SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation

0
🤷
Sign in to get full access
Overview
- Transferring learning models from one dataset to another is a challenging task, especially for lidar data, which can exhibit significant performance differences due to changes in sensor patterns or acquisition conditions.
- This paper presents a novel unsupervised domain adaptation (UDA) technique for semantic segmentation that learns an implicit underlying surface representation to bridge the gap between source and target domains.
- The authors demonstrate that their method outperforms the current state of the art in both real-to-real and synthetic-to-real scenarios.
Plain English Explanation
Machine learning models trained on one dataset don't always work well when applied to a different dataset, even if the tasks are similar. This is a common problem, especially with lidar data, where changes in sensor technology or data collection conditions can cause significant performance drops.
The key insight of this paper is to have the model learn an abstract, underlying representation of the 3D surface being scanned, rather than just learning to map the raw lidar data to semantic labels. Since this surface representation should be the same regardless of the specific lidar data, it can help the model bridge the gap between the source and target domains.
This is a novel approach that differs from more traditional techniques like minimizing statistical differences between the domains. By forcing the model to learn this shared surface representation, it's able to better handle the discrepancies between the source and target lidar data, leading to improved performance when adapting to the new domain.
Technical Explanation
The paper tackles the unsupervised domain adaptation (UDA) problem for semantic segmentation of lidar data. To address the challenge of domain shift, the authors introduce an auxiliary task of learning an implicit underlying surface representation that is shared between the source and target domains.
The intuition is that by learning this shared latent representation, the model will be forced to accommodate the discrepancies between the two data sources, rather than just memorizing the mapping between the raw lidar data and semantic labels. This novel strategy differs from more traditional UDA techniques, such as minimizing statistical divergences or using lidar-specific domain adaptation methods.
The authors evaluate their approach on both real-to-real and synthetic-to-real adaptation scenarios, demonstrating that it outperforms the current state of the art in multi-target unsupervised domain adaptation for semantic segmentation.
Critical Analysis
The paper presents a compelling approach to the challenging problem of unsupervised domain adaptation for lidar-based semantic segmentation. By learning an implicit surface representation, the model is able to better bridge the gap between source and target domains, leading to improved performance.
However, the paper does not delve deeply into the specific reasons why this approach is successful. It would be interesting to see a more detailed analysis of how the learned surface representation helps the model overcome the domain shift, and whether this technique could be generalized to other types of sensor data beyond lidar.
Additionally, the authors only evaluate their method on a limited number of datasets and scenarios. Further research into unsupervised domain adaptation architecture search and self-training could help validate the broader applicability of this approach and identify any potential limitations or edge cases.
Conclusion
This paper presents a novel unsupervised domain adaptation technique for lidar-based semantic segmentation that learns an implicit underlying surface representation to bridge the gap between source and target domains. The authors demonstrate the effectiveness of this approach, which outperforms the current state of the art in both real-to-real and synthetic-to-real adaptation scenarios.
While further research is needed to fully understand the reasons for the method's success and explore its broader applicability, this work represents an important step forward in addressing the challenge of domain shift in machine learning, with potential implications for a wide range of sensing and perception tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
SALUDA: Surface-based Automotive Lidar Unsupervised Domain Adaptation
Bjorn Michele, Alexandre Boulch, Gilles Puy, Tuan-Hung Vu, Renaud Marlet, Nicolas Courty
Learning models on one labeled dataset that generalize well on another domain is a difficult task, as several shifts might happen between the data domains. This is notably the case for lidar data, for which models can exhibit large performance discrepancies due for instance to different lidar patterns or changes in acquisition conditions. This paper addresses the corresponding Unsupervised Domain Adaptation (UDA) task for semantic segmentation. To mitigate this problem, we introduce an unsupervised auxiliary task of learning an implicit underlying surface representation simultaneously on source and target data. As both domains share the same latent representation, the model is forced to accommodate discrepancies between the two sources of data. This novel strategy differs from classical minimization of statistical divergences or lidar-specific domain adaptation techniques. Our experiments demonstrate that our method achieves a better performance than the current state of the art, both in real-to-real and synthetic-to-real scenarios.
Read more6/27/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024
💬
0
Learning to Adapt SAM for Segmenting Cross-domain Point Clouds
Xidong Peng, Runnan Chen, Feng Qiao, Lingdong Kong, Youquan Liu, Yujing Sun, Tai Wang, Xinge Zhu, Yuexin Ma
Unsupervised domain adaptation (UDA) in 3D segmentation tasks presents a formidable challenge, primarily stemming from the sparse and unordered nature of point cloud data. Especially for LiDAR point clouds, the domain discrepancy becomes obvious across varying capture scenes, fluctuating weather conditions, and the diverse array of LiDAR devices in use. While previous UDA methodologies have often sought to mitigate this gap by aligning features between source and target domains, this approach falls short when applied to 3D segmentation due to the substantial domain variations. Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM's feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance.
