Language Model Prompt Selection via Simulation Optimization
2404.08164
0
0
Abstract
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new method for automatic prompt selection for large language models.
- The authors introduce a "plug-and-play prompts" approach for controlling the output of language models.
- They also introduce a benchmark called CSEPrompts for evaluating prompts for introductory computer science tasks.
- The paper describes an "adaptive framework" called NeuroPrompts for optimizing prompts for text generation.
- Finally, the paper explores a "code-aware prompting" technique that uses code coverage to guide prompt selection for testing language models.
Plain English Explanation
The researchers in this paper have developed several new methods to help control and improve the performance of large language models, which are AI systems trained on huge amounts of text data to generate human-like language.
One of their key ideas is Plug-and-Play Prompts, which allows users to easily customize the output of a language model by providing it with a brief "prompt" - a short piece of text that guides the model's generation. This makes language models more versatile and controllable.
The researchers also created a benchmark called CSEPrompts to test how well language models perform on introductory computer science tasks when given different prompts. This helps evaluate and improve the prompting capabilities of these models.
Another key contribution is NeuroPrompts, a system that can automatically optimize prompts to get the best possible text generation from a language model. This makes it easier to use these models effectively.
Finally, the paper explores "code-aware prompting", which uses information about computer code to help select the best prompts for testing and evaluating language models on programming-related tasks. This code-aware prompting technique aims to make these models more reliable for software development applications.
Overall, the researchers have developed several innovative ways to make large language models more controllable, customizable, and effective, which could have important implications for how these powerful AI systems are used in the real world.
Technical Explanation
The paper introduces a novel method called Automatic Prompt Selection for Large Language Models that aims to improve the performance and controllability of large language models.
The key contributions are:
-
Plug-and-Play Prompts: The authors propose a "prompt tuning" approach that allows users to easily customize the output of a language model by providing it with a short prompt - a brief piece of text that guides the model's generation. This makes language models more versatile and controllable.
-
CSEPrompts Benchmark: The researchers created a new benchmark called CSEPrompts to evaluate how well language models perform on introductory computer science tasks when given different prompts. This helps assess and improve the prompting capabilities of these models.
-
NeuroPrompts: The paper introduces NeuroPrompts, an adaptive framework that can automatically optimize prompts to get the best possible text generation from a language model. This makes it easier to use these models effectively.
-
Code-Aware Prompting: The researchers explore a technique called "code-aware prompting" that uses information about computer code to help select the best prompts for testing and evaluating language models on programming-related tasks. This aims to make these models more reliable for software development applications.
The paper describes experiments evaluating these different prompt-based techniques and demonstrates their ability to improve language model performance on a variety of tasks. The results suggest that prompt-based control of language models is a promising direction for making these powerful AI systems more useful and reliable.
Critical Analysis
The paper makes a number of valuable contributions to the field of large language model control and optimization. The introduction of plug-and-play prompts, the CSEPrompts benchmark, and the NeuroPrompts framework all represent innovative approaches to making language models more customizable and effective.
However, the paper does acknowledge some limitations. The CSEPrompts benchmark is focused solely on introductory computer science tasks, so its applicability to other domains may be limited. Additionally, the NeuroPrompts framework, while effective, still requires significant computational resources to optimize prompts, which could be a barrier to widespread adoption.
The exploration of code-aware prompting is particularly intriguing, as it attempts to leverage domain-specific knowledge (in this case, about computer code) to improve language model performance. However, the paper only provides a preliminary study of this technique, and more research would be needed to fully evaluate its potential.
Overall, this paper represents an important step forward in the quest to make large language models more controllable and reliable. The authors have developed several promising approaches that could have significant implications for how these powerful AI systems are deployed and used in real-world applications. As the field continues to evolve, it will be important to address the remaining limitations and explore even more innovative ways to harness the capabilities of large language models.
Conclusion
This paper presents several novel techniques for improving the performance and controllability of large language models. The researchers have developed methods like Plug-and-Play Prompts, the CSEPrompts benchmark, NeuroPrompts, and code-aware prompting that significantly enhance the customizability, effectiveness, and reliability of these powerful AI systems.
