Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
2402.11541
0
0
Abstract
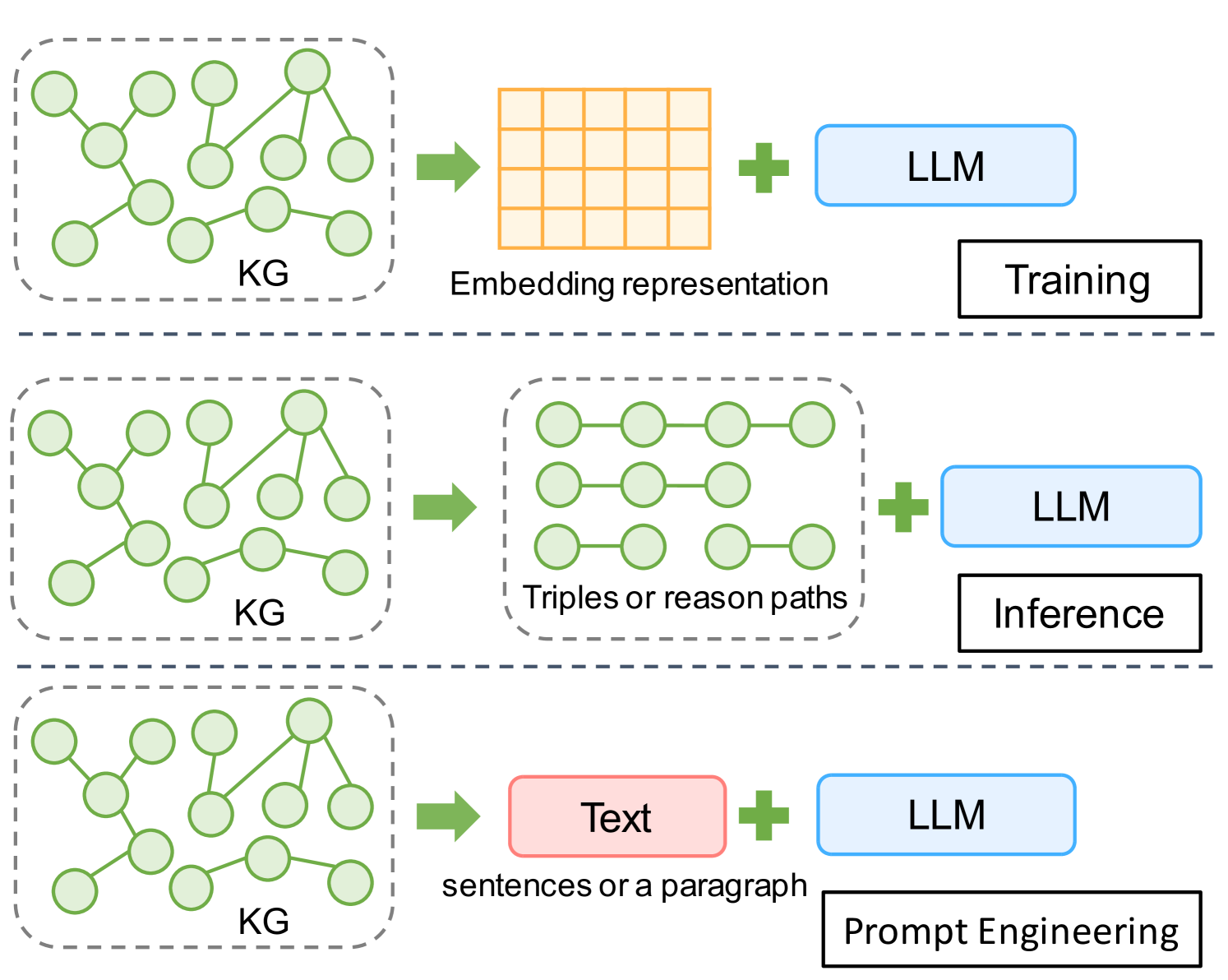
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
Create account to get full access
Overview
- This paper explores the surprising finding that large language models (LLMs) can better understand knowledge graphs than previously thought.
