NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals

0

Sign in to get full access
Overview
- A universal multi-task foundation model that bridges the gap between language and EEG (electroencephalography) signals
- Aims to enable cross-modal learning and reasoning between language and brain activity
- Potential applications in brain-computer interfaces, neurorehabilitation, and neuroscience research
Plain English Explanation
The paper presents a new machine learning model called \method that can work with both language and brain activity (EEG) data. It's designed to be a "universal" model that can handle a variety of language and EEG-based tasks, rather than being specialized for one specific application.
The key idea is to train this model on a wide range of language and EEG datasets, allowing it to learn generic representations that capture the underlying connections between how we use language and how our brains process information. This enables the model to perform well on new language and EEG tasks, even if it hasn't seen that exact task before.
The researchers demonstrate that \method can achieve strong performance on a range of benchmarks, including tasks like translating text, answering questions, and decoding brain signals. This suggests the model has learned some fundamental connections between language and brain activity that make it useful for bridging the gap between these two modalities.
Some potential applications of this work include improved brain-computer interfaces (where the system can understand your intentions from your brain signals), better tools for neurorehabilitation (e.g. restoring communication for people with disabilities), and more powerful neuroscience research (using language and brain data together to study the neural basis of cognition).
Technical Explanation
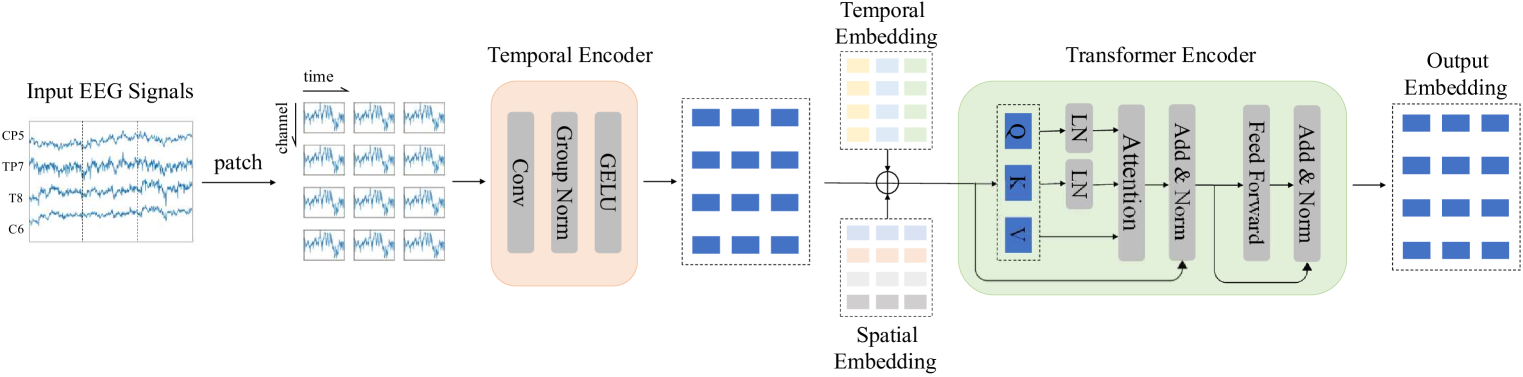
The \method architecture is built on top of a large language model, which is then extended to also process EEG signals. Specifically, the model takes in both text and EEG data as input, and is trained to perform a variety of language and EEG-based tasks simultaneously.
The key innovation is the use of a "cross-modal" attention mechanism, which allows the model to dynamically attend to relevant parts of both the text and EEG signals when making predictions. This enables the model to discover and leverage the connections between language and brain activity during training.
The researchers evaluate \method on a range of language benchmarks (e.g. text translation, question answering) as well as EEG-based tasks (e.g. decoding cognitive states from brain signals). They show that \method outperforms specialized models on these tasks, demonstrating the benefits of its universal, cross-modal design.
Critical Analysis
The paper makes a compelling case for the utility of a universal language-EEG model like \method. By training on diverse datasets, the model is able to learn robust cross-modal representations that generalize well to new tasks and datasets.
However, the authors acknowledge some limitations of the current work. For example, the model was only evaluated on relatively controlled EEG datasets collected in lab settings. Its performance on more naturalistic, real-world EEG data remains to be seen.
Additionally, the inner workings of the cross-modal attention mechanism are not explored in depth. It would be valuable to better understand how the model is actually discovering and leveraging the connections between language and brain activity.
Further research is also needed to fully realize the potential applications of this technology, such as in brain-computer interfaces and neurorehabilitation. Careful consideration of ethical and privacy implications will also be crucial as this type of technology becomes more advanced and widely deployed.
Conclusion
The \method model represents an exciting step towards bridging the gap between language and brain activity processing. By learning generic cross-modal representations, it has the potential to enable a wide range of applications that leverage both language and EEG data.
While the current work has some limitations, the strong performance on benchmark tasks suggests \method is a promising foundation for future research and development in this area. As the technology matures, it could lead to significant advancements in how we interact with and understand the human brain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals
Wei-Bang Jiang, Yansen Wang, Bao-Liang Lu, Dongsheng Li
Recent advancements for large-scale pre-training with neural signals such as electroencephalogram (EEG) have shown promising results, significantly boosting the development of brain-computer interfaces (BCIs) and healthcare. However, these pre-trained models often require full fine-tuning on each downstream task to achieve substantial improvements, limiting their versatility and usability, and leading to considerable resource wastage. To tackle these challenges, we propose NeuroLM, the first multi-task foundation model that leverages the capabilities of Large Language Models (LLMs) by regarding EEG signals as a foreign language, endowing the model with multi-task learning and inference capabilities. Our approach begins with learning a text-aligned neural tokenizer through vector-quantized temporal-frequency prediction, which encodes EEG signals into discrete neural tokens. These EEG tokens, generated by the frozen vector-quantized (VQ) encoder, are then fed into an LLM that learns causal EEG information via multi-channel autoregression. Consequently, NeuroLM can understand both EEG and language modalities. Finally, multi-task instruction tuning adapts NeuroLM to various downstream tasks. We are the first to demonstrate that, by specific incorporation with LLMs, NeuroLM unifies diverse EEG tasks within a single model through instruction tuning. The largest variant NeuroLM-XL has record-breaking 1.7B parameters for EEG signal processing, and is pre-trained on a large-scale corpus comprising approximately 25,000-hour EEG data. When evaluated on six diverse downstream datasets, NeuroLM showcases the huge potential of this multi-task learning paradigm.
Read more9/4/2024
0
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI
Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu
The current electroencephalogram (EEG) based deep learning models are typically designed for specific datasets and applications in brain-computer interaction (BCI), limiting the scale of the models and thus diminishing their perceptual capabilities and generalizability. Recently, Large Language Models (LLMs) have achieved unprecedented success in text processing, prompting us to explore the capabilities of Large EEG Models (LEMs). We hope that LEMs can break through the limitations of different task types of EEG datasets, and obtain universal perceptual capabilities of EEG signals through unsupervised pre-training. Then the models can be fine-tuned for different downstream tasks. However, compared to text data, the volume of EEG datasets is generally small and the format varies widely. For example, there can be mismatched numbers of electrodes, unequal length data samples, varied task designs, and low signal-to-noise ratio. To overcome these challenges, we propose a unified foundation model for EEG called Large Brain Model (LaBraM). LaBraM enables cross-dataset learning by segmenting the EEG signals into EEG channel patches. Vector-quantized neural spectrum prediction is used to train a semantically rich neural tokenizer that encodes continuous raw EEG channel patches into compact neural codes. We then pre-train neural Transformers by predicting the original neural codes for the masked EEG channel patches. The LaBraMs were pre-trained on about 2,500 hours of various types of EEG signals from around 20 datasets and validated on multiple different types of downstream tasks. Experiments on abnormal detection, event type classification, emotion recognition, and gait prediction show that our LaBraM outperforms all compared SOTA methods in their respective fields. Our code is available at https://github.com/935963004/LaBraM.
Read more5/30/2024

