Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI

0
Sign in to get full access
Overview
- This paper explores the use of large brain models for learning generic representations from extensive electroencephalography (EEG) data in brain-computer interface (BCI) applications.
- The researchers developed a novel large brain model architecture that can effectively leverage vast amounts of EEG data to learn robust and versatile representations.
- The model's performance is evaluated on various BCI tasks, demonstrating its ability to outperform existing approaches and generalize to new domains.
Plain English Explanation
The paper discusses a new approach to using large artificial intelligence (AI) models to interpret and understand brain activity data collected through electroencephalography (EEG). EEG is a technique that records the electrical signals produced by the brain, and it is widely used in brain-computer interfaces (BCIs) to allow people to control devices or computers with their thoughts.
The researchers created a very large and complex AI model that can learn general patterns and features from massive amounts of EEG data. This model is designed to be able to take what it has learned and apply that knowledge to a wide variety of BCI tasks, rather than being narrowly trained on a specific application.
By using this powerful "large brain model," the researchers show that they can outperform existing methods for tasks like decoding a person's thoughts or intentions from their brain activity. This could lead to significant improvements in BCI technology, allowing for more natural and intuitive control of computers and devices by simply thinking about what you want to do.
The key innovation is the ability of this large model to extract fundamental, generalizable representations from huge datasets of brain activity. This means the model can learn the underlying "language" of the brain and apply that knowledge flexibly, rather than just memorizing specific patterns. The researchers demonstrate the model's versatility by testing it on a variety of BCI tasks, showing its ability to adapt and perform well in new situations.
Technical Explanation
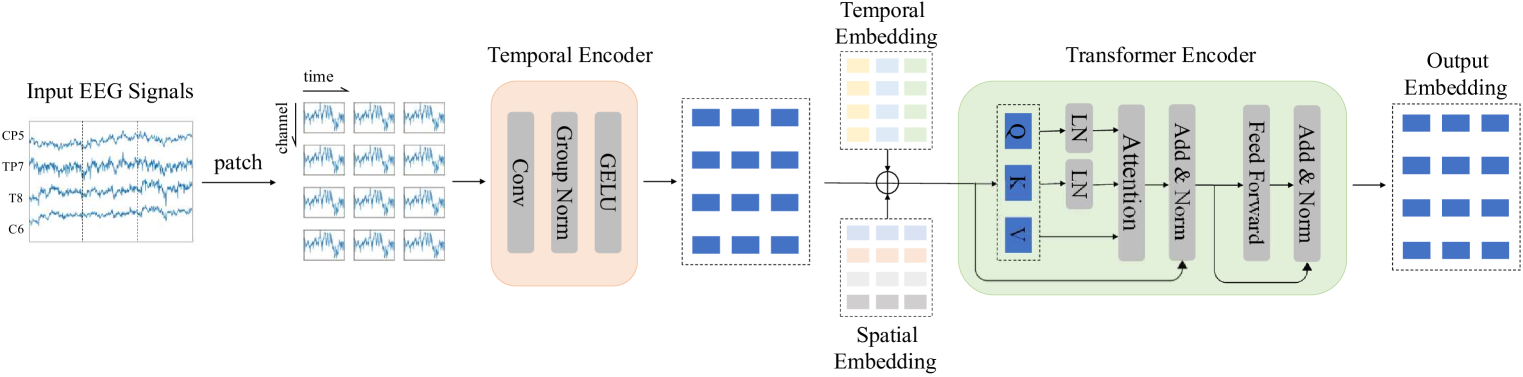
The paper introduces a large brain model for learning generic representations with tremendous EEG data in BCI. The researchers developed a novel model architecture that can effectively leverage vast amounts of EEG data to learn robust and versatile representations.
The model is based on the Transformer architecture, a powerful deep learning model that has shown great success in natural language processing. The researchers adapted the Transformer to work with EEG data, creating the EEGEncoder model.
