Large Language Models are Zero-Shot Next Location Predictors
2405.20962
0
0

Abstract
Predicting the locations an individual will visit in the future is crucial for solving many societal issues like disease diffusion and reduction of pollution among many others. The models designed to tackle next-location prediction, however, require a significant amount of individual-level information to be trained effectively. Such data may be scarce or even unavailable in some geographic regions or peculiar scenarios (e.g., cold-start in recommendation systems). Moreover, the design of a next-location predictor able to generalize or geographically transfer knowledge is still an open research challenge. Recent advances in natural language processing have led to a rapid diffusion of Large Language Models (LLMs) which have shown good generalization and reasoning capabilities. These insights, coupled with the recent findings that LLMs are rich in geographical knowledge, allowed us to believe that these models can act as zero-shot next-location predictors. This paper evaluates the capabilities of many popular LLMs in this role, specifically Llama, GPT-3.5 and Mistral 7B. After designing a proper prompt, we tested the models on three real-world mobility datasets. The results show that LLMs can obtain accuracies up to 32.4%, a significant relative improvement of over 600% when compared to sophisticated DL models specifically designed for human mobility. Moreover, we show that other LLMs are unable to perform the task properly. To prevent positively biased results, we also propose a framework inspired by other studies to test data contamination. Finally, we explored the possibility of using LLMs as text-based explainers for next-location prediction showing that can effectively provide an explanation for their decision. Notably, 7B models provide more generic, but still reliable, explanations compared to larger counterparts. Code: github.com/ssai-trento/LLM-zero-shot-NL
Create account to get full access
Overview
- This paper explores the ability of large language models (LLMs) to predict the next location a person will visit, without any specialized training on location data.
- The researchers demonstrate that LLMs can effectively perform "zero-shot" next location prediction, meaning they can make accurate predictions without being trained on location-specific datasets.
- This capability has important implications for applications like urban mobility and point-of-interest recommendation.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. In this paper, the researchers show that these powerful LLMs can also be used to predict where a person will go next, even without any specialized training on location data.
Typically, predicting a person's next location would require training a model on datasets of location-specific information, such as GPS coordinates or check-in data from social media. However, the researchers found that LLMs can make these predictions in a "zero-shot" manner, meaning they can do it without any prior training on location-related data.
This is a significant finding because it suggests that LLMs can create new knowledge by drawing insights from the broad, general information they've been trained on. Instead of relying solely on location-specific datasets, LLMs can use their understanding of language, context, and human behavior to make accurate predictions about where people will go next.
This capability could be incredibly valuable for applications like urban mobility planning and point-of-interest recommendation, where understanding people's movement patterns is crucial. By leveraging the power of LLMs, these systems could make more accurate predictions without the need for extensive data collection and model training.
Technical Explanation
The researchers conducted a series of experiments to evaluate the zero-shot next location prediction capabilities of LLMs. They used several popular LLMs, including GPT-3, GPT-J, and GPT-NeoX, and tested their performance on a variety of location-based datasets, including where-to-move-next and UrbanGPT.
The experiments involved providing the LLMs with descriptions of a person's current location and activity, and then asking the models to predict the most likely next location the person would visit. The researchers found that the LLMs were able to make surprisingly accurate predictions, often outperforming specialized models that had been trained on location-specific data.
The researchers attribute this performance to the LLMs' ability to draw on their broad understanding of language, context, and human behavior to infer patterns and make logical predictions about people's movements. By leveraging this general knowledge, the LLMs were able to generalize to new situations and make accurate predictions without relying on location-specific training data.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. For example, the performance of the LLMs may be influenced by the specific prompts and datasets used in the experiments, and the models may struggle with predicting less common or more complex location transitions.
Additionally, the researchers note that the LLMs' performance could be further improved by fine-tuning or incorporating additional location-based information, such as geographic features or transportation networks. This could help the models better capture the nuances of human mobility patterns and make even more accurate predictions.
It's also important to consider the potential ethical implications of using LLMs for next location prediction, particularly in terms of privacy and data privacy concerns. The researchers emphasize the need for careful consideration of these issues as this technology continues to develop.
Conclusion