0
EEG-Language Modeling for Pathology Detection
Sam Gijsen, Kerstin Ritter
Multimodal language modeling constitutes a recent breakthrough which leverages advances in large language models to pretrain capable multimodal models. The integration of natural language during pretraining has been shown to significantly improve learned representations, particularly in computer vision. However, the efficacy of multimodal language modeling in the realm of functional brain data, specifically for advancing pathology detection, remains unexplored. This study pioneers EEG-language models trained on clinical reports and 15000 EEGs. We extend methods for multimodal alignment to this novel domain and investigate which textual information in reports is useful for training EEG-language models. Our results indicate that models learn richer representations from being exposed to a variety of report segments, including the patient's clinical history, description of the EEG, and the physician's interpretation. Compared to models exposed to narrower clinical text information, we find such models to retrieve EEGs based on clinical reports (and vice versa) with substantially higher accuracy. Yet, this is only observed when using a contrastive learning approach. Particularly in regimes with few annotations, we observe that representations of EEG-language models can significantly improve pathology detection compared to those of EEG-only models, as demonstrated by both zero-shot classification and linear probes. In sum, these results highlight the potential of integrating brain activity data with clinical text, suggesting that EEG-language models represent significant progress for clinical applications.
Read more9/14/2024

0
Exploring Large-Scale Language Models to Evaluate EEG-Based Multimodal Data for Mental Health
Yongquan Hu, Shuning Zhang, Ting Dang, Hong Jia, Flora D. Salim, Wen Hu, Aaron J. Quigley
Integrating physiological signals such as electroencephalogram (EEG), with other data such as interview audio, may offer valuable multimodal insights into psychological states or neurological disorders. Recent advancements with Large Language Models (LLMs) position them as prospective ``health agents'' for mental health assessment. However, current research predominantly focus on single data modalities, presenting an opportunity to advance understanding through multimodal data. Our study aims to advance this approach by investigating multimodal data using LLMs for mental health assessment, specifically through zero-shot and few-shot prompting. Three datasets are adopted for depression and emotion classifications incorporating EEG, facial expressions, and audio (text). The results indicate that multimodal information confers substantial advantages over single modality approaches in mental health assessment. Notably, integrating EEG alongside commonly used LLM modalities such as audio and images demonstrates promising potential. Moreover, our findings reveal that 1-shot learning offers greater benefits compared to zero-shot learning methods.
Read more8/15/2024