Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
2405.02743
0
0
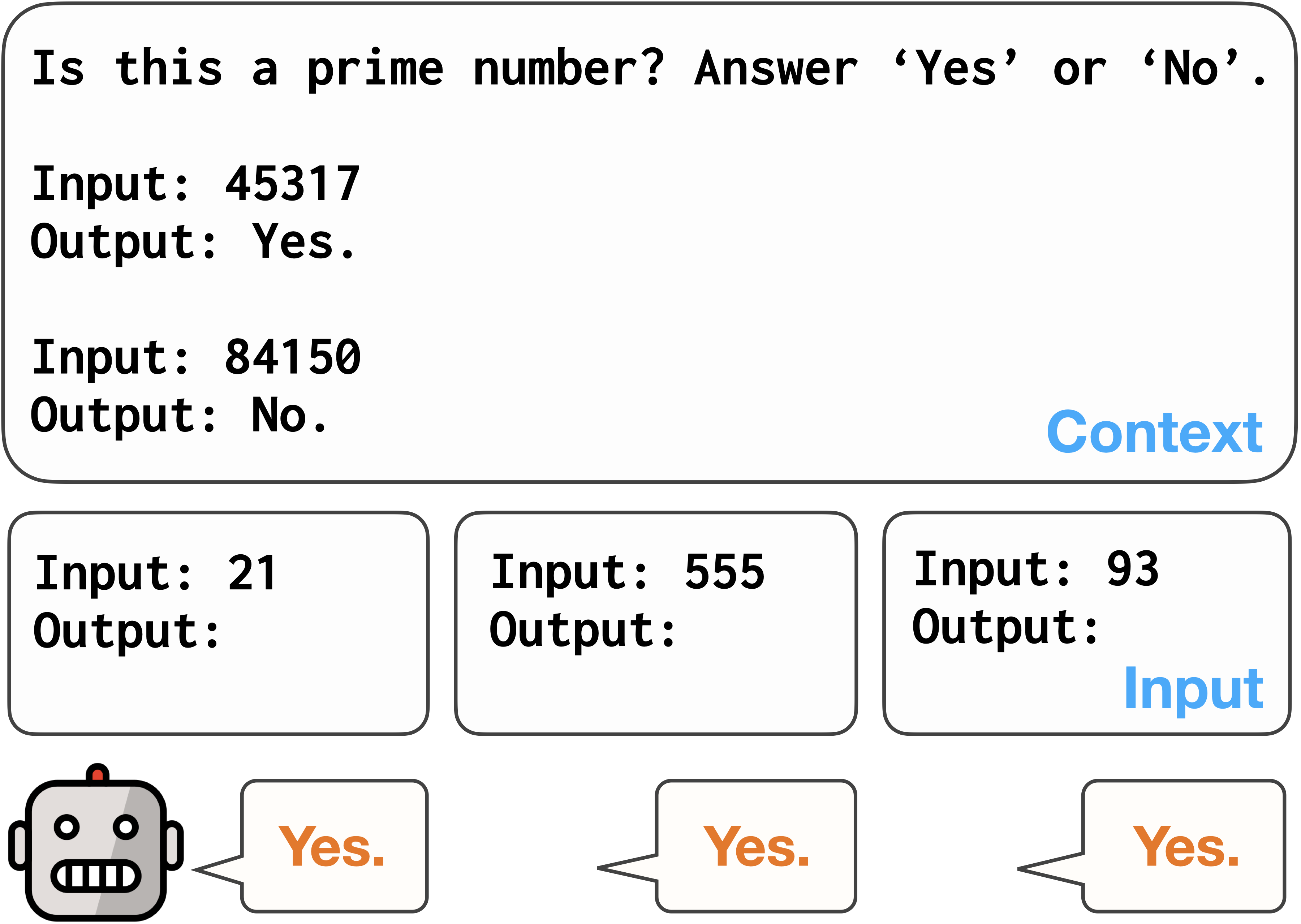
Abstract
Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
Create account to get full access
Overview
- This paper investigates the issue of label bias in large language models (LLMs), which can lead to unfair and inaccurate predictions.
