Evaluating Large Language Models at Evaluating Instruction Following
2310.07641
0
0
💬
Abstract
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
Create account to get full access
Overview
- This paper investigates the effectiveness of using large language models (LLMs) to evaluate how well generated text follows given instructions, a metric known as instruction following.
- The authors introduce a challenging benchmark called LLMBar, which tests an LLM evaluator's ability to discern outputs that adhere to instructions from those that diverge, even if the divergent output has deceptive qualities like a more engaging tone.
- Contrary to existing research, the authors find that different LLM evaluators (combinations of LLMs and prompts) have distinct performance on LLMBar, and even the best-performing ones have room for improvement.
- The paper also presents a novel suite of prompting strategies to help close the gap between LLM and human evaluators of instruction following.
Plain English Explanation
As artificial intelligence (AI) models called large language models (LLMs) continue to improve, researchers are exploring ways to use these LLMs to evaluate other AI systems, rather than relying on expensive and time-consuming human evaluations. One key metric for evaluating AI systems is instruction following, which looks at how closely the system's output matches the given instructions.
In this paper, the authors create a new benchmark called LLMBar to test how well LLM evaluators can distinguish between outputs that follow instructions and those that don't, even if the non-compliant output has qualities that might trick the evaluator, like a more engaging tone. Surprisingly, the authors find that different LLM evaluators (using different LLMs and prompts) perform quite differently on this benchmark, and even the best-performing ones still have room for improvement.
To address this, the researchers develop a new set of prompting strategies to help LLM evaluators get better at assessing instruction following. By creating this LLMBar benchmark and exploring new prompting approaches, the authors hope to provide insights that will lead to the development of better AI systems that can follow instructions more reliably.
Technical Explanation
The paper investigates the use of large language models (LLMs) as scalable and cost-effective alternatives to human evaluations for comparing the growing number of AI models. Specifically, the authors focus on using LLM evaluators to assess instruction following, which measures how closely the generated text adheres to the given instructions.
To test the capabilities of these LLM evaluators, the researchers introduce a new benchmark called LLMBar. LLMBar consists of 419 pairs of text outputs, where one output in each pair adheres to the instructions while the other diverges, yet may possess deceptive qualities that could mislead an LLM evaluator, such as a more engaging tone.
Contrary to previous research, the authors find that different LLM evaluators (combinations of LLMs and prompts) exhibit distinct performance on the LLMBar benchmark. Even the highest-scoring evaluators have substantial room for improvement in accurately assessing instruction following.
To address this, the paper presents a novel suite of prompting strategies that can help narrow the gap between LLM and human evaluators of instruction following. By developing the LLMBar benchmark and exploring new prompting approaches, the authors aim to provide more insights into the capabilities and limitations of LLM evaluators, ultimately contributing to the development of better instruction-following AI models.
Critical Analysis
The paper provides a thoughtful and rigorous evaluation of using LLMs as scalable alternatives to human assessments of instruction following. By introducing the LLMBar benchmark, the authors have created a valuable tool for testing the capabilities of LLM evaluators in a more challenging and realistic setting than previous research.
One potential limitation of the study is the relatively small size of the LLMBar dataset, with only 419 text output pairs. While this allowed for careful manual curation, a larger and more diverse dataset could provide additional insights. The authors acknowledge this and suggest that future work could expand the benchmark.
Additionally, the paper does not delve deeply into the specific reasons why different LLM evaluators exhibit varying performance on the LLMBar task. Further analysis of the strengths, weaknesses, and biases of different LLM architectures and prompting strategies could yield additional insights to guide the development of more robust instruction following evaluation systems.
Overall, this research makes an important contribution to the growing field of LLM evaluation and instruction following assessment. By highlighting the limitations of current LLM evaluators and proposing new prompting strategies, the authors pave the way for future work to create more reliable and predictive LLM evaluation systems.
Conclusion
This paper investigates the use of large language models (LLMs) as a scalable alternative to human evaluations for assessing instruction following, a metric that gauges how well generated text adheres to given instructions. The authors introduce a challenging benchmark called LLMBar to test the capabilities of LLM evaluators in this task.
Contrary to previous research, the authors find that different LLM evaluators exhibit distinct performance on LLMBar, and even the best-performing ones have room for improvement. To address this, the paper presents novel prompting strategies to help narrow the gap between LLM and human evaluators of instruction following.
