Large Language Models Are Zero-Shot Time Series Forecasters
2310.07820
141
0

Abstract
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
Create account to get full access
Overview
- Large language models (LLMs) like GPT-3 can be used as zero-shot time series forecasters, without any specialized training on forecasting tasks.
- The paper introduces LLMTime, a framework that allows LLMs to generate forecasts for time series data.
- Experiments show that LLMs can outperform traditional forecasting models on a variety of tasks, including macroeconomic and financial time series.
- The research suggests that LLMs possess inherent time series understanding and forecasting capabilities, making them a powerful and versatile tool for a range of forecasting applications.
Plain English Explanation
The paper explores the surprising finding that large language models (LLMs) like GPT-3, which are trained on general text data, can be used to forecast time series data without any specialized training.
The authors introduce LLMTime, a framework that allows LLMs to generate forecasts for time series data. The key insight is that LLMs can understand and reason about temporal patterns in data, even though they were not explicitly trained on forecasting tasks.
Through experiments, the researchers show that LLMs can outperform traditional statistical and machine learning models on a variety of forecasting problems, including economic and financial time series. This suggests that LLMs have an innate understanding of time series data and the ability to make accurate predictions, simply by being exposed to large amounts of diverse text data during training.
The paper's findings are significant because they demonstrate that LLMs can be a powerful and versatile tool for forecasting, without requiring specialized training or domain knowledge. This could lead to new applications of LLMs in areas like financial planning, macroeconomic policy, and supply chain management.
Technical Explanation
The paper introduces a framework called LLMTime that allows large language models (LLMs) to be used as zero-shot time series forecasters. The authors hypothesize that LLMs, despite being trained on general text data, can inherently understand and reason about temporal patterns in data, and can thus generate accurate forecasts without any specialized training.
To test this hypothesis, the researchers evaluate the performance of LLMs on a range of time series forecasting tasks, including macroeconomic indicators, financial time series, and energy demand data. They compare the LLM-based forecasts to those generated by traditional statistical and machine learning models, such as ARIMA and Prophet.
The results show that LLMs can outperform these specialized forecasting models on a variety of metrics, including mean squared error and directional accuracy. The authors attribute this success to the LLMs' ability to capture complex temporal patterns and relationships in the data, which they have learned from their exposure to large amounts of diverse text during pre-training.
Additionally, the paper introduces a method called "AutoTIME", which allows the LLM to automatically adapt its forecasting approach to the specific characteristics of the time series data, further improving its performance.
Overall, the paper's findings suggest that LLMs possess inherent time series understanding and forecasting capabilities, which can be leveraged for a wide range of applications without the need for specialized training or domain expertise.
Critical Analysis
The paper's findings are significant and provide a promising new direction for time series forecasting using large language models. However, there are a few caveats and areas for further research that should be considered:
-
Interpretability: While the LLM-based forecasts are effective, it can be challenging to understand the underlying reasoning and decision-making process. Further research is needed to improve the interpretability of these models and make their forecasts more transparent.
-
Robustness: The paper's experiments are conducted on a limited set of time series data, and it's unclear how well the LLM-based forecasting approach would generalize to more diverse or complex datasets. Additional testing on a wider range of time series is necessary to assess the robustness of the approach.
-
Data Efficiency: The paper does not explore the data efficiency of the LLM-based forecasting approach. It's possible that traditional forecasting models may require less training data to achieve comparable performance, which could be a practical concern in some applications.
-
Real-Time Forecasting: The paper focuses on generating forecasts using historical data, but does not investigate the use of LLMs for real-time forecasting, which may require different techniques and considerations.
Despite these limitations, the paper's findings are a significant step forward in demonstrating the potential of large language models for time series forecasting. The research suggests that LLMs can be a powerful and versatile tool for a wide range of forecasting applications, and further advancements in this area could have important implications for fields like finance, economics, and energy management.
Conclusion
The paper presents a groundbreaking discovery that large language models (LLMs) can be used as zero-shot time series forecasters, without any specialized training on forecasting tasks. The authors introduce the LLMTime framework, which allows LLMs to generate accurate forecasts for a variety of time series data, outperforming traditional forecasting models.
The research suggests that LLMs possess an inherent understanding of temporal patterns and relationships, which they have acquired through their exposure to large amounts of diverse text data during pre-training. This finding opens up new possibilities for the application of LLMs in a wide range of forecasting domains, from macroeconomics to energy management.
While the paper identifies some areas for further research, such as improving the interpretability and robustness of the LLM-based forecasting approach, the overall findings are a significant contribution to the field of time series analysis and forecasting. As LLMs continue to advance, the potential for their use in zero-shot forecasting tasks is likely to grow, with important implications for decision-making and planning in various industries and sectors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
💬
Large language models can be zero-shot anomaly detectors for time series?