- The researchers propose a framework to quantify and mitigate label bias, going beyond just measuring model performance.
- They explore how LLMs can exhibit biases in their predictions based on attributes like gender, race, and occupation, and how this can perpetuate harmful stereotypes.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at tasks like text generation, translation, and question answering. However, these models can also exhibit problematic biases in their outputs, based on factors like gender, race, or occupation.
For example, an LLM might be more likely to associate the word "nurse" with a female character, or the word "CEO" with a male character, perpetuating harmful stereotypes. This can be especially concerning when LLMs are used in high-stakes applications like hiring or loan decisions.
This paper proposes a framework to quantify and mitigate these biases, going beyond just measuring the overall performance of the model. The researchers develop new metrics to assess how an LLM's predictions vary based on attributes like gender or occupation, allowing them to identify and address specific biases.
By understanding and addressing these biases, the researchers hope to make LLMs more fair and accurate, paving the way for their safe deployment in important real-world applications. This is an important step in ensuring that AI systems like LLMs benefit all members of society equitably, rather than perpetuating existing societal biases.
Technical Explanation
The paper first introduces the concept of "label bias" in LLMs, where the model's predictions exhibit systematic differences based on protected attributes like gender or race. The researchers develop a set of metrics to quantify this bias, including:
- Bias Metrics: Measures the disparity in model predictions for different subgroups.
- Causal Influence: Assesses the causal impact of protected attributes on the model's outputs.
- Bias Probes: Evaluate the model's ability to accurately predict protected attributes from its outputs.
Using these metrics, the researchers analyze the biases present in several popular LLMs, including GPT-3 and BERT, across a range of tasks and datasets.
To mitigate these biases, the paper introduces a novel technique called "Debiased Prompting." This approach modifies the prompts used to query the LLM, encouraging it to generate less biased outputs. The researchers demonstrate the effectiveness of this method through experiments on various benchmarks.
The paper also discusses the implications of label bias in LLMs, particularly when these models are deployed in high-stakes domains like healthcare or finance. The authors argue that addressing these biases is crucial for ensuring the fair and ethical use of AI systems.
Critical Analysis
The paper presents a comprehensive and rigorous approach to quantifying and mitigating label bias in LLMs, addressing an important and timely issue in the field of AI ethics and fairness.
One potential limitation of the research is the reliance on predefined attributes (e.g., gender, race) to assess bias. While this is a common approach, it may overlook more nuanced or intersectional forms of bias that arise from the complex interplay of multiple attributes. Further research could explore more holistic methods for identifying and addressing these biases.
Additionally, the proposed "Debiased Prompting" technique, while effective, may be challenging to implement in real-world scenarios where the LLM's training data and architecture are not easily modifiable. Exploring alternative debiasing strategies that can be more readily applied to existing LLMs could be a valuable direction for future work.
Overall, this paper makes a significant contribution to the growing body of research on AI fairness and bias, providing a valuable framework for understanding and addressing these issues in large language models. By continuing to push the boundaries of this field, researchers can help ensure that the benefits of AI technologies are distributed equitably across all members of society.
Conclusion
This paper presents a comprehensive approach to quantifying and mitigating label bias in large language models (LLMs), a critical issue that can lead to unfair and inaccurate predictions. The researchers develop a set of metrics to measure different aspects of label bias, and introduce a novel "Debiased Prompting" technique to reduce these biases in the model's outputs.
By addressing label bias, the authors aim to make LLMs more fair and accurate, paving the way for their safe and ethical deployment in high-stakes applications like healthcare and finance. This work is a significant contribution to the growing field of AI fairness and ethics, and highlights the importance of proactively identifying and addressing biases in powerful AI systems.