Read more9/24/2024
0
Achieving Reliable and Fair Skin Lesion Diagnosis via Unsupervised Domain Adaptation
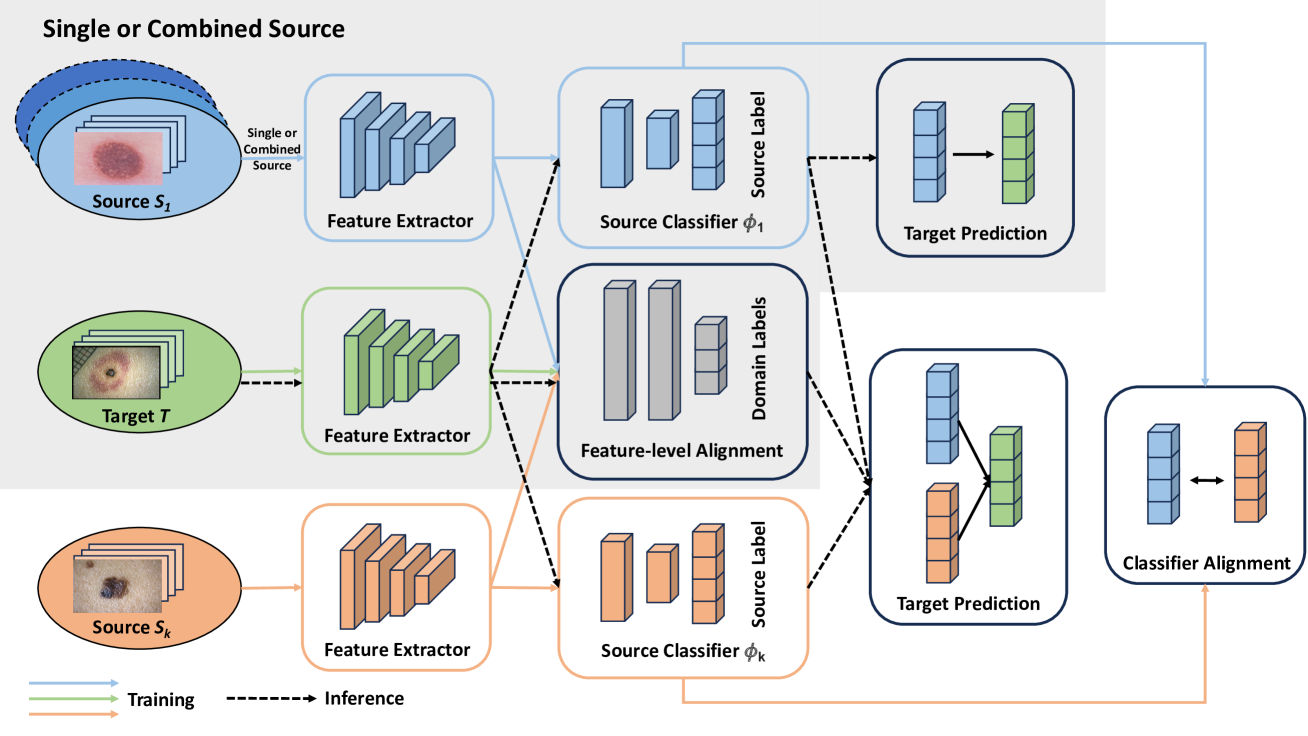
Janet Wang, Yunbei Zhang, Zhengming Ding, Jihun Hamm
The development of reliable and fair diagnostic systems is often constrained by the scarcity of labeled data. To address this challenge, our work explores the feasibility of unsupervised domain adaptation (UDA) to integrate large external datasets for developing reliable classifiers. The adoption of UDA with multiple sources can simultaneously enrich the training set and bridge the domain gap between different skin lesion datasets, which vary due to distinct acquisition protocols. Particularly, UDA shows practical promise for improving diagnostic reliability when training with a custom skin lesion dataset, where only limited labeled data are available from the target domain. In this study, we investigate three UDA training schemes based on source data utilization: single-source, combined-source, and multi-source UDA. Our findings demonstrate the effectiveness of applying UDA on multiple sources for binary and multi-class classification. A strong correlation between test error and label shift in multi-class tasks has been observed in the experiment. Crucially, our study shows that UDA can effectively mitigate bias against minority groups and enhance fairness in diagnostic systems, while maintaining superior classification performance. This is achieved even without directly implementing fairness-focused techniques. This success is potentially attributed to the increased and well-adapted demographic information obtained from multiple sources.
Read more4/17/2024