A Large Language Model Approach to Educational Survey Feedback Analysis
2309.17447
0
0
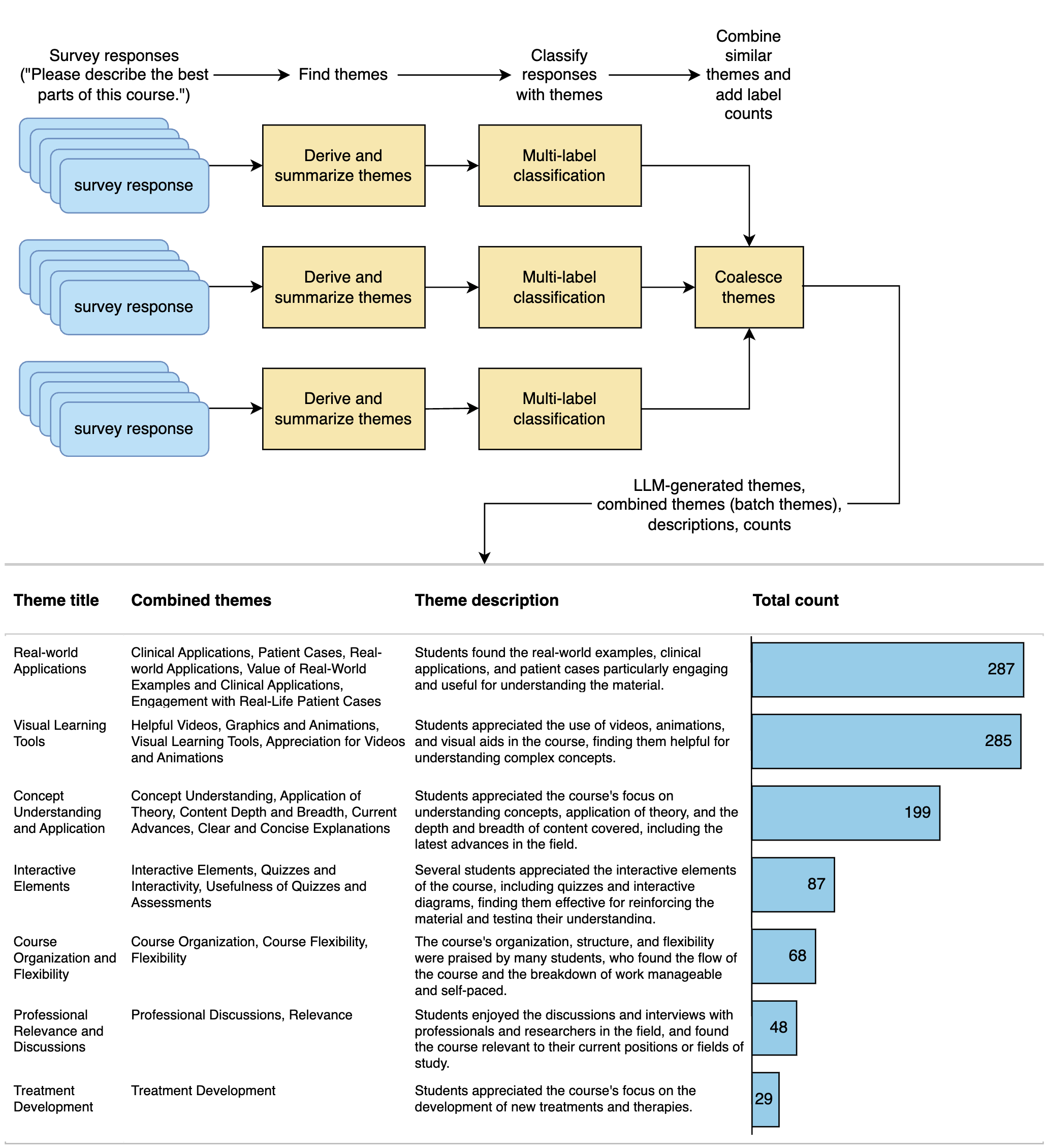
Abstract
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for analyzing unstructured survey feedback data, with a focus on educational contexts.
- The authors investigate various tasks associated with processing and interpreting open-ended survey responses, including sentiment analysis, topic modeling, and summarization.