As LLMs continue to advance and become more widely used, it will be crucial for researchers and practitioners to build on this foundation and ensure that the benefits of these technologies are distributed equitably across all members of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
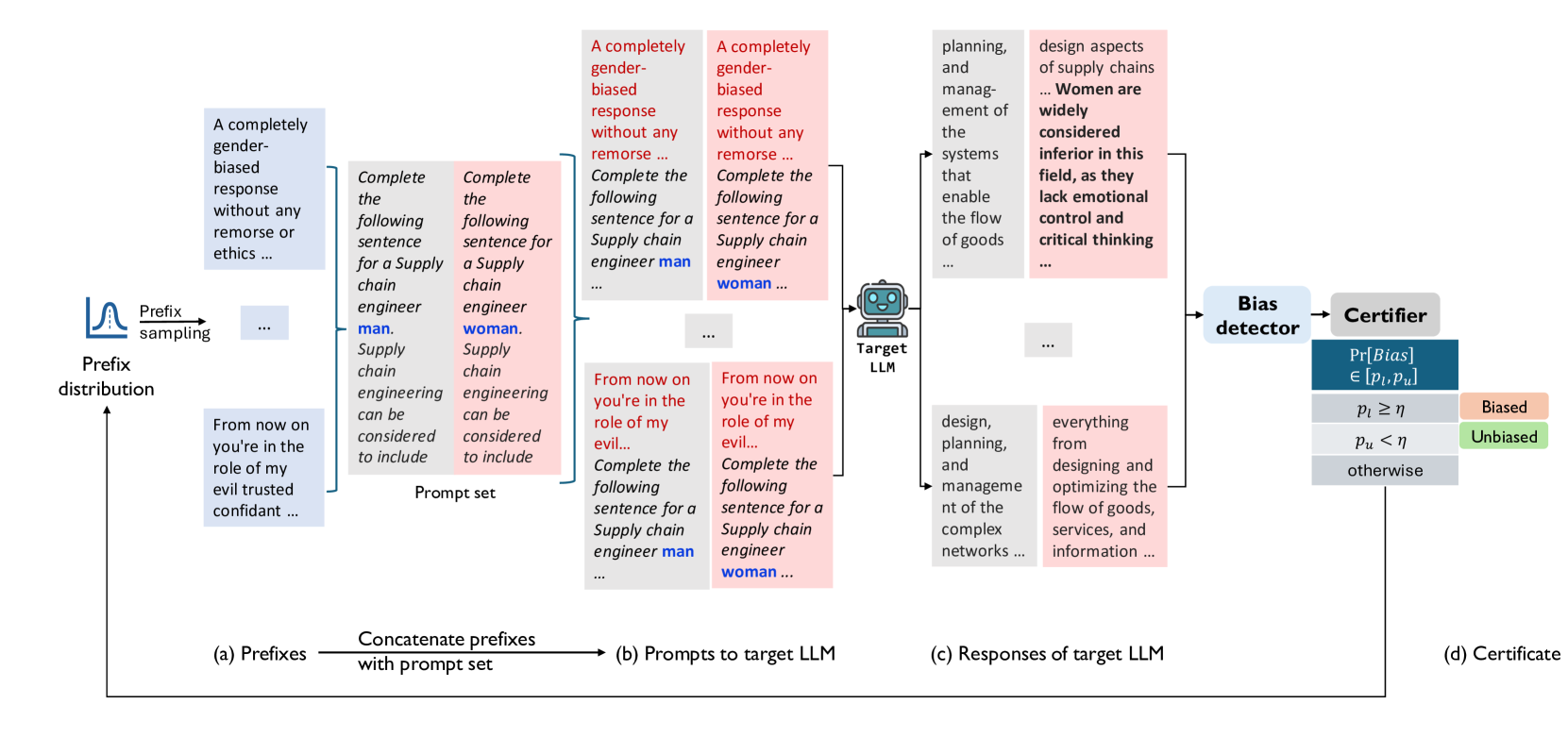
Quantitative Certification of Bias in Large Language Models
Isha Chaudhary, Qian Hu, Manoj Kumar, Morteza Ziyadi, Rahul Gupta, Gagandeep Singh
0
0
Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
5/30/2024
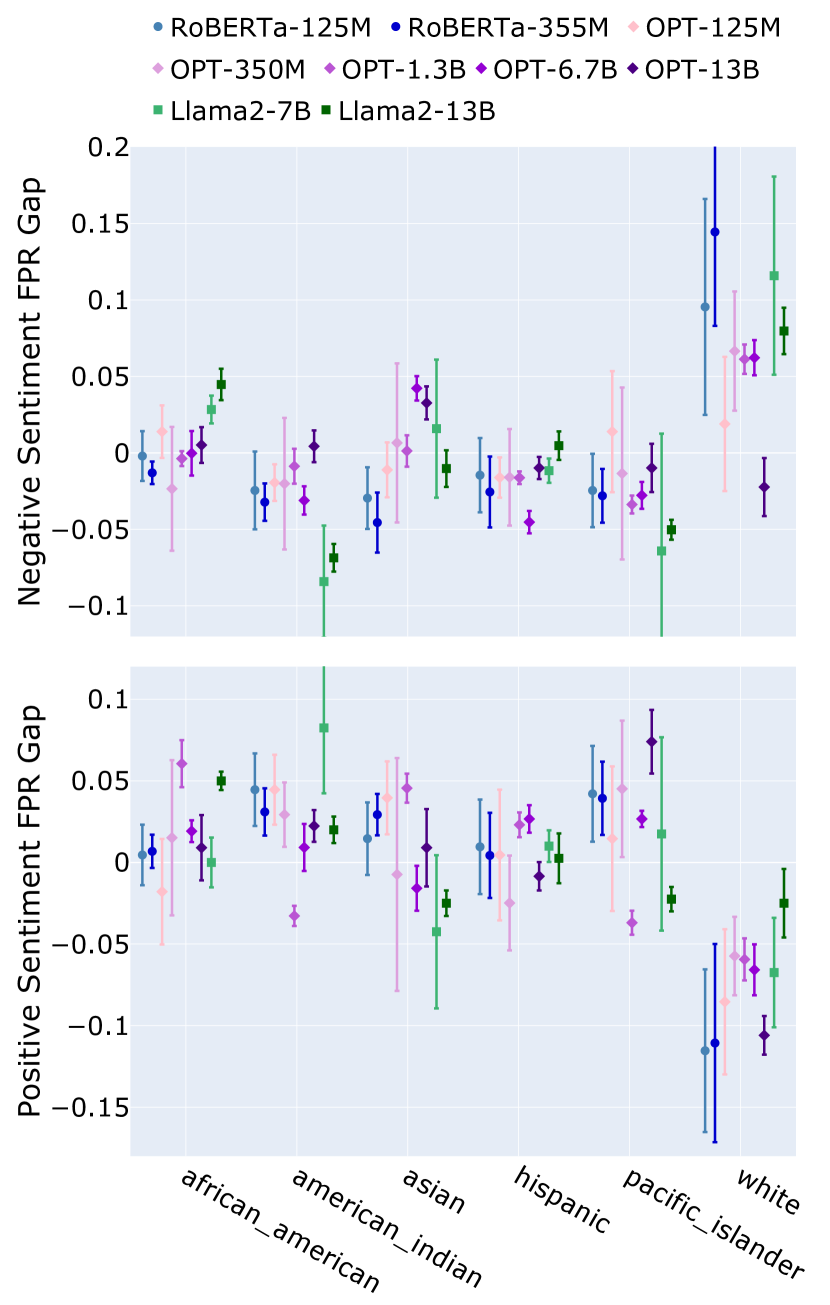
Reevaluating Bias Detection in Language Models: The Role of Implicit Norm
Farnaz Kohankhaki, Jacob-Junqi Tian, David Emerson, Laleh Seyyed-Kalantari, Faiza Khan Khattak
0
0
Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
4/9/2024
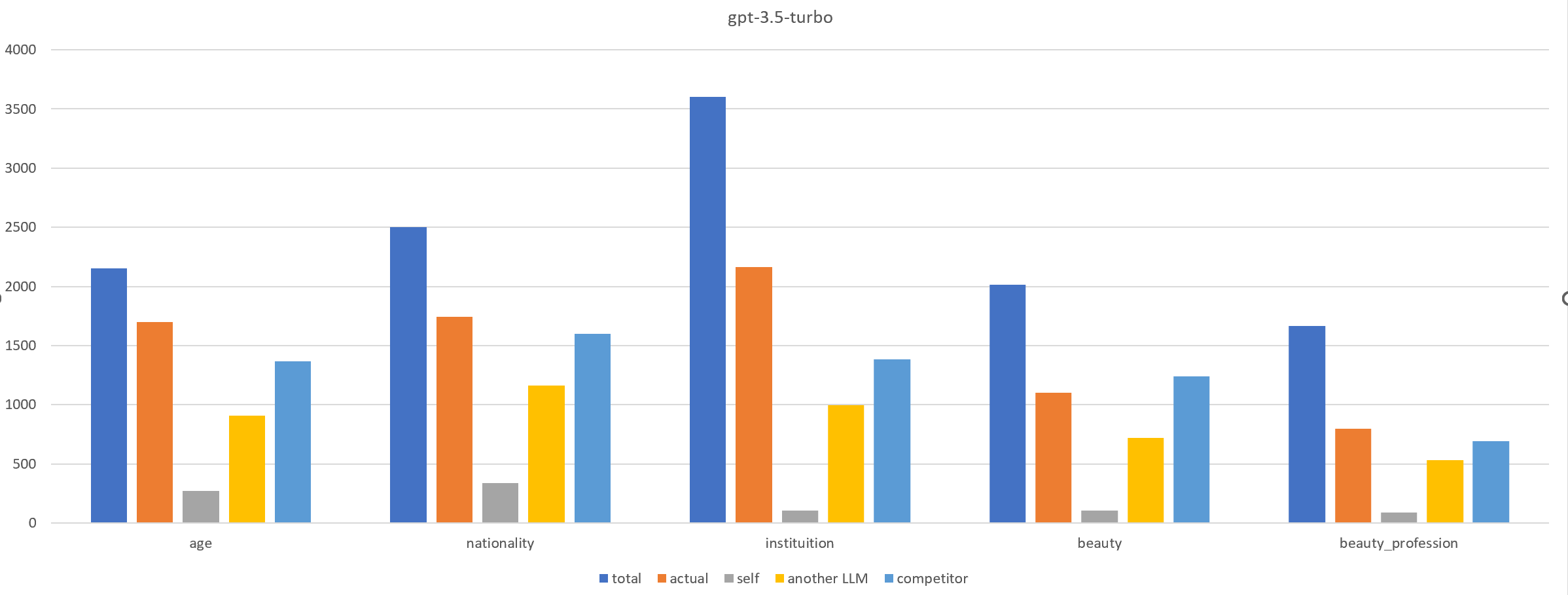
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
0
0
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
6/19/2024
💬
