Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset

0

Sign in to get full access
Overview
- This research paper analyzes and mitigates bias in datasets to improve balanced representation of vulnerable classes.
- The authors develop techniques to identify and reduce biases in datasets, leading to more fair and inclusive machine learning models.
- The paper explores methods for assessing dataset bias, including measuring representation and performance disparities across different subgroups.
- It also proposes strategies for mitigating these biases, such as targeted data collection and augmentation.
Plain English Explanation
Machine learning models can sometimes reflect and amplify the biases present in the data they are trained on. This can lead to unfair and discriminatory outcomes, especially for vulnerable or underrepresented groups.
The researchers in this paper set out to address this challenge by developing techniques to analyze and mitigate biases in datasets. Their goal was to create more balanced and inclusive datasets that would lead to fairer machine learning models.
They started by looking at ways to measure dataset bias, such as comparing the representation and performance of different demographic groups. For example, is a facial recognition model performing equally well across races and genders?
Once they had identified biases, the researchers tested various mitigation strategies, like targeted data collection and augmentation. The idea was to boost the representation of underrepresented groups in the dataset, so the final model would not discriminate.
By focusing on dataset fairness, this work aims to make machine learning systems more equitable and inclusive, rather than perpetuating societal biases. Techniques like these are an important step towards ensuring AI models are fair and unbiased.
Technical Explanation
The paper first outlines a framework for assessing dataset bias, which involves measuring representation and performance disparities across different subgroups. This includes metrics like demographic parity, which looks at the relative size of each group in the dataset, and equal opportunity, which compares the true positive rates.
The authors then propose several bias mitigation techniques. One approach is targeted data collection, where additional data is obtained for underrepresented groups to improve their coverage. Another method is data augmentation, which synthetically generates new examples to balance the dataset.
The researchers evaluate their techniques on several benchmark datasets, including CelebA and Autonomous Driving. They demonstrate that their methods can significantly reduce demographic disparities and improve model fairness, as measured by metrics like FairVIC and Distribution-Aware Fairness.
Critical Analysis
The paper presents a thorough and systematic approach to addressing dataset bias, which is a crucial issue for developing fair and inclusive AI systems. The proposed techniques for assessing and mitigating biases appear well-designed and the experimental results are promising.
However, the authors acknowledge that their methods are not a panacea. Achieving truly balanced representation in datasets can be challenging, especially for rare or highly heterogeneous subgroups. There may also be inherent difficulties in defining and measuring fairness that the paper does not fully grapple with.
Additionally, the paper focuses mainly on demographic biases (e.g. race, gender), while other types of bias, such as those related to socioeconomic status or disability, are not explored in depth. Future work could investigate a broader range of biases and how to address them in a comprehensive way.
Overall, this research represents an important step forward in the quest for fair and equitable machine learning. By making datasets more balanced and representative, we can work towards AI systems that are inclusive and beneficial for all members of society.
Conclusion
This paper tackles the critical problem of bias in machine learning datasets. The authors develop robust techniques for assessing and mitigating dataset biases, with the goal of creating more balanced and representative training data.
Their methods demonstrate significant improvements in fairness metrics across multiple benchmark datasets, suggesting these approaches could be valuable tools for building inclusive AI systems. While not a complete solution, this research advances our understanding of how to identify and address dataset biases - a crucial challenge as machine learning becomes more pervasive in high-stakes domains.
Ultimately, this work highlights the importance of thoughtful data curation and the need to proactively consider fairness and representation when developing AI models. By focusing on dataset-level biases, the authors pave the way for machine learning that is more equitable and beneficial for all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset
Dewant Katare, David Solans Noguero, Souneil Park, Nicolas Kourtellis, Marijn Janssen, Aaron Yi Ding
The accuracy and fairness of perception systems in autonomous driving are essential, especially for vulnerable road users such as cyclists, pedestrians, and motorcyclists who face significant risks in urban driving environments. While mainstream research primarily enhances class performance metrics, the hidden traits of bias inheritance in the AI models, class imbalances and disparities within the datasets are often overlooked. Our research addresses these issues by investigating class imbalances among vulnerable road users, with a focus on analyzing class distribution, evaluating performance, and assessing bias impact. Utilizing popular CNN models and Vision Transformers (ViTs) with the nuScenes dataset, our performance evaluation indicates detection disparities for underrepresented classes. Compared to related work, we focus on metric-specific and Cost-Sensitive learning for model optimization and bias mitigation, which includes data augmentation and resampling. Using the proposed mitigation approaches, we see improvement in IoU(%) and NDS(%) metrics from 71.3 to 75.6 and 80.6 to 83.7 for the CNN model. Similarly, for ViT, we observe improvement in IoU and NDS metrics from 74.9 to 79.2 and 83.8 to 87.1. This research contributes to developing reliable models while enhancing inclusiveness for minority classes in datasets.
Read more5/14/2024
0
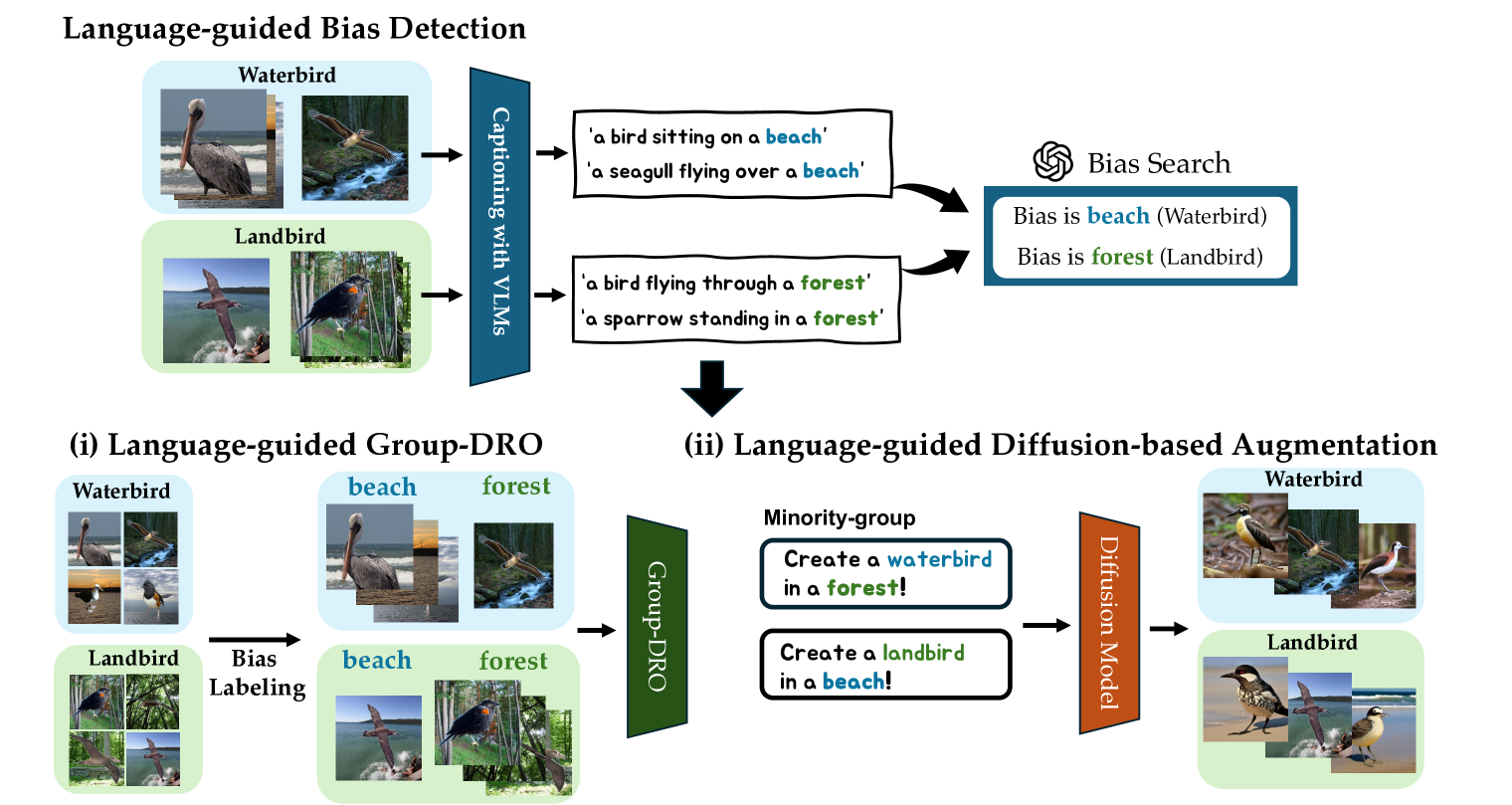
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024
🤿
0
Are Bias Mitigation Techniques for Deep Learning Effective?
Robik Shrestha, Kushal Kafle, Christopher Kanan
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
Read more4/24/2024

