Large Language Models are Good Prompt Learners for Low-Shot Image Classification
2312.04076
0
0

Abstract
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how large language models (LLMs) can be used as effective prompt learners for low-shot image classification tasks.
- The researchers investigate the ability of LLMs to rapidly adapt to new image classification tasks by learning prompts from just a few labeled examples.
- The findings suggest that LLMs can outperform specialized image classification models when given limited training data, making them a promising approach for low-resource settings.
Plain English Explanation
Imagine you want to build an AI system that can identify different types of animals in images. Normally, you would need to train a specialized machine learning model on thousands of labeled images to get good results. However, this can be time-consuming and expensive, especially if you don't have access to a large dataset.
This paper shows that you can use a different kind of AI system, called a large language model (LLM), to quickly learn how to classify images with just a few examples. LLMs are trained on vast amounts of text data, which allows them to develop a deep understanding of language and the world. By presenting the LLM with a few labeled images and some text describing the task, the researchers found that the LLM could learn to classify new images with high accuracy.
This is a powerful idea because it means you don't need to build a specialized image classification model from scratch. Instead, you can leverage the knowledge and capabilities of an LLM, which has already been trained on a huge amount of data. This makes the process of building image classification systems much faster and more efficient, especially when you only have a small amount of training data available.
Technical Explanation
The key elements of the paper's approach are:
-
Prompt Engineering: The researchers used prompt engineering techniques to convert image classification tasks into text-based prompts that could be processed by the LLM. This involved describing the task and providing a few labeled examples in natural language.
-
Model Architecture: The paper experiments with different LLM architectures, including GPT-3 and FLAN, to assess their performance on low-shot image classification tasks.
-
Evaluation: The researchers evaluated the LLMs' performance on a variety of image classification benchmarks, including ImageNet and CIFAR-10, and compared their results to specialized image classification models trained on the same limited data.
