Large Language Model Aided QoS Prediction for Service Recommendation

0
Sign in to get full access
Overview
- Proposes a method to predict Quality of Service (QoS) for service recommendation using a large language model
- Aims to improve service recommendation by providing more accurate QoS predictions
- Leverages the capabilities of large language models to capture complex relationships between service features and QoS
Plain English Explanation
When you need to use an online service, such as booking a hotel or ordering food delivery, you want to find the best option that meets your needs. This often comes down to the Quality of Service (QoS) - things like how quickly the service is provided, how reliable it is, and how satisfied customers are.
The researchers in this paper developed a way to predict the QoS of different service options using a large language model. Large language models are advanced AI systems that can understand and generate human-like text. By training a large language model on data about different services and their QoS, the researchers were able to create a system that can predict the QoS of new services with a high degree of accuracy.
This technology could be very useful for service recommendation. Instead of just showing users a list of services, the system could provide predictions about the likely QoS of each option, helping users make a more informed choice.
Technical Explanation
The key elements of the paper are:
-
Experiment Design: The researchers collected data on various online services, including information about their features (e.g., price, delivery time) and actual QoS metrics (e.g., customer satisfaction scores). They then used this data to train a large language model to predict QoS based on service features.
-
Architecture: The researchers used a transformer-based large language model as the core of their QoS prediction system. Transformers are a type of neural network architecture that has shown great success in natural language processing tasks. By fine-tuning the language model on the service QoS data, the researchers were able to create a model that could accurately predict QoS for new service offerings.
-
Insights: The experiments showed that the large language model-based QoS prediction system outperformed traditional machine learning approaches, especially when dealing with complex, high-dimensional service data. The language model was able to capture subtle relationships between service features and QoS that were difficult for other models to learn.
Critical Analysis
The paper provides a compelling approach to improving service recommendation through more accurate QoS prediction. However, there are a few potential limitations and areas for further research:
-
Data Quality: The performance of the QoS prediction model is heavily dependent on the quality and completeness of the training data. The researchers did not provide much detail on how they collected and preprocessed the service data, which could impact the model's reliability.
-
Generalization: While the model performed well on the test data, it's unclear how well it would generalize to new, unseen services with different features or QoS characteristics. Further testing on a wider range of service domains would be helpful to assess the model's robustness.
-
Explainability: Large language models can be difficult to interpret, as they learn complex, abstract representations of the data. It would be valuable to explore ways to make the QoS predictions more transparent and explainable, so users can understand the reasoning behind the recommendations.
-
Real-world Integration: The paper focuses on the technical aspects of the QoS prediction model, but does not discuss how it could be integrated into actual service recommendation systems. Addressing the practical challenges of deploying such a model in a production environment would be an important next step.
Conclusion
This research presents a promising approach to improve service recommendation by leveraging the power of large language models to predict QoS with a high degree of accuracy. By providing users with more reliable information about the likely quality of different service options, this technology could lead to better-informed choices and ultimately higher customer satisfaction. While there are some areas for further exploration, this work demonstrates the potential of advanced AI techniques to enhance decision-making in the service industry and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Model Aided QoS Prediction for Service Recommendation
Huiying Liu, Zekun Zhang, Honghao Li, Qilin Wu, Yiwen Zhang
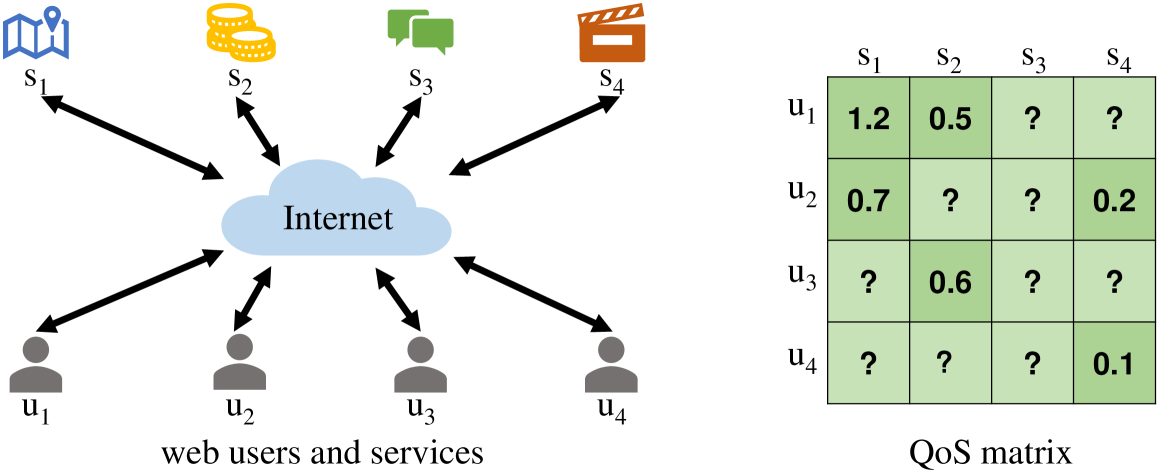
Large language models (LLMs) have seen rapid improvement in the recent years, and have been used in a wider range of applications. After being trained on large text corpus, LLMs obtain the capability of extracting rich features from textual data. Such capability is potentially useful for the web service recommendation task, where the web users and services have intrinsic attributes that can be described using natural language sentences and are useful for recommendation. In this paper, we explore the possibility and practicality of using LLMs for web service recommendation. We propose the large language model aided QoS prediction (llmQoS) model, which use LLMs to extract useful information from attributes of web users and services via descriptive sentences. This information is then used in combination with the QoS values of historical interactions of users and services, to predict QoS values for any given user-service pair. On the WSDream dataset, llmQoS is shown to overcome the data sparsity issue inherent to the QoS prediction problem, and outperforms comparable baseline models consistently.
Read more8/19/2024
💬
1
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Read more6/19/2024

