Language Models as Black-Box Optimizers for Vision-Language Models
2309.05950
0
0
💬
Abstract
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
Create account to get full access
Overview
- The paper explores a black-box approach to optimize vision-language models (VLMs) through natural language prompts, without accessing model parameters or feature embeddings.
- The approach uses chat-based large language models (LLMs) to search for effective prompts, employing an automatic hill-climbing procedure that converges to prompts that improve VLM performance.
- The proposed method outperforms white-box continuous prompting and human-engineered or LLM-generated prompts in a challenging 1-shot image classification setup.
- The approach also demonstrates transferability across different VLM architectures and is applied to optimize the state-of-the-art black-box VLM, DALL-E 3, for text-to-image generation, prompt inversion, and personalization.
Plain English Explanation
Vision-language models (VLMs) are AI systems that can understand and generate text based on visual inputs, such as images. These models are trained on vast datasets of images and text from the internet, allowing them to perform a wide range of tasks, from image captioning to visual question answering.
However, many VLMs are built using proprietary data and are not open-source, which means researchers and developers can't easily access the model's internal workings, such as the parameters or feature representations. This makes it challenging to fine-tune or optimize these models for specific tasks or applications.
To address this, the researchers in this paper propose a "black-box" approach, which means they don't need to access the model's internal details. Instead, they use a chat-based language model (like the ones used in chatbots) to help them find the best text prompts to improve the VLM's performance.
The key idea is to have the language model provide feedback on different prompts, and then use that feedback to gradually refine and improve the prompts. This allows the researchers to optimize the VLM without needing to understand its inner workings.
In their experiments, the researchers show that this black-box prompt optimization approach outperforms other methods, including ones that do require access to the model's internal details. They also demonstrate that the prompts generated by their approach are more interpretable and can be transferred to other VLM architectures.
Finally, the researchers apply their framework to optimize the state-of-the-art black-box VLM, DALL-E 3, for text-to-image generation, prompt inversion, and personalization, further showcasing the versatility of their approach.
Technical Explanation
The paper presents a novel black-box approach to optimize vision-language models (VLMs) through natural language prompts, without the need to access model parameters, feature embeddings, or output logits. The key idea is to employ chat-based large language models (LLMs) to search for effective prompts in a conversational process.
Specifically, the researchers adopt an automatic hill-climbing procedure, where the current prompts are evaluated on the VLM, and the LLM is then asked to refine them based on textual feedback, all within a closed-loop system without human intervention. This allows the approach to converge to prompts that improve the VLM's performance.
In a challenging 1-shot image classification setup, the proposed method surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets, including ImageNet. The approach also outperforms both human-engineered and LLM-generated prompts.
The researchers highlight the advantage of the conversational feedback, which incorporates both positive and negative prompts. This suggests that LLMs can utilize the implicit gradient direction in the textual feedback to guide a more efficient search for effective prompts.
Additionally, the paper demonstrates that the text prompts generated through this strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, the researchers apply their framework to optimize the state-of-the-art black-box VLM, DALL-E 3, for text-to-image generation, prompt inversion, and personalization.
Critical Analysis
The paper presents a compelling approach to optimize VLMs without requiring access to their internal workings, which is a significant limitation for many existing fine-tuning methods. The use of chat-based LLMs to search for effective prompts through a conversational process is a clever and innovative solution.
One potential limitation of the approach is that it relies on the performance of the underlying LLM used for the prompt search. If the LLM has biases or limitations in its language understanding or generation capabilities, this could lead to suboptimal prompts being generated. Additionally, the hill-climbing procedure may not always converge to the global optimum, and could potentially get stuck in local minima.
Moreover, the paper focuses on 1-shot image classification, which is a specific and challenging task. It would be valuable to see how the approach performs on a wider range of VLM tasks, such as image captioning, visual question answering, or multimodal reasoning.
Another area for further research could be investigating the interpretability and transferability of the generated prompts in more depth. The paper suggests that the prompts are more interpretable, but it would be helpful to understand the specific factors that contribute to this interpretability and how it could be further improved.
Despite these potential limitations, the paper makes a significant contribution to the field of VLM optimization by introducing a novel black-box approach that outperforms existing methods. The ability to optimize VLMs without accessing their internal details opens up new possibilities for a wider range of applications and researchers to benefit from these powerful models.
Conclusion
The paper presents a novel black-box approach to optimize vision-language models (VLMs) through natural language prompts, without the need to access model parameters or feature embeddings. By employing chat-based large language models (LLMs) to search for effective prompts in a conversational process, the researchers demonstrate that their approach can outperform both white-box continuous prompting and human-engineered or LLM-generated prompts.
The key advantages of this approach are its transferability across different VLM architectures and the interpretability of the generated prompts. Additionally, the researchers apply their framework to optimize the state-of-the-art black-box VLM, DALL-E 3, for diverse tasks such as text-to-image generation, prompt inversion, and personalization.
