transformers (ViTs) with the nuScenes dataset, our performance evaluation indicates detection disparities for underrepresented classes. Compared to related work, we focus on metric-specific and Cost-Sensitive learning for model optimization and bias mitigation, which includes data augmentation and resampling. Using the proposed mitigation approaches, we see improvement in IoU(%) and NDS(%) metrics from 71.3 to 75.6 and 80.6 to 83.7 for the CNN model. Similarly, for ViT, we observe improvement in IoU and NDS metrics from 74.9 to 79.2 and 83.8 to 87.1. This research contributes to developing reliable models while enhancing inclusiveness for minority classes in datasets.
5/14/2024

Latent Directions: A Simple Pathway to Bias Mitigation in Generative AI
Carolina Lopez Olmos, Alexandros Neophytou, Sunando Sengupta, Dim P. Papadopoulos
0
0
Mitigating biases in generative AI and, particularly in text-to-image models, is of high importance given their growing implications in society. The biased datasets used for training pose challenges in ensuring the responsible development of these models, and mitigation through hard prompting or embedding alteration, are the most common present solutions. Our work introduces a novel approach to achieve diverse and inclusive synthetic images by learning a direction in the latent space and solely modifying the initial Gaussian noise provided for the diffusion process. Maintaining a neutral prompt and untouched embeddings, this approach successfully adapts to diverse debiasing scenarios, such as geographical biases. Moreover, our work proves it is possible to linearly combine these learned latent directions to introduce new mitigations, and if desired, integrate it with text embedding adjustments. Furthermore, text-to-image models lack transparency for assessing bias in outputs, unless visually inspected. Thus, we provide a tool to empower developers to select their desired concepts to mitigate. The project page with code is available online.
6/11/2024