The EEGEncoder model is trained on a massive dataset of EEG recordings, allowing it to learn generic, transferable representations of brain activity. This enables the model to perform well on a wide range of BCI tasks, including decoding text from EEG signals and motor imagery classification.
The key innovation of this work is the use of a large, flexible model that can extract fundamental features and patterns from vast amounts of EEG data. This allows the model to learn a more comprehensive and versatile understanding of brain activity, rather than being limited to narrow, task-specific representations.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. First, while the large brain model demonstrates impressive performance on a variety of BCI tasks, its computational and memory requirements are substantial, which may limit its practical deployment in real-world applications.
Additionally, the paper does not provide a detailed analysis of the model's internal representations and the specific features it learns from the EEG data. Further research is needed to better understand the model's "understanding" of brain activity and how this translates to its strong performance.
Another potential concern is the reliance on large, curated datasets for training the model. In real-world BCI scenarios, data may be noisier, sparser, or more subject-specific, which could present challenges for the model's generalization capabilities.
Overall, the paper presents a promising approach to leveraging large, flexible models for advancing BCI technology. However, additional research is necessary to address the practical limitations, interpretability, and robustness of the proposed model in more realistic and diverse BCI settings.
Conclusion
The paper introduces a novel large brain model that can effectively learn generic representations from vast amounts of EEG data, enabling it to outperform existing methods on a variety of BCI tasks. This work demonstrates the potential of flexible, data-driven approaches to improve the understanding and decoding of brain activity, which could lead to significant advancements in brain-computer interface technology.
While the model's computational requirements and the need for further interpretation of its internal representations present some challenges, the researchers' approach represents an important step forward in leveraging large-scale machine learning to unlock the rich information contained within EEG data. As the field of BCI continues to evolve, this type of versatile and generalized modeling may prove essential for developing more intuitive and capable brain-controlled systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI
Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu
The current electroencephalogram (EEG) based deep learning models are typically designed for specific datasets and applications in brain-computer interaction (BCI), limiting the scale of the models and thus diminishing their perceptual capabilities and generalizability. Recently, Large Language Models (LLMs) have achieved unprecedented success in text processing, prompting us to explore the capabilities of Large EEG Models (LEMs). We hope that LEMs can break through the limitations of different task types of EEG datasets, and obtain universal perceptual capabilities of EEG signals through unsupervised pre-training. Then the models can be fine-tuned for different downstream tasks. However, compared to text data, the volume of EEG datasets is generally small and the format varies widely. For example, there can be mismatched numbers of electrodes, unequal length data samples, varied task designs, and low signal-to-noise ratio. To overcome these challenges, we propose a unified foundation model for EEG called Large Brain Model (LaBraM). LaBraM enables cross-dataset learning by segmenting the EEG signals into EEG channel patches. Vector-quantized neural spectrum prediction is used to train a semantically rich neural tokenizer that encodes continuous raw EEG channel patches into compact neural codes. We then pre-train neural Transformers by predicting the original neural codes for the masked EEG channel patches. The LaBraMs were pre-trained on about 2,500 hours of various types of EEG signals from around 20 datasets and validated on multiple different types of downstream tasks. Experiments on abnormal detection, event type classification, emotion recognition, and gait prediction show that our LaBraM outperforms all compared SOTA methods in their respective fields. Our code is available at https://github.com/935963004/LaBraM.
