Latent Directions: A Simple Pathway to Bias Mitigation in Generative AI
2406.06352
0
0

Abstract
Mitigating biases in generative AI and, particularly in text-to-image models, is of high importance given their growing implications in society. The biased datasets used for training pose challenges in ensuring the responsible development of these models, and mitigation through hard prompting or embedding alteration, are the most common present solutions. Our work introduces a novel approach to achieve diverse and inclusive synthetic images by learning a direction in the latent space and solely modifying the initial Gaussian noise provided for the diffusion process. Maintaining a neutral prompt and untouched embeddings, this approach successfully adapts to diverse debiasing scenarios, such as geographical biases. Moreover, our work proves it is possible to linearly combine these learned latent directions to introduce new mitigations, and if desired, integrate it with text embedding adjustments. Furthermore, text-to-image models lack transparency for assessing bias in outputs, unless visually inspected. Thus, we provide a tool to empower developers to select their desired concepts to mitigate. The project page with code is available online.
Create account to get full access
Overview
- The paper proposes a simple method called "Latent Directions" to mitigate bias in generative AI models.
- The method involves identifying and manipulating specific latent directions in the model's representation space that correspond to biased attributes.
- This allows for targeted debiasing without significantly impacting the model's overall performance or capabilities.
Plain English Explanation
Generative AI models, such as those used for text or image generation, can sometimes reflect and amplify societal biases present in their training data. This can lead to undesirable outputs that perpetuate harmful stereotypes or discriminate against certain groups.
The researchers behind this paper have developed a new approach called "Latent Directions" that aims to address this issue. The key idea is to identify specific directions in the model's internal representation space (the "latent space") that correspond to biased attributes, such as gender or race. By manipulating these latent directions, the researchers can effectively debias the model's outputs without significantly impacting its overall performance or capabilities.
This is a simpler and more targeted approach compared to previous methods that often required extensive retraining or complex architectural changes to the model.
The process involves three main steps:
- Identify Biased Latent Directions: The researchers use techniques like linear probing to pinpoint the latent directions in the model that are most strongly correlated with the biased attributes.
- Neutralize Biased Latent Directions: They then modify the model's latent representations to reduce the influence of these biased directions, essentially "debiasing" the model.
- Generate Debiased Outputs: With the biased latent directions neutralized, the model can then generate outputs that are less biased while still maintaining its overall performance.
This approach provides a straightforward and effective way to mitigate bias in generative AI models, which is an important step in making these technologies more fair and inclusive.
Technical Explanation
The paper introduces a novel method called "Latent Directions" for addressing bias in generative AI models. The key insight is that the internal representations (latent space) of these models often contain directions that are strongly correlated with biased attributes, such as gender or race.
To identify these biased latent directions, the researchers use linear probing techniques. Specifically, they train simple linear classifiers to predict the biased attributes from the model's latent representations. The directions that the classifiers find most useful for their predictions are then identified as the "biased latent directions."
Next, the researchers neutralize the influence of these biased latent directions by modifying the model's latent representations. This is done by projecting the latent vectors onto the subspace orthogonal to the biased directions, effectively reducing the model's sensitivity to these biased attributes.
Finally, the researchers generate outputs using the debiased latent representations, which results in outputs that are less biased while still maintaining the model's overall performance. This approach is demonstrated on various generative tasks, such as text-to-image generation and image inpainting, showing significant reductions in biased outputs without major sacrifices in model quality.
Critical Analysis
The Latent Directions method presented in this paper offers a promising and relatively simple approach to mitigating bias in generative AI models. By focusing on the internal representations of the model, rather than applying more complex architectural changes or extensive retraining, the researchers have developed a targeted solution that can be more easily integrated into existing systems.
However, the paper does acknowledge some limitations and areas for further research. For example, the method may be less effective for biases that are more deeply encoded in the model's representations, or for cases where the biases are more complex and multidimensional. Additionally, the researchers note that their approach does not address the issue of dataset bias, which can also be a significant source of bias in generative models.
It would be valuable to see further exploration of how this method compares to other debiasing techniques, such as those that focus on dataset curation or architectural modifications. Additionally, investigating the impact of this method on different types of bias, beyond just gender and race, could provide important insights.
Overall, the Latent Directions method represents a significant step forward in addressing bias in generative AI, and the simplicity and effectiveness of the approach make it a promising direction for further research and real-world application.
Conclusion
The paper "Latent Directions: A Simple Pathway to Bias Mitigation in Generative AI" introduces a novel and straightforward method for mitigating bias in generative AI models. By identifying and manipulating the specific latent directions in the model's internal representation space that correspond to biased attributes, the researchers have developed a targeted debiasing approach that can be implemented without major changes to the model's architecture or extensive retraining.
This work represents an important contribution to the ongoing efforts to make generative AI systems more fair and inclusive, addressing a critical challenge in the field. While the method has some limitations, the simplicity and effectiveness of the Latent Directions approach make it a promising direction for further research and real-world application in the development of more responsible and ethical AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Would Deep Generative Models Amplify Bias in Future Models?
Tianwei Chen, Yusuke Hirota, Mayu Otani, Noa Garcia, Yuta Nakashima
0
0
We investigate the impact of deep generative models on potential social biases in upcoming computer vision models. As the internet witnesses an increasing influx of AI-generated images, concerns arise regarding inherent biases that may accompany them, potentially leading to the dissemination of harmful content. This paper explores whether a detrimental feedback loop, resulting in bias amplification, would occur if generated images were used as the training data for future models. We conduct simulations by progressively substituting original images in COCO and CC3M datasets with images generated through Stable Diffusion. The modified datasets are used to train OpenCLIP and image captioning models, which we evaluate in terms of quality and bias. Contrary to expectations, our findings indicate that introducing generated images during training does not uniformly amplify bias. Instead, instances of bias mitigation across specific tasks are observed. We further explore the factors that may influence these phenomena, such as artifacts in image generation (e.g., blurry faces) or pre-existing biases in the original datasets.
4/5/2024
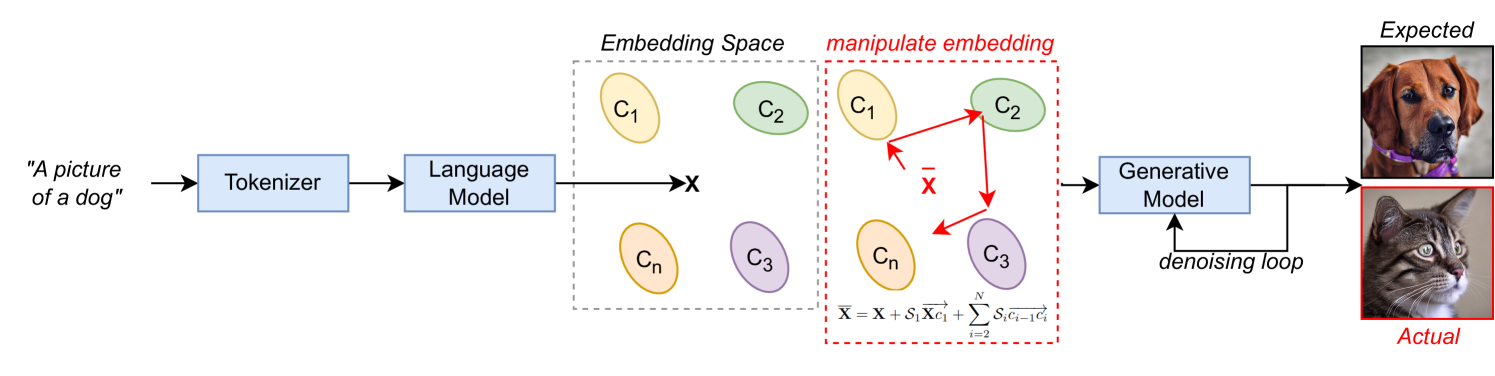
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
0
0
Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
4/4/2024