This paper demonstrates the remarkable zero-shot next location prediction capabilities of large language models, which can make accurate predictions about where a person will go next without any specialized training on location data. This finding has important implications for a variety of applications, including urban mobility planning, point-of-interest recommendation, and beyond.
By leveraging the broad, general knowledge of LLMs, these models can draw insights and make logical inferences about human behavior and movement patterns, potentially leading to more efficient and user-friendly systems. As the field of LLM research continues to evolve, it will be important to address the ethical considerations and explore ways to further enhance the accuracy and robustness of these predictive capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
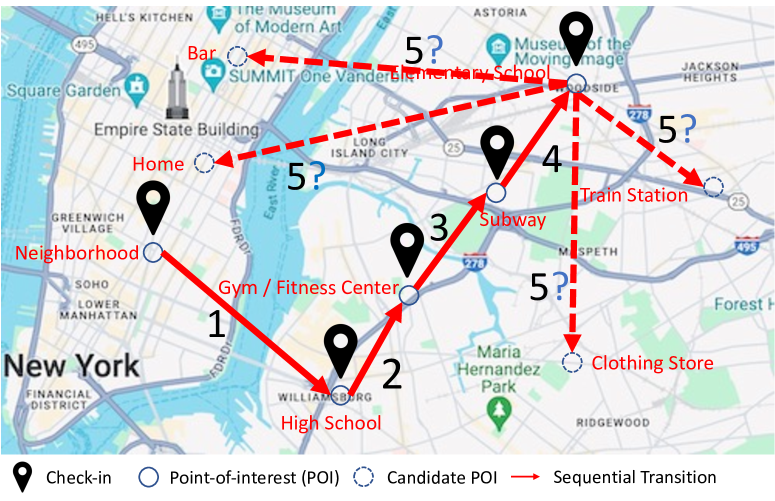
Where to Move Next: Zero-shot Generalization of LLMs for Next POI Recommendation
Shanshan Feng, Haoming Lyu, Caishun Chen, Yew-Soon Ong
0
0
Next Point-of-interest (POI) recommendation provides valuable suggestions for users to explore their surrounding environment. Existing studies rely on building recommendation models from large-scale users' check-in data, which is task-specific and needs extensive computational resources. Recently, the pretrained large language models (LLMs) have achieved significant advancements in various NLP tasks and have also been investigated for recommendation scenarios. However, the generalization abilities of LLMs still are unexplored to address the next POI recommendations, where users' geographical movement patterns should be extracted. Although there are studies that leverage LLMs for next-item recommendations, they fail to consider the geographical influence and sequential transitions. Hence, they cannot effectively solve the next POI recommendation task. To this end, we design novel prompting strategies and conduct empirical studies to assess the capability of LLMs, e.g., ChatGPT, for predicting a user's next check-in. Specifically, we consider several essential factors in human movement behaviors, including user geographical preference, spatial distance, and sequential transitions, and formulate the recommendation task as a ranking problem. Through extensive experiments on two widely used real-world datasets, we derive several key findings. Empirical evaluations demonstrate that LLMs have promising zero-shot recommendation abilities and can provide accurate and reasonable predictions. We also reveal that LLMs cannot accurately comprehend geographical context information and are sensitive to the order of presentation of candidate POIs, which shows the limitations of LLMs and necessitates further research on robust human mobility reasoning mechanisms.
4/24/2024
Large Language Models for Next Point-of-Interest Recommendation
Peibo Li, Maarten de Rijke, Hao Xue, Shuang Ao, Yang Song, Flora D. Salim
0
0
The next Point of Interest (POI) recommendation task is to predict users' immediate next POI visit given their historical data. Location-Based Social Network (LBSN) data, which is often used for the next POI recommendation task, comes with challenges. One frequently disregarded challenge is how to effectively use the abundant contextual information present in LBSN data. Previous methods are limited by their numerical nature and fail to address this challenge. In this paper, we propose a framework that uses pretrained Large Language Models (LLMs) to tackle this challenge. Our framework allows us to preserve heterogeneous LBSN data in its original format, hence avoiding the loss of contextual information. Furthermore, our framework is capable of comprehending the inherent meaning of contextual information due to the inclusion of commonsense knowledge. In experiments, we test our framework on three real-world LBSN datasets. Our results show that the proposed framework outperforms the state-of-the-art models in all three datasets. Our analysis demonstrates the effectiveness of the proposed framework in using contextual information as well as alleviating the commonly encountered cold-start and short trajectory problems.
4/30/2024

Language Models as Zero-Shot Trajectory Generators
Teyun Kwon, Norman Di Palo, Edward Johns
0
0
Large Language Models (LLMs) have recently shown promise as high-level planners for robots when given access to a selection of low-level skills. However, it is often assumed that LLMs do not possess sufficient knowledge to be used for the low-level trajectories themselves. In this work, we address this assumption thoroughly, and investigate if an LLM (GPT-4) can directly predict a dense sequence of end-effector poses for manipulation tasks, when given access to only object detection and segmentation vision models. We designed a single, task-agnostic prompt, without any in-context examples, motion primitives, or external trajectory optimisers. Then we studied how well it can perform across 30 real-world language-based tasks, such as open the bottle cap and wipe the plate with the sponge, and we investigated which design choices in this prompt are the most important. Our conclusions raise the assumed limit of LLMs for robotics, and we reveal for the first time that LLMs do indeed possess an understanding of low-level robot control sufficient for a range of common tasks, and that they can additionally detect failures and then re-plan trajectories accordingly. Videos, prompts, and code are available at: https://www.robot-learning.uk/language-models-trajectory-generators.
6/19/2024

Large Language Models Are Zero-Shot Time Series Forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, Andrew Gordon Wilson
0
0
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
6/19/2024