- The research aims to assess the capabilities of LLMs in leveraging their natural language understanding and generation abilities to extract meaningful insights from educational survey data.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. In this paper, the researchers look at how LLMs could be used to analyze the feedback and comments collected through surveys, particularly in educational settings.
Surveys are commonly used to gather feedback and opinions from students, teachers, and other stakeholders in education. However, the open-ended, unstructured nature of survey responses can make it challenging to extract useful insights. The researchers investigate whether LLMs can help with tasks like understanding the sentiment (positive or negative) of the feedback, identifying the main topics discussed, and summarizing the key points.
The goal is to see if LLMs can be leveraged to make sense of large volumes of survey data more efficiently and effectively than traditional methods. This could help educators and administrators better understand the perspectives and experiences of their students, teachers, and other stakeholders, leading to more informed decision-making and improvements in the educational system.
Technical Explanation
The paper begins by discussing the various tasks associated with analyzing unstructured survey data, such as sentiment analysis, topic modeling, and summarization. The authors note that while these tasks are crucial for deriving insights from educational survey feedback, they can be time-consuming and challenging when done manually or with traditional natural language processing techniques.
To address this, the researchers explore the potential of using large language models (LLMs) for these analysis tasks. LLMs, such as GPT-3, have demonstrated remarkable capabilities in understanding and generating human-like text, which the authors hypothesize could be applied to survey feedback data.
The paper then reviews previous approaches and challenges in analyzing education-related survey feedback, highlighting the limitations of traditional methods and the need for more scalable and effective solutions.
The technical explanation goes on to describe the experiments conducted by the researchers to evaluate the performance of LLMs on various survey data analysis tasks. This includes assessing the models' ability to accurately identify sentiment, extract key topics, and generate concise summaries of survey responses.
The authors present their findings, which suggest that LLMs can indeed be effectively leveraged for these analysis tasks, outperforming traditional methods in many cases. They also discuss the implications of their results and the potential for open-source language models to provide feedback in educational contexts.
Critical Analysis
The paper provides a compelling case for the use of large language models in analyzing educational survey data. The researchers have carefully designed their experiments and demonstrated the potential benefits of this approach, such as improved efficiency, scalability, and accuracy compared to manual or rule-based methods.
However, the paper also acknowledges several limitations and areas for further research. For instance, the authors note that the performance of LLMs may be sensitive to the specific dataset and task, and that further work is needed to ensure the robustness and generalizability of the models across different educational contexts.
Additionally, the paper does not address potential ethical concerns, such as the risk of bias or the privacy implications of using large language models to process sensitive survey data. These are important considerations that should be explored in future research.
Overall, the paper presents a strong foundation for using LLMs in educational survey feedback analysis, but there are still opportunities to refine and expand the research to address these critical issues.
Conclusion
This paper highlights the promising potential of large language models in the domain of educational survey data analysis. By leveraging the natural language understanding and generation capabilities of LLMs, the researchers have demonstrated that these models can effectively tackle tasks such as sentiment analysis, topic modeling, and summarization, which are crucial for extracting meaningful insights from open-ended survey responses.
The findings of this study suggest that LLMs could be a valuable tool for educators and administrators, enabling them to more efficiently and effectively process and interpret feedback from students, teachers, and other stakeholders. This could lead to more informed decision-making and ultimately contribute to the improvement of educational systems.
While the paper presents a compelling case, it also identifies areas for further research and consideration of potential ethical implications. Continued exploration of LLM-based approaches in this domain, with a focus on robustness, generalizability, and responsible implementation, could unlock even greater benefits for the education sector.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Fan Gao, Hang Jiang, Rui Yang, Qingcheng Zeng, Jinghui Lu, Moritz Blum, Dairui Liu, Tianwei She, Yuang Jiang, Irene Li
0
0
Educational materials such as survey articles in specialized fields like computer science traditionally require tremendous expert inputs and are therefore expensive to create and update. Recently, Large Language Models (LLMs) have achieved significant success across various general tasks. However, their effectiveness and limitations in the education domain are yet to be fully explored. In this work, we examine the proficiency of LLMs in generating succinct survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics. Automated benchmarks reveal that GPT-4 surpasses its predecessors, inluding GPT-3.5, PaLM2, and LLaMa2 by margins ranging from 2% to 20% in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors. At last, we compared the rating behavior between humans and GPT-4 and found systematic bias in using GPT evaluation.
