Language Models Encode Collaborative Signals in Recommendation

0

Sign in to get full access
Overview
- This research paper explores how large language models (LLMs) can encode and leverage collaborative signals for improved recommendation systems.
- The authors propose a linear mapping approach to uncover these collaborative signals within LLMs, showing that they can capture useful information about user-item interactions.
- The findings suggest that LLMs have the potential to serve as powerful building blocks for efficient and effective recommendation systems that combine the strengths of language modeling and collaborative filtering.
Plain English Explanation
Recommendation systems are algorithms that suggest products, content, or information that users might like based on their past preferences and interactions. Traditionally, these systems have used two main approaches: collaborative filtering and content-based filtering.
Collaborative filtering looks at patterns in how users interact with items, like which products they buy or which articles they read. It then uses these patterns to make recommendations. Content-based filtering, on the other hand, looks at the actual characteristics of the items, like their descriptions or features, to make recommendations.
This paper explores a new way of doing recommendation using large language models (LLMs), which are powerful AI models that can understand and generate human-like text. The researchers found that these LLMs can actually capture useful information about user-item interactions, even without being explicitly trained on recommendation tasks.
By using a simple linear mapping approach, the researchers were able to uncover these "collaborative signals" that were hiding within the LLMs. This suggests that LLMs could be a powerful building block for creating efficient and effective recommendation systems that combine the strengths of language modeling and collaborative filtering, as explored in other research like this and this.
Technical Explanation
The key idea behind this research is that large language models (LLMs), which are trained on vast amounts of textual data, may implicitly encode useful collaborative signals about user-item interactions, even without being explicitly trained on recommendation tasks.
To uncover these signals, the authors propose a simple linear mapping approach. They first train an LLM (in this case, GPT-2) on a large corpus of text data. They then obtain the embeddings (numerical representations) of users and items from this LLM. Next, they learn a linear mapping between these embeddings and the true user-item interaction matrix, which captures the collaborative signals.
Through extensive experiments on multiple recommendation datasets, the authors demonstrate that this linear mapping is indeed able to recover meaningful collaborative signals from the LLM embeddings. These recovered signals can then be used to make effective recommendations, outperforming various baselines that do not leverage the LLM information.
Importantly, the authors show that the collaborative signals captured by the LLM are complementary to the content-based signals, suggesting that LLMs can serve as powerful building blocks for hybrid recommendation systems that combine the strengths of language modeling and collaborative filtering.
Critical Analysis
The research presented in this paper is a promising step towards leveraging the power of large language models for building more efficient and effective recommendation systems. The authors demonstrate a simple yet effective approach to uncovering collaborative signals within LLMs, which can then be used to enhance recommendation performance.
One potential limitation of the study is that it focuses on a single LLM (GPT-2) and a limited set of recommendation datasets. It would be valuable to see how the approach generalizes to other LLMs and a wider range of recommendation scenarios, including those with more complex user-item interactions.
Additionally, while the linear mapping approach is conceptually simple and computationally efficient, it may not be able to capture the full complexity of the collaborative signals encoded in LLMs. Exploring more sophisticated techniques for extracting and leveraging these signals, such as knowledge adaptation or language model-driven recommendations, could lead to further improvements in recommendation performance.
Overall, this research represents an important step forward in the integration of large language models and recommendation systems, and it provides a solid foundation for future work in this area.
Conclusion