This work represents an important step towards making VLMs more accessible and customizable for a wider range of applications and users, without the need to understand the inner workings of these complex models. The proposed approach could pave the way for more efficient and user-friendly optimization of VLMs, ultimately driving further advancements in multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Verbalized Machine Learning: Revisiting Machine Learning with Language Models
Tim Z. Xiao, Robert Bamler, Bernhard Scholkopf, Weiyang Liu
0
0
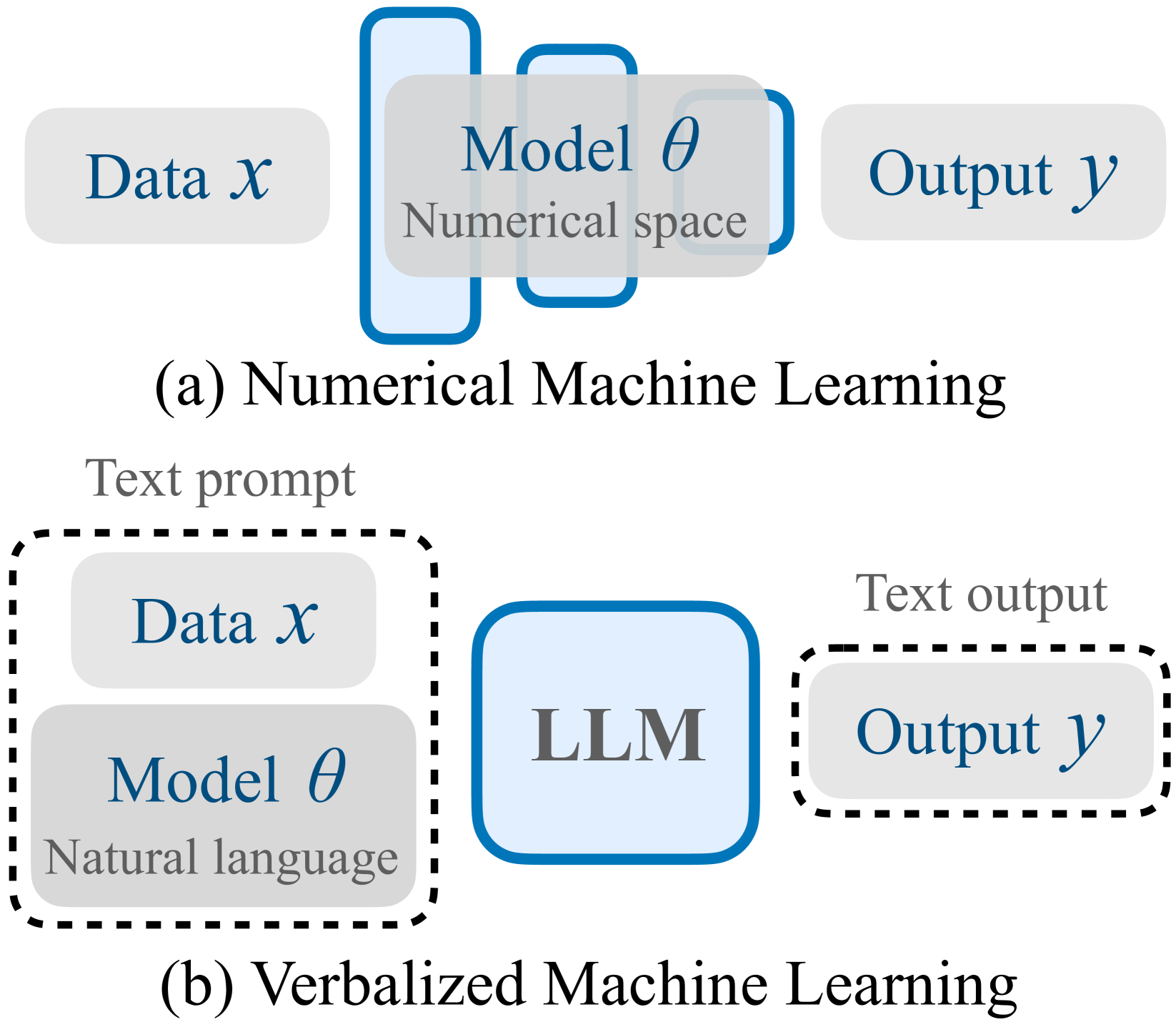
Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
6/7/2024

Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
0
0
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
4/4/2024
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
0
0
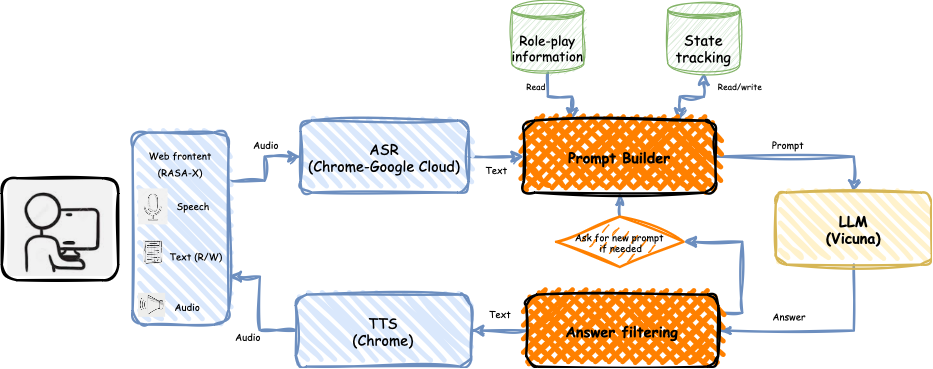
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
6/27/2024
🛸
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, Tieniu Tan
0
0
With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model's parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a textbf{C}ollabotextbf{ra}tive textbf{F}ine-textbf{T}uning (textbf{CraFT}) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62% compared to the white-box method. Our code is publicly available at https://github.com/mrflogs/CraFT .
6/4/2024