DiffInject: Revisiting Debias via Synthetic Data Generation using Diffusion-based Style Injection
Donggeun Ko, Sangwoo Jo, Dongjun Lee, Namjun Park, Jaekwang Kim
0
0
Dataset bias is a significant challenge in machine learning, where specific attributes, such as texture or color of the images are unintentionally learned resulting in detrimental performance. To address this, previous efforts have focused on debiasing models either by developing novel debiasing algorithms or by generating synthetic data to mitigate the prevalent dataset biases. However, generative approaches to date have largely relied on using bias-specific samples from the dataset, which are typically too scarce. In this work, we propose, DiffInject, a straightforward yet powerful method to augment synthetic bias-conflict samples using a pretrained diffusion model. This approach significantly advances the use of diffusion models for debiasing purposes by manipulating the latent space. Our framework does not require any explicit knowledge of the bias types or labelling, making it a fully unsupervised setting for debiasing. Our methodology demonstrates substantial result in effectively reducing dataset bias.
6/11/2024

Inpaint Biases: A Pathway to Accurate and Unbiased Image Generation
Jiyoon Myung, Jihyeon Park
0
0
This paper examines the limitations of advanced text-to-image models in accurately rendering unconventional concepts which are scarcely represented or absent in their training datasets. We identify how these limitations not only confine the creative potential of these models but also pose risks of reinforcing stereotypes. To address these challenges, we introduce the Inpaint Biases framework, which employs user-defined masks and inpainting techniques to enhance the accuracy of image generation, particularly for novel or inaccurately rendered objects. Through experimental validation, we demonstrate how this framework significantly improves the fidelity of generated images to the user's intent, thereby expanding the models' creative capabilities and mitigating the risk of perpetuating biases. Our study contributes to the advancement of text-to-image models as unbiased, versatile tools for creative expression.
5/31/2024