This paper presents a novel approach to leveraging the power of large language models (LLMs) for building more efficient and effective recommendation systems. By uncovering the collaborative signals encoded within LLMs using a simple linear mapping, the authors demonstrate that these models can serve as powerful building blocks for hybrid recommendation systems that combine the strengths of language modeling and collaborative filtering.
The findings of this research suggest that LLMs have the potential to revolutionize the field of recommendation systems, enabling the creation of more accurate, personalized, and efficient recommendations that better cater to user preferences and needs. As the capabilities of LLMs continue to evolve, the integration of these models with recommendation systems is likely to become an increasingly important area of research and development, with far-reaching implications for a wide range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language Models Encode Collaborative Signals in Recommendation
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, Tat-Seng Chua
Recent studies empirically indicate that language models (LMs) encode rich world knowledge beyond mere semantics, attracting significant attention across various fields. However, in the recommendation domain, it remains uncertain whether LMs implicitly encode user preference information. Contrary to the prevailing understanding that LMs and traditional recommender models learn two distinct representation spaces due to a huge gap in language and behavior modeling objectives, this work rethinks such understanding and explores extracting a recommendation space directly from the language representation space. Surprisingly, our findings demonstrate that item representations, when linearly mapped from advanced LM representations, yield superior recommendation performance. This outcome suggests the homomorphism between the language representation space and an effective recommendation space, implying that collaborative signals may indeed be encoded within advanced LMs. Motivated by these findings, we propose a simple yet effective collaborative filtering (CF) model named AlphaRec, which utilizes language representations of item textual metadata (e.g., titles) instead of traditional ID-based embeddings. Specifically, AlphaRec is comprised of three main components: a multilayer perceptron (MLP), graph convolution, and contrastive learning (CL) loss function, making it extremely easy to implement and train. Our empirical results show that AlphaRec outperforms leading ID-based CF models on multiple datasets, marking the first instance of such a recommender with text embeddings achieving this level of performance. Moreover, AlphaRec introduces a new language-representation-based CF paradigm with several desirable advantages: being easy to implement, lightweight, rapid convergence, superior zero-shot recommendation abilities in new domains, and being aware of user intention.
Read more7/9/2024
0
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, Chanyoung Park
Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
Read more6/4/2024
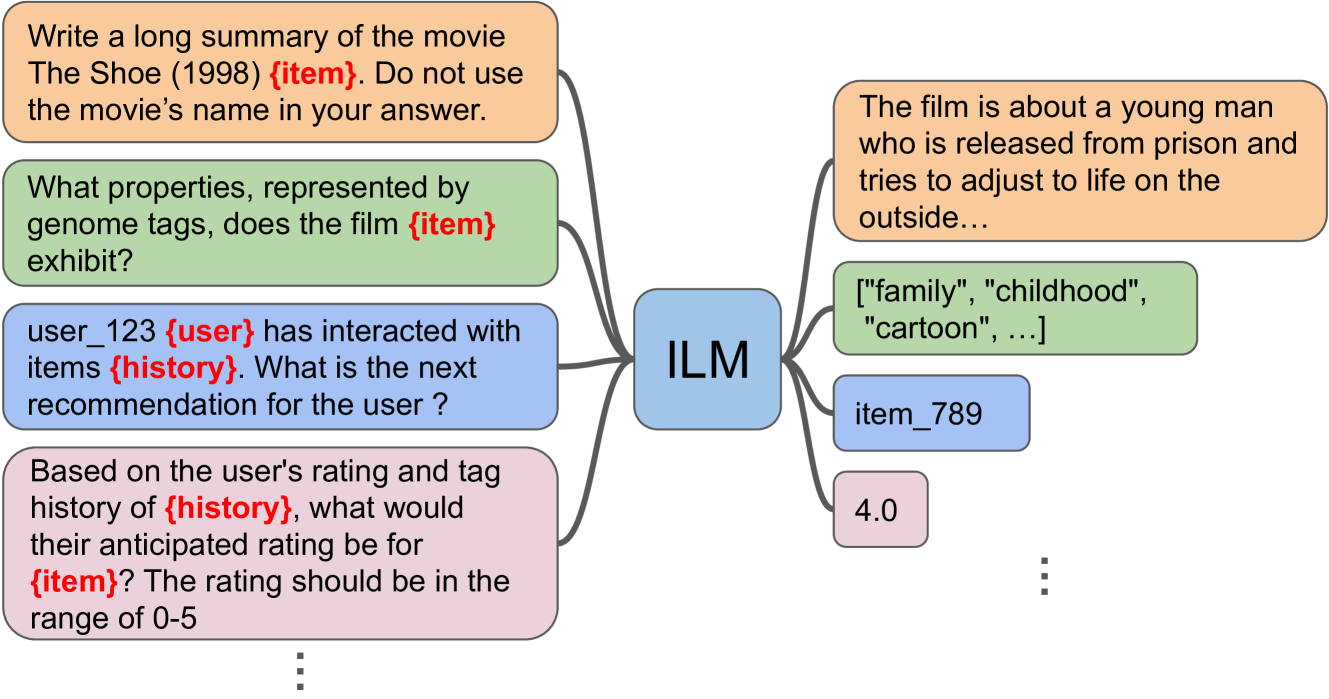
0
Item-Language Model for Conversational Recommendation
Li Yang, Anushya Subbiah, Hardik Patel, Judith Yue Li, Yanwei Song, Reza Mirghaderi, Vikram Aggarwal
Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
Read more6/6/2024

0
Collaborative Cross-modal Fusion with Large Language Model for Recommendation
Zhongzhou Liu, Hao Zhang, Kuicai Dong, Yuan Fang
Despite the success of conventional collaborative filtering (CF) approaches for recommendation systems, they exhibit limitations in leveraging semantic knowledge within the textual attributes of users and items. Recent focus on the application of large language models for recommendation (LLM4Rec) has highlighted their capability for effective semantic knowledge capture. However, these methods often overlook the collaborative signals in user behaviors. Some simply instruct-tune a language model, while others directly inject the embeddings of a CF-based model, lacking a synergistic fusion of different modalities. To address these issues, we propose a framework of Collaborative Cross-modal Fusion with Large Language Models, termed CCF-LLM, for recommendation. In this framework, we translate the user-item interactions into a hybrid prompt to encode both semantic knowledge and collaborative signals, and then employ an attentive cross-modal fusion strategy to effectively fuse latent embeddings of both modalities. Extensive experiments demonstrate that CCF-LLM outperforms existing methods by effectively utilizing semantic and collaborative signals in the LLM4Rec context.
Read more8/19/2024