5/24/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024
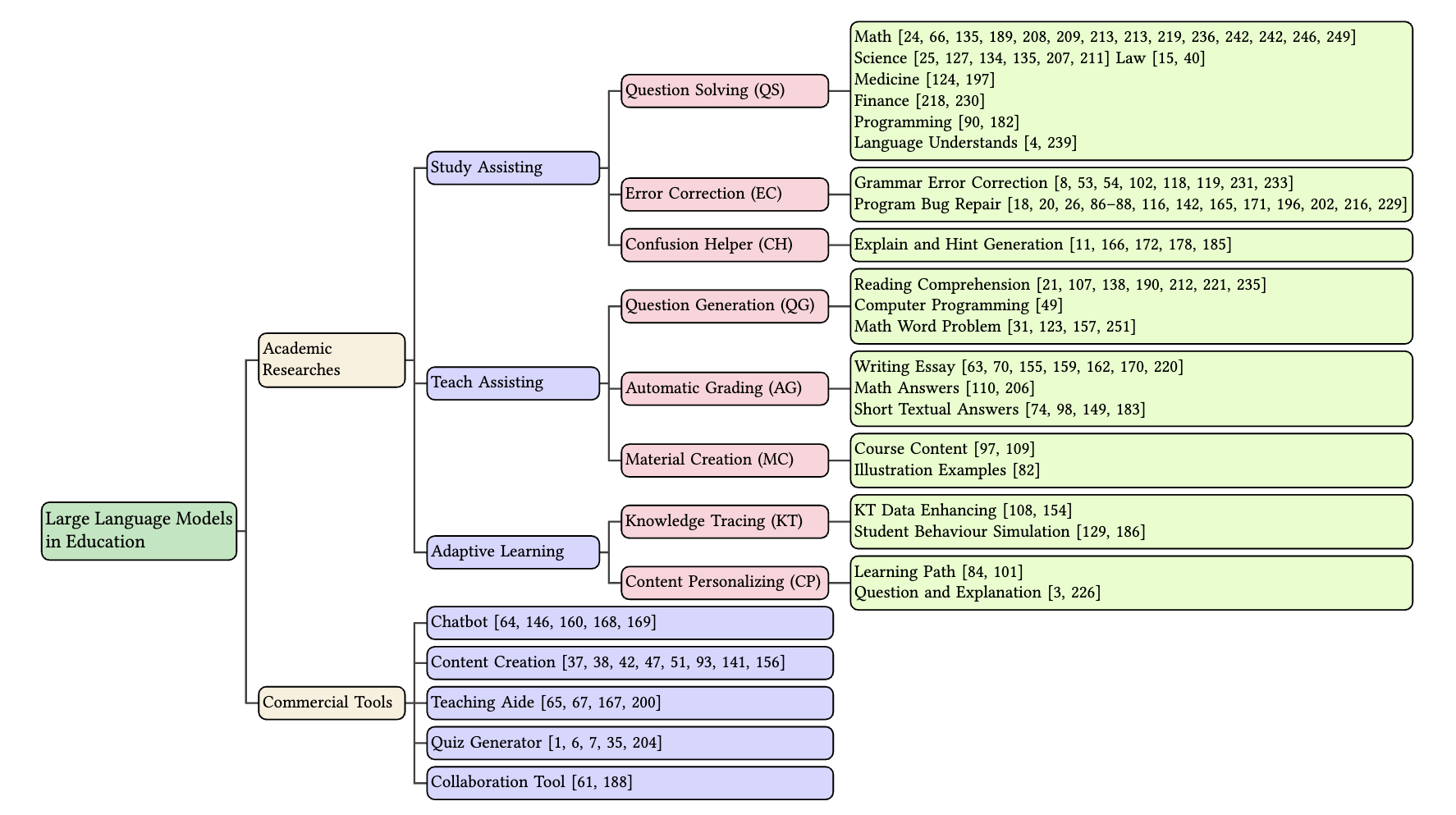
Large Language Models for Education: A Survey and Outlook
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, Qingsong Wen
0
0
The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
4/3/2024
💬
Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
Charles Koutcheme, Nicola Dainese, Sami Sarsa, Arto Hellas, Juho Leinonen, Paul Denny
0
0
Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
5/9/2024