- The researchers investigate the knowledge reasoning capabilities of LLMs and how they compare to human performance on tasks related to knowledge graphs.
- The results challenge the common assumption that LLMs struggle with tasks requiring logical reasoning and suggest they may be more capable in this area than expected.
Plain English Explanation
Knowledge graphs are structured databases that represent information as a network of connected concepts and relationships. They are commonly used to store and organize large amounts of knowledge, like the information in encyclopedias or databases.
The paper "Head to Tail: How Knowledgeable Are Large Language Models?" has shown that LLMs like GPT-3 can understand and reason about the information in knowledge graphs quite well. This is surprising because LLMs are often thought to struggle with logical reasoning and tasks that require structured knowledge.
The researchers in this new paper decided to further investigate this phenomenon. They designed experiments to test how LLMs perform on various knowledge graph reasoning tasks, and compared the results to human performance. Contrary to expectations, they found that LLMs can sometimes outperform humans on these types of tasks.
This suggests that LLMs may have more advanced reasoning capabilities than previously believed. They may be able to extract and manipulate structured knowledge from text in ways that are more sophisticated than we thought.
Technical Explanation
The paper examines the knowledge reasoning capabilities of large language models (LLMs) by comparing their performance to human performance on a range of tasks related to knowledge graphs.
The researchers first constructed a benchmark suite of knowledge graph reasoning tasks, which tested the models' ability to understand concepts, relationships, and logical inferences within the knowledge graph. They evaluated several state-of-the-art LLMs, including GPT-3, on this benchmark.
Surprisingly, the results showed that the LLMs were able to outperform human participants on many of the tasks, especially those requiring logical reasoning and inference. The models demonstrated a strong ability to traverse the knowledge graph, identify relevant connections, and make deductions about the underlying information.
Further analysis revealed that the LLMs were able to effectively leverage the structured knowledge representation in the knowledge graphs, despite their training on unstructured text data. This challenges the common assumption that LLMs struggle with tasks requiring logical reasoning and structured knowledge.
The paper suggests that the knowledge reasoning capabilities of LLMs are more advanced than previously thought, and that these models may be better able to understand and reason about structured knowledge than humans in certain contexts. This has important implications for the development of knowledge-intensive AI systems and their potential applications.
Critical Analysis
The paper presents compelling evidence that LLMs can achieve superior performance on knowledge graph reasoning tasks compared to humans. This challenges the prevailing view that LLMs struggle with logical reasoning and structured knowledge. However, the authors acknowledge several important caveats and limitations to their findings.
First, the benchmark tasks used in the study may not fully capture the complexity and diversity of real-world knowledge graph reasoning. The tasks were designed to isolate specific capabilities, but in practice, knowledge graph reasoning often involves more nuanced and contextual understanding.
Additionally, the study focused on a limited set of LLM architectures and configurations. It's possible that other LLM models or training approaches could exhibit different capabilities when it comes to knowledge graph reasoning.
The paper also does not explore the underlying mechanisms that allow LLMs to outperform humans on these tasks. More research is needed to understand how LLMs are able to effectively leverage the structured information in knowledge graphs, and whether this capability generalizes to other types of structured data.
Finally, the authors note that while the LLMs demonstrated strong performance, there may be certain types of reasoning or tasks where human experts still maintain an advantage. Further research is needed to fully characterize the strengths and limitations of LLMs compared to human intelligence.
Overall, this paper presents thought-provoking findings that challenge our assumptions about the reasoning capabilities of large language models. However, it also highlights the need for continued investigation and a more nuanced understanding of the relationship between LLMs and structured knowledge.
Conclusion
This paper challenges the common assumption that large language models (LLMs) struggle with tasks requiring logical reasoning and structured knowledge. Through a series of experiments comparing LLM and human performance on knowledge graph reasoning tasks, the researchers found that LLMs can often outperform humans, particularly on tasks involving logical inference and deduction.
These findings suggest that the knowledge reasoning capabilities of LLMs may be more advanced than previously thought. The models appear to be able to effectively leverage the structured information in knowledge graphs, despite being trained primarily on unstructured text data.