0
Large Language Models for Power Scheduling: A User-Centric Approach
Thomas Mongaillard, Samson Lasaulce, Othman Hicheur, Chao Zhang, Lina Bariah, Vineeth S. Varma, Hang Zou, Qiyang Zhao, Merouane Debbah
While traditional optimization and scheduling schemes are designed to meet fixed, predefined system requirements, future systems are moving toward user-driven approaches and personalized services, aiming to achieve high quality-of-experience (QoE) and flexibility. This challenge is particularly pronounced in wireless and digitalized energy networks, where users' requirements have largely not been taken into consideration due to the lack of a common language between users and machines. The emergence of powerful large language models (LLMs) marks a radical departure from traditional system-centric methods into more advanced user-centric approaches by providing a natural communication interface between users and devices. In this paper, for the first time, we introduce a novel architecture for resource scheduling problems by constructing three LLM agents to convert an arbitrary user's voice request (VRQ) into a resource allocation vector. Specifically, we design an LLM intent recognition agent to translate the request into an optimization problem (OP), an LLM OP parameter identification agent, and an LLM OP solving agent. To evaluate system performance, we construct a database of typical VRQs in the context of electric vehicle (EV) charging. As a proof of concept, we primarily use Llama 3 8B. Through testing with different prompt engineering scenarios, the obtained results demonstrate the efficiency of the proposed architecture. The conducted performance analysis allows key insights to be extracted. For instance, having a larger set of candidate OPs to model the real-world problem might degrade the final performance because of a higher recognition/OP classification noise level. All results and codes are open source.
Read more7/22/2024

0
LLM-PQA: LLM-enhanced Prediction Query Answering
Ziyu Li, Wenjie Zhao, Asterios Katsifodimos, Rihan Hai
The advent of Large Language Models (LLMs) provides an opportunity to change the way queries are processed, moving beyond the constraints of conventional SQL-based database systems. However, using an LLM to answer a prediction query is still challenging, since an external ML model has to be employed and inference has to be performed in order to provide an answer. This paper introduces LLM-PQA, a novel tool that addresses prediction queries formulated in natural language. LLM-PQA is the first to combine the capabilities of LLMs and retrieval-augmented mechanism for the needs of prediction queries by integrating data lakes and model zoos. This integration provides users with access to a vast spectrum of heterogeneous data and diverse ML models, facilitating dynamic prediction query answering. In addition, LLM-PQA can dynamically train models on demand, based on specific query requirements, ensuring reliable and relevant results even when no pre-trained model in a model zoo, available for the task.
Read more9/4/2024