0
ViG-Bias: Visually Grounded Bias Discovery and Mitigation
Badr-Eddine Marani, Mohamed Hanini, Nihitha Malayarukil, Stergios Christodoulidis, Maria Vakalopoulou, Enzo Ferrante
The proliferation of machine learning models in critical decision making processes has underscored the need for bias discovery and mitigation strategies. Identifying the reasons behind a biased system is not straightforward, since in many occasions they are associated with hidden spurious correlations which are not easy to spot. Standard approaches rely on bias audits performed by analyzing model performance in pre-defined subgroups of data samples, usually characterized by common attributes like gender or ethnicity when it comes to people, or other specific attributes defining semantically coherent groups of images. However, it is not always possible to know a-priori the specific attributes defining the failure modes of visual recognition systems. Recent approaches propose to discover these groups by leveraging large vision language models, which enable the extraction of cross-modal embeddings and the generation of textual descriptions to characterize the subgroups where a certain model is underperforming. In this work, we argue that incorporating visual explanations (e.g. heatmaps generated via GradCAM or other approaches) can boost the performance of such bias discovery and mitigation frameworks. To this end, we introduce Visually Grounded Bias Discovery and Mitigation (ViG-Bias), a simple yet effective technique which can be integrated to a variety of existing frameworks to improve both, discovery and mitigation performance. Our comprehensive evaluation shows that incorporating visual explanations enhances existing techniques like DOMINO, FACTS and Bias-to-Text, across several challenging datasets, including CelebA, Waterbirds, and NICO++.
Read more7/4/2024