This has important implications for the development of knowledge-intensive AI systems that can better understand and reason about complex, structured information. It also raises questions about the nature of intelligence and the comparative capabilities of artificial and human intelligence.
While the paper presents compelling evidence, it also acknowledges important limitations and areas for further research. Continued investigation is needed to fully characterize the strengths and weaknesses of LLMs when it comes to knowledge reasoning, and to explore the underlying mechanisms that enable their surprising performance.
Overall, this paper offers a thought-provoking challenge to our assumptions about the reasoning capabilities of large language models, and suggests new directions for the advancement of AI systems that can better understand and leverage structured knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
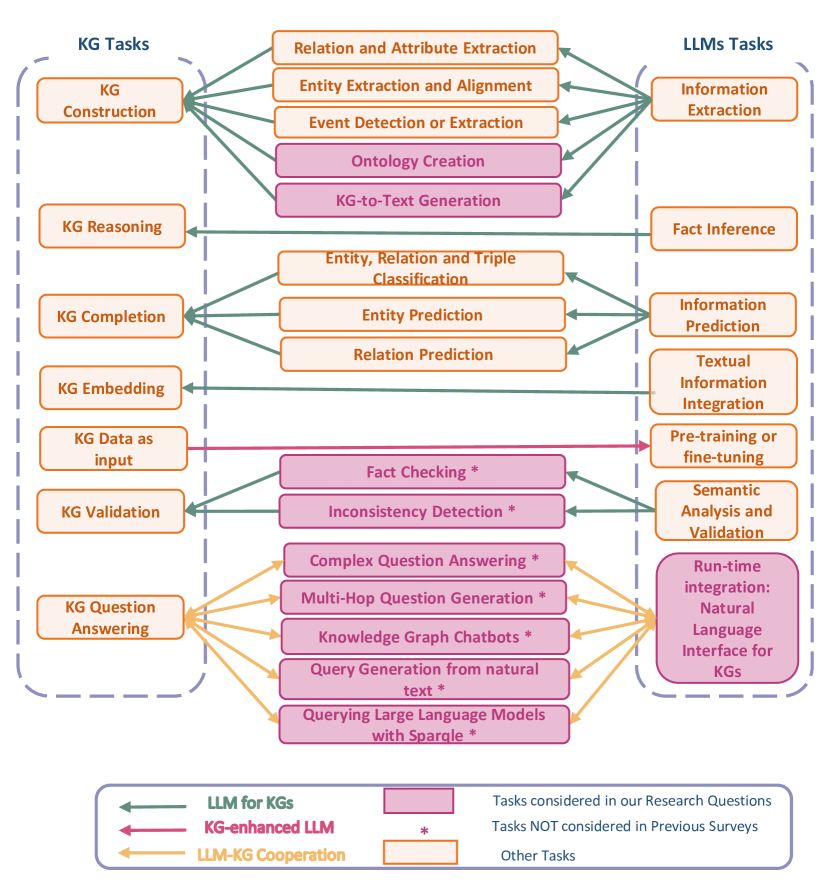
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Wenyu Huang, Guancheng Zhou, Mirella Lapata, Pavlos Vougiouklis, Sebastien Montella, Jeff Z. Pan
0
0
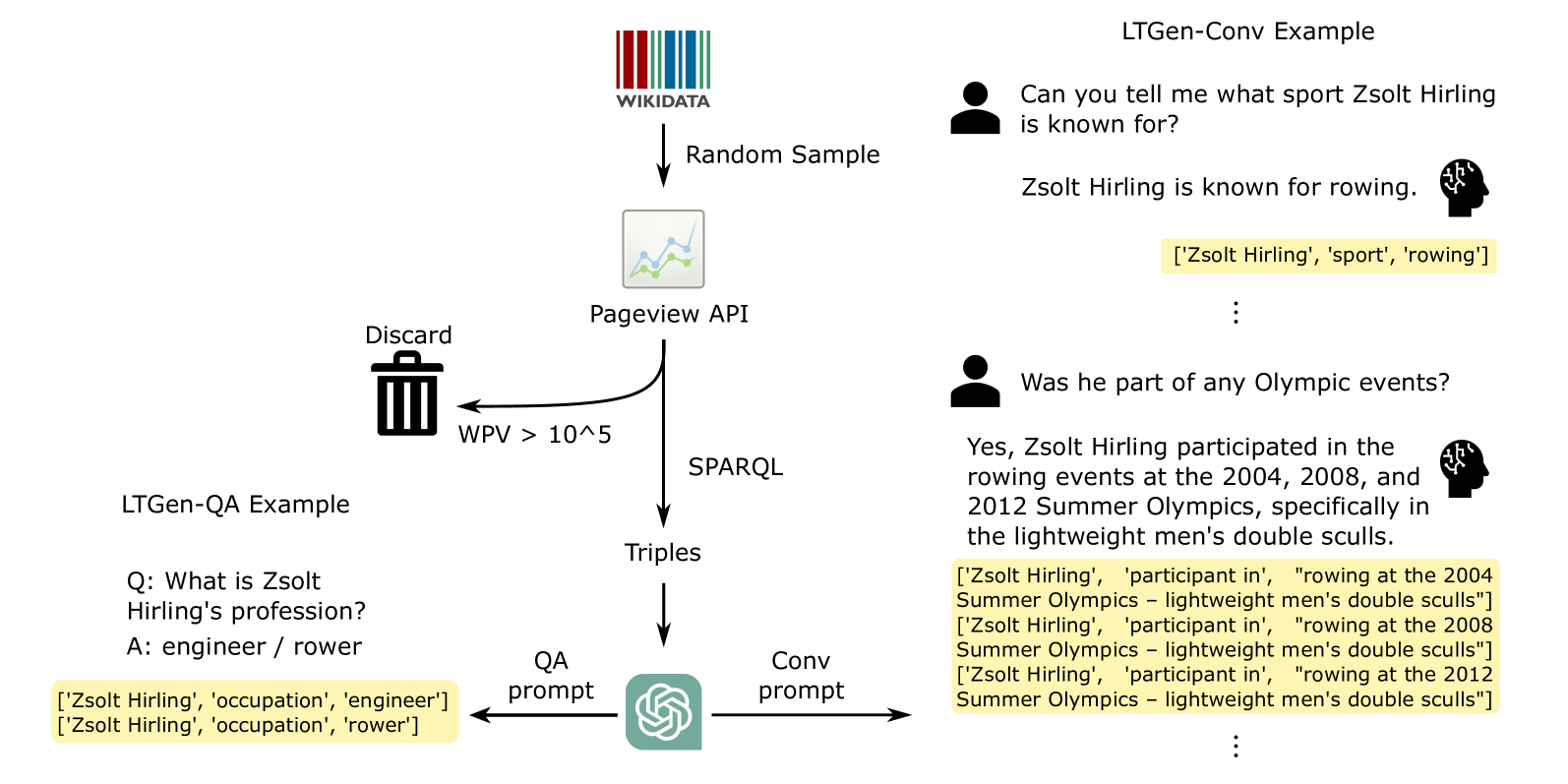
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
5/13/2024
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
0
0
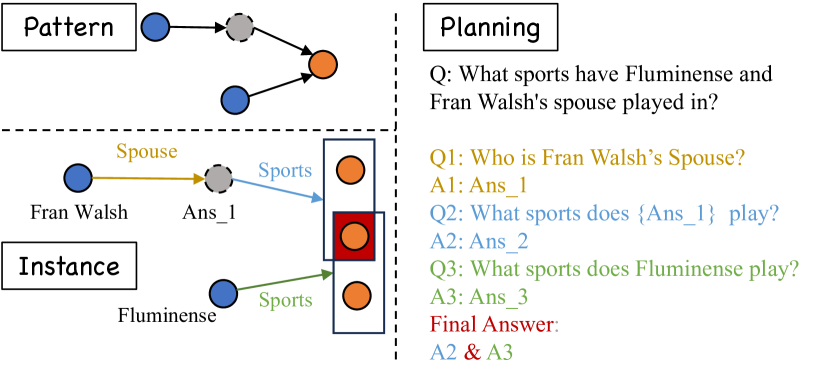
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
6/21/2024