Read more5/30/2024

0
NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals
Wei-Bang Jiang, Yansen Wang, Bao-Liang Lu, Dongsheng Li
Recent advancements for large-scale pre-training with neural signals such as electroencephalogram (EEG) have shown promising results, significantly boosting the development of brain-computer interfaces (BCIs) and healthcare. However, these pre-trained models often require full fine-tuning on each downstream task to achieve substantial improvements, limiting their versatility and usability, and leading to considerable resource wastage. To tackle these challenges, we propose NeuroLM, the first multi-task foundation model that leverages the capabilities of Large Language Models (LLMs) by regarding EEG signals as a foreign language, endowing the model with multi-task learning and inference capabilities. Our approach begins with learning a text-aligned neural tokenizer through vector-quantized temporal-frequency prediction, which encodes EEG signals into discrete neural tokens. These EEG tokens, generated by the frozen vector-quantized (VQ) encoder, are then fed into an LLM that learns causal EEG information via multi-channel autoregression. Consequently, NeuroLM can understand both EEG and language modalities. Finally, multi-task instruction tuning adapts NeuroLM to various downstream tasks. We are the first to demonstrate that, by specific incorporation with LLMs, NeuroLM unifies diverse EEG tasks within a single model through instruction tuning. The largest variant NeuroLM-XL has record-breaking 1.7B parameters for EEG signal processing, and is pre-trained on a large-scale corpus comprising approximately 25,000-hour EEG data. When evaluated on six diverse downstream datasets, NeuroLM showcases the huge potential of this multi-task learning paradigm.
Read more9/4/2024

0
Towards Linguistic Neural Representation Learning and Sentence Retrieval from Electroencephalogram Recordings
Jinzhao Zhou, Yiqun Duan, Ziyi Zhao, Yu-Cheng Chang, Yu-Kai Wang, Thomas Do, Chin-Teng Lin
Decoding linguistic information from non-invasive brain signals using EEG has gained increasing research attention due to its vast applicational potential. Recently, a number of works have adopted a generative-based framework to decode electroencephalogram (EEG) signals into sentences by utilizing the power generative capacity of pretrained large language models (LLMs). However, this approach has several drawbacks that hinder the further development of linguistic applications for brain-computer interfaces (BCIs). Specifically, the ability of the EEG encoder to learn semantic information from EEG data remains questionable, and the LLM decoder's tendency to generate sentences based on its training memory can be hard to avoid. These issues necessitate a novel approach for converting EEG signals into sentences. In this paper, we propose a novel two-step pipeline that addresses these limitations and enhances the validity of linguistic EEG decoding research. We first confirm that word-level semantic information can be learned from EEG data recorded during natural reading by training a Conformer encoder via a masked contrastive objective for word-level classification. To achieve sentence decoding results, we employ a training-free retrieval method to retrieve sentences based on the predictions from the EEG encoder. Extensive experiments and ablation studies were conducted in this paper for a comprehensive evaluation of the proposed approach. Visualization of the top prediction candidates reveals that our model effectively groups EEG segments into semantic categories with similar meanings, thereby validating its ability to learn patterns from unspoken EEG recordings. Despite the exploratory nature of this work, these results suggest that our method holds promise for providing more reliable solutions for converting EEG signals into text.
Read more8/12/2024
🔎
0
Large Transformers are Better EEG Learners
Bingxin Wang, Xiaowen Fu, Yuan Lan, Luchan Zhang, Wei Zheng, Yang Xiang
Pre-trained large transformer models have achieved remarkable performance in the fields of natural language processing and computer vision. However, the limited availability of public electroencephalogram (EEG) data presents a unique challenge for extending the success of these models to EEG-based tasks. To address this gap, we propose AdaCT, plug-and-play Adapters designed for Converting Time series data into spatio-temporal 2D pseudo-images or text forms. Essentially, AdaCT-I transforms multi-channel or lengthy single-channel time series data into spatio-temporal 2D pseudo-images for fine-tuning pre-trained vision transformers, while AdaCT-T converts short single-channel data into text for fine-tuning pre-trained language transformers. The proposed approach allows for seamless integration of pre-trained vision models and language models in time series decoding tasks, particularly in EEG data analysis. Experimental results on diverse benchmark datasets, including Epileptic Seizure Recognition, Sleep-EDF, and UCI HAR, demonstrate the superiority of AdaCT over baseline methods. Overall, we provide a promising transfer learning framework for leveraging the capabilities of pre-trained vision and language models in EEG-based tasks, thereby advancing the field of time series decoding and enhancing interpretability in EEG data analysis. Our code will be available at https://github.com/wangbxj1234/AdaCE.
Read more4/16/2024