The implications of this work are far-reaching. By making language models more controllable and adaptable, the researchers are paving the way for their safe and responsible deployment in a wide range of real-world applications, from content generation to software development. As the field of large language models continues to evolve, this paper represents an important milestone in the ongoing effort to unlock their full potential while addressing key challenges around transparency, safety, and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Automatic Prompt Selection for Large Language Models
Viet-Tung Do, Van-Khanh Hoang, Duy-Hung Nguyen, Shahab Sabahi, Jeff Yang, Hajime Hotta, Minh-Tien Nguyen, Hung Le
0
0
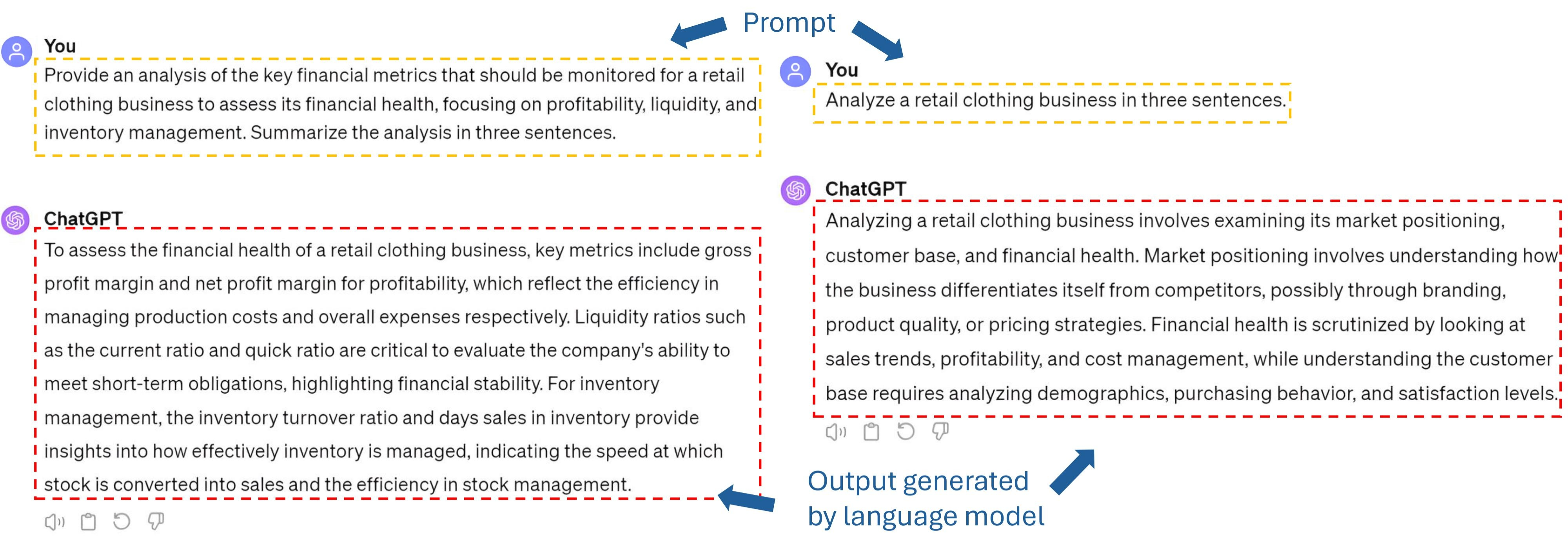
Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
4/4/2024
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Rohan Deepak Ajwani, Zining Zhu, Jonathan Rose, Frank Rudzicz
0
0
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
4/9/2024
📉
CSEPrompts: A Benchmark of Introductory Computer Science Prompts
Nishat Raihan, Dhiman Goswami, Sadiya Sayara Chowdhury Puspo, Christian Newman, Tharindu Ranasinghe, Marcos Zampieri
0
0
Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
4/5/2024
🏷️
Prompt Customization for Continual Learning
Yong Dai, Xiaopeng Hong, Yabin Wang, Zhiheng Ma, Dongmei Jiang, Yaowei Wang
0
0
Contemporary continual learning approaches typically select prompts from a pool, which function as supplementary inputs to a pre-trained model. However, this strategy is hindered by the inherent noise of its selection approach when handling increasing tasks. In response to these challenges, we reformulate the prompting approach for continual learning and propose the prompt customization (PC) method. PC mainly comprises a prompt generation module (PGM) and a prompt modulation module (PMM). In contrast to conventional methods that employ hard prompt selection, PGM assigns different coefficients to prompts from a fixed-sized pool of prompts and generates tailored prompts. Moreover, PMM further modulates the prompts by adaptively assigning weights according to the correlations between input data and corresponding prompts. We evaluate our method on four benchmark datasets for three diverse settings, including the class, domain, and task-agnostic incremental learning tasks. Experimental results demonstrate consistent improvement (by up to 16.2%), yielded by the proposed method, over the state-of-the-art (SOTA) techniques.
4/30/2024