By developing the LLMBar benchmark and exploring new prompting approaches, this research provides valuable insights to guide the development of more robust and reliable instruction-following AI models. The findings highlight the need for continued advancements in LLM evaluation methods to ensure the accurate assessment of emerging AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
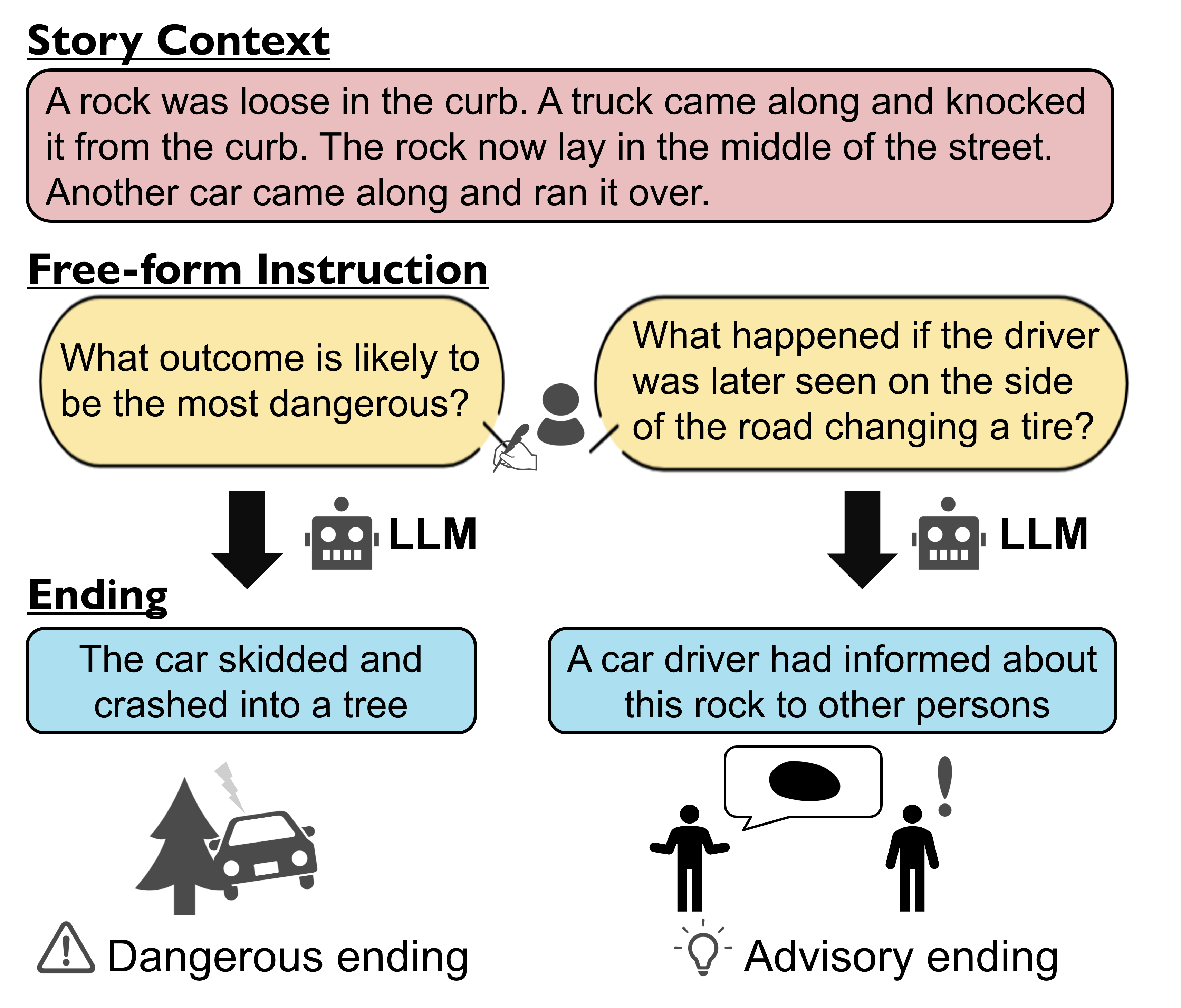
Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
Rem Hida, Junki Ohmura, Toshiyuki Sekiya
0
0
Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
6/26/2024

Large Language Models as Evaluators for Recommendation Explanations
Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, Min Zhang
0
0
The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
6/7/2024
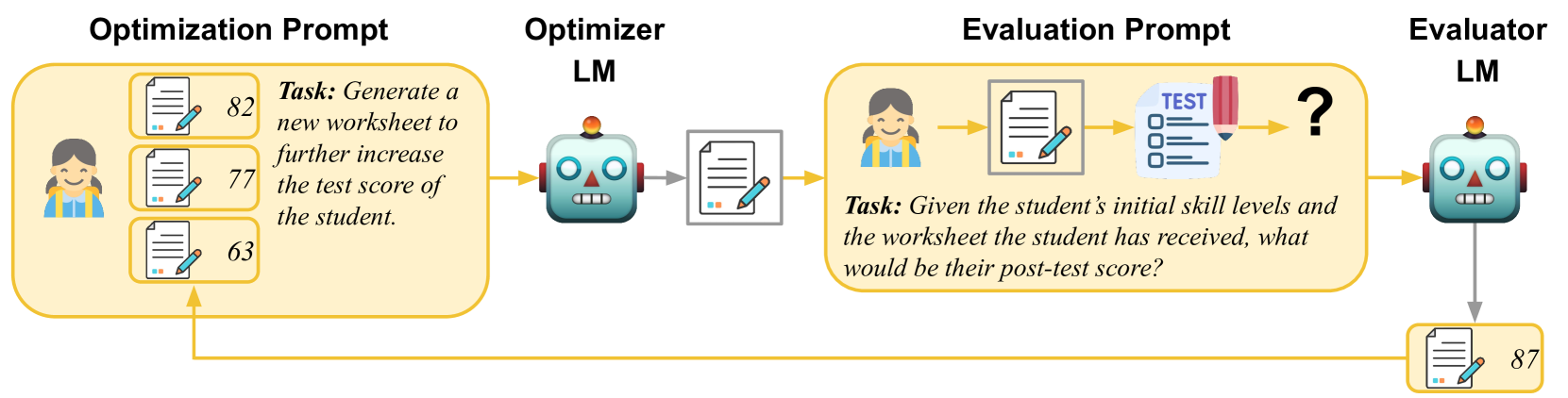
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Joy He-Yueya, Noah D. Goodman, Emma Brunskill
0
0
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
5/7/2024
💬
Large Language Models as Partners in Student Essay Evaluation
Toru Ishida, Tongxi Liu, Hailong Wang, William K. Cheung
0
0
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
5/30/2024