The results show that the LLMs were able to outperform the specialized models when given just 1-5 labeled examples per class. This suggests that LLMs can effectively learn task-specific prompts and apply their general knowledge to solve image classification problems, even with limited training data.
Critical Analysis
The paper acknowledges some potential limitations of the approach, such as the need for careful prompt engineering to ensure the LLM understands the task correctly. Additionally, the researchers note that the performance of the LLMs may be sensitive to the specific prompts used and the characteristics of the image datasets.
While the results are promising, further research is needed to understand the broader applicability of this approach. For example, it would be interesting to see how the LLMs perform on more complex image classification tasks or how their performance compares to specialized models with access to larger training datasets.
Additionally, the paper does not explore potential biases or ethical considerations that may arise from using LLMs for image classification tasks. As these models become more widely adopted, it will be important to carefully evaluate their societal impacts and ensure they are being used responsibly.
Conclusion
This paper demonstrates that large language models can be effective prompt learners for low-shot image classification tasks, outperforming specialized models when given limited training data. This finding has important implications for the development of efficient and flexible AI systems, particularly in settings where data is scarce.
By leveraging the general knowledge and adaptability of LLMs, researchers and practitioners may be able to build powerful image classification systems more quickly and with fewer resources. This could lead to new applications and use cases for AI, particularly in areas where data collection and curation are challenging.
However, as with any emerging technology, it will be crucial to carefully consider the ethical and societal implications of using LLMs for image classification and other tasks. Continued research and responsible development will be key to ensuring these powerful AI systems are deployed in a way that benefits society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Language Models as Black-Box Optimizers for Vision-Language Models
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
0
0
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
5/15/2024
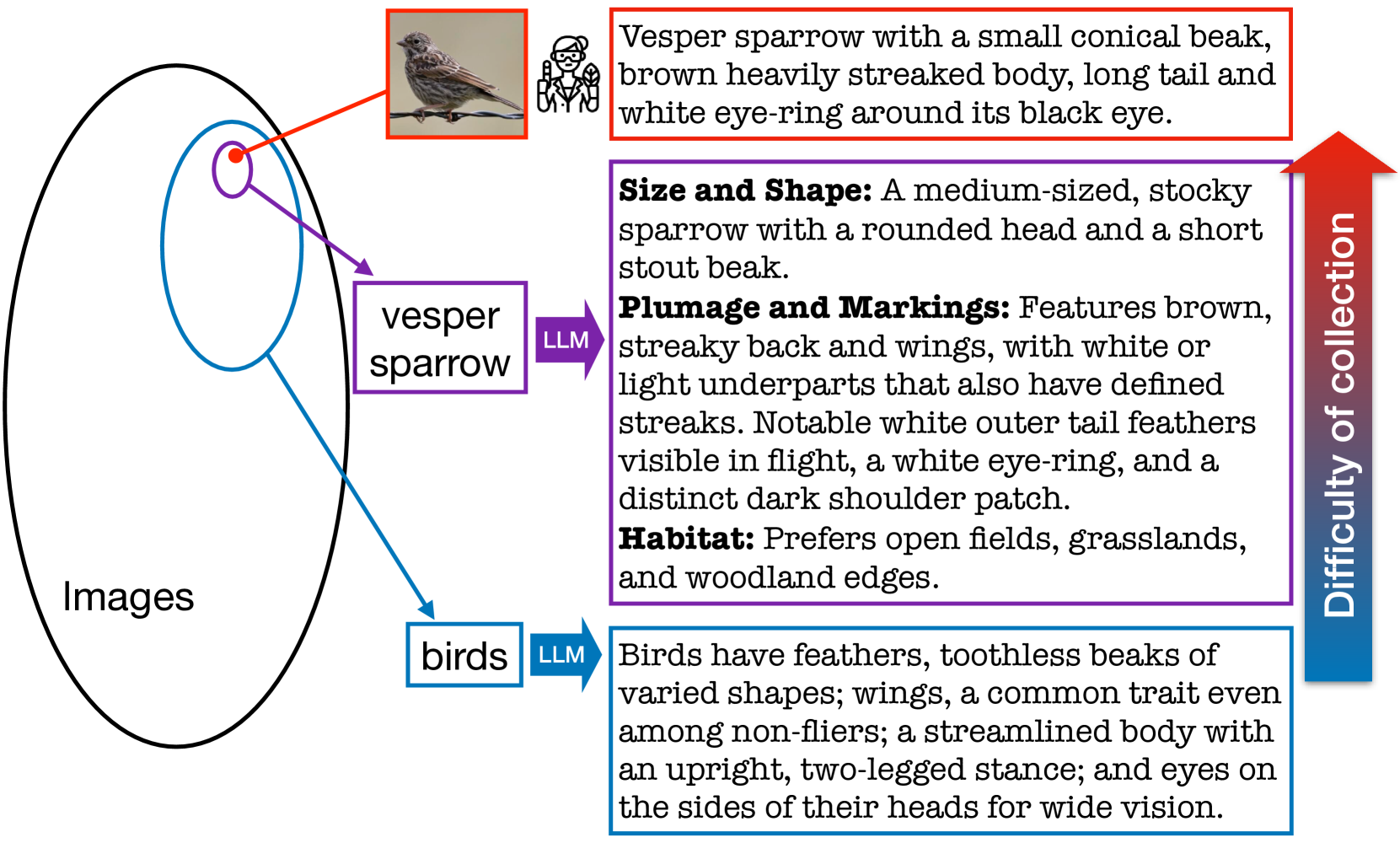
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024
💬
Large Language Model Enhanced Machine Learning Estimators for Classification
Yuhang Wu, Yingfei Wang, Chu Wang, Zeyu Zheng
0
0
Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
5/10/2024
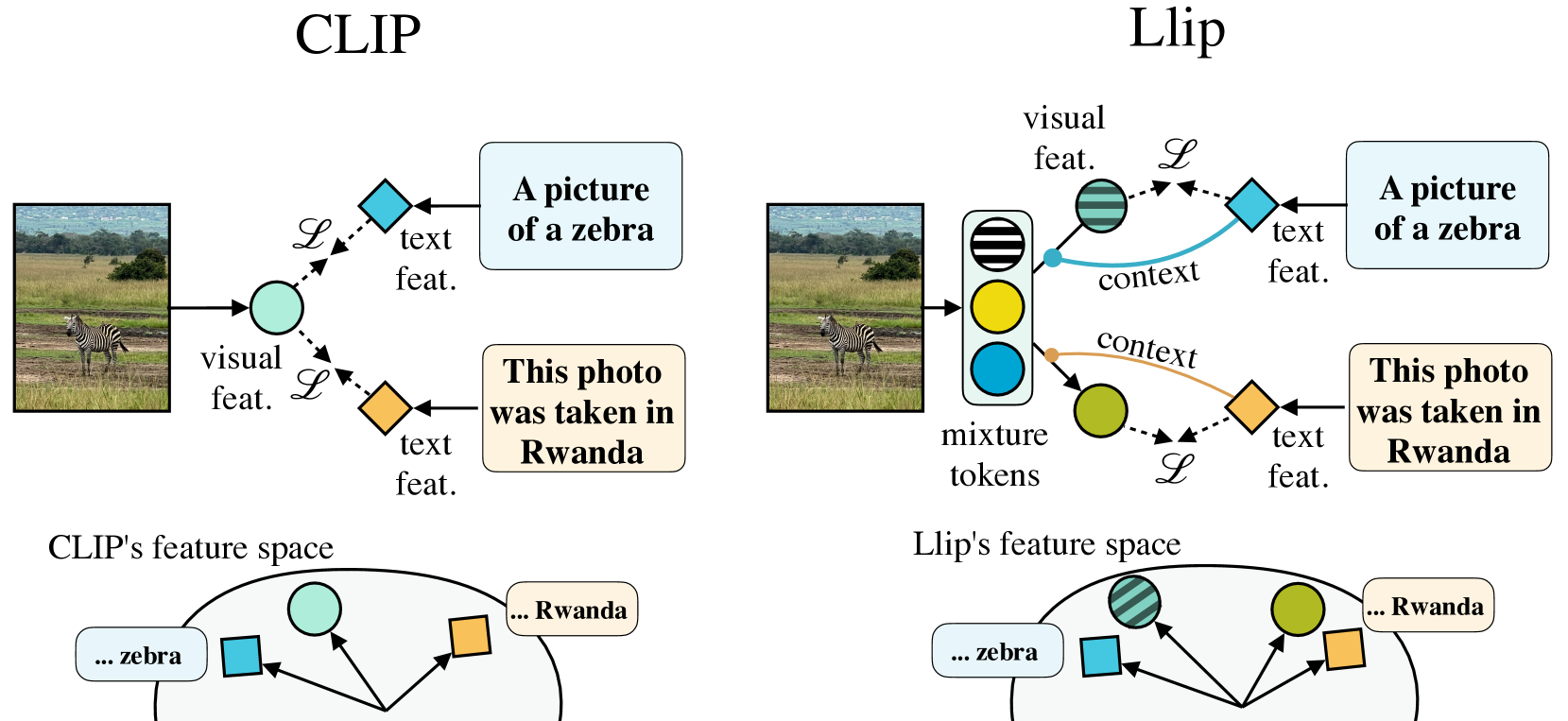
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024