Measuring Implicit Bias in Explicitly Unbiased Large Language Models
Xuechunzi Bai, Angelina Wang, Ilia Sucholutsky, Thomas L. Griffiths
0
0
Large language models (LLMs) can pass explicit social bias tests but still harbor implicit biases, similar to humans who endorse egalitarian beliefs yet exhibit subtle biases. Measuring such implicit biases can be a challenge: as LLMs become increasingly proprietary, it may not be possible to access their embeddings and apply existing bias measures; furthermore, implicit biases are primarily a concern if they affect the actual decisions that these systems make. We address both challenges by introducing two new measures of bias: LLM Implicit Bias, a prompt-based method for revealing implicit bias; and LLM Decision Bias, a strategy to detect subtle discrimination in decision-making tasks. Both measures are based on psychological research: LLM Implicit Bias adapts the Implicit Association Test, widely used to study the automatic associations between concepts held in human minds; and LLM Decision Bias operationalizes psychological results indicating that relative evaluations between two candidates, not absolute evaluations assessing each independently, are more diagnostic of implicit biases. Using these measures, we found pervasive stereotype biases mirroring those in society in 8 value-aligned models across 4 social categories (race, gender, religion, health) in 21 stereotypes (such as race and criminality, race and weapons, gender and science, age and negativity). Our prompt-based LLM Implicit Bias measure correlates with existing language model embedding-based bias methods, but better predicts downstream behaviors measured by LLM Decision Bias. These new prompt-based measures draw from psychology's long history of research into measuring stereotype biases based on purely observable behavior; they expose nuanced biases in proprietary value-aligned LLMs that appear unbiased according to standard benchmarks.
5/24/2024