Sarah Alnegheimish, Linh Nguyen, Laure Berti-Equille, Kalyan Veeramachaneni
0
0
Recent studies have shown the ability of large language models to perform a variety of tasks, including time series forecasting. The flexible nature of these models allows them to be used for many applications. In this paper, we present a novel study of large language models used for the challenging task of time series anomaly detection. This problem entails two aspects novel for LLMs: the need for the model to identify part of the input sequence (or multiple parts) as anomalous; and the need for it to work with time series data rather than the traditional text input. We introduce sigllm, a framework for time series anomaly detection using large language models. Our framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt language models to perform time series anomaly detection. We investigate two paradigms for testing the abilities of large language models to perform the detection task. First, we present a prompt-based detection method that directly asks a language model to indicate which elements of the input are anomalies. Second, we leverage the forecasting capability of a large language model to guide the anomaly detection process. We evaluated our framework on 11 datasets spanning various sources and 10 pipelines. We show that the forecasting method significantly outperformed the prompting method in all 11 datasets with respect to the F1 score. Moreover, while large language models are capable of finding anomalies, state-of-the-art deep learning models are still superior in performance, achieving results 30% better than large language models.
5/24/2024
Timer: Generative Pre-trained Transformers Are Large Time Series Models
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
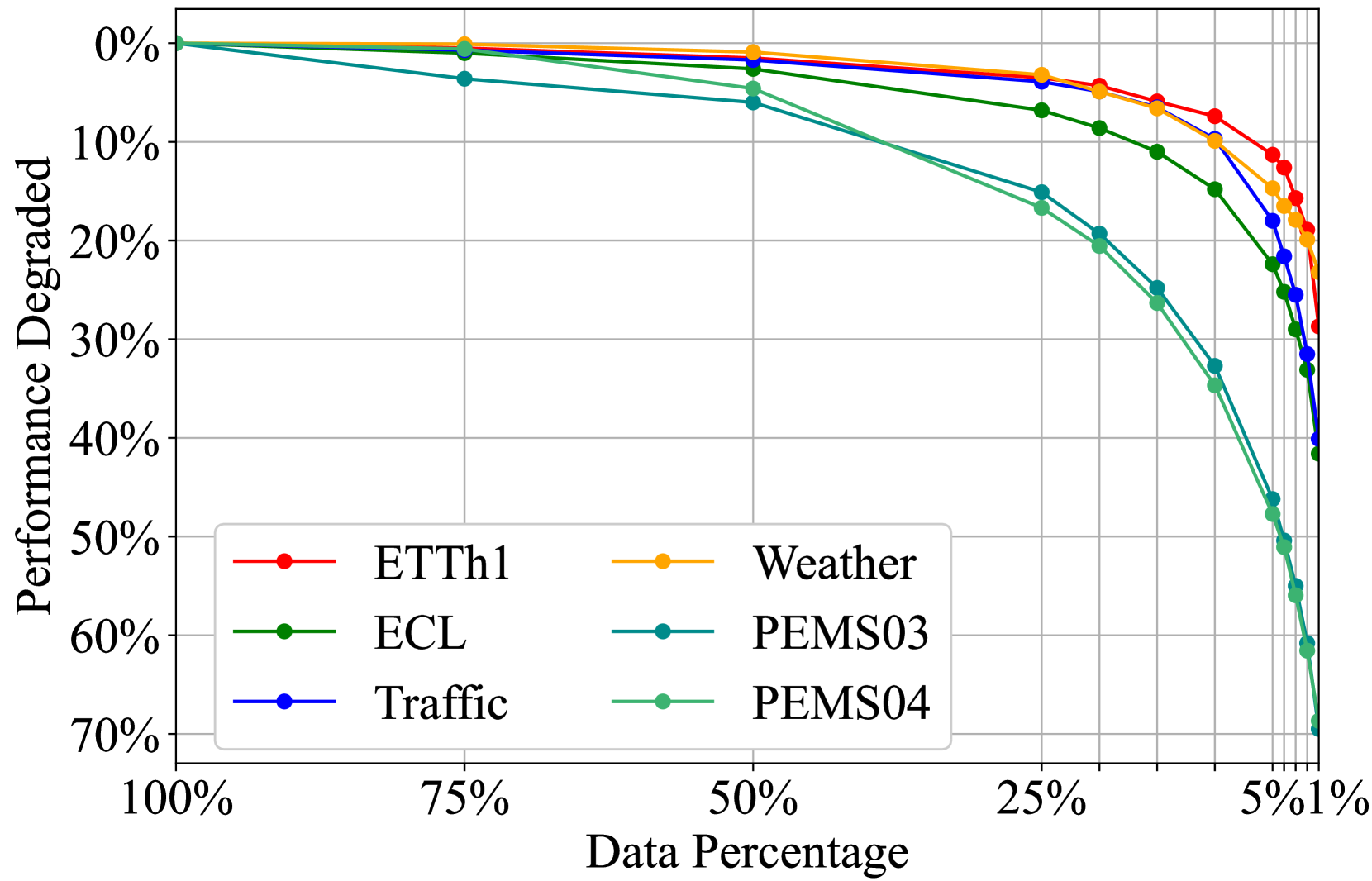
Deep learning has contributed remarkably to the advancement of time series analysis. Still, deep models can encounter performance bottlenecks in real-world data-scarce scenarios, which can be concealed due to the performance saturation with small models on current benchmarks. Meanwhile, large models have demonstrated great powers in these scenarios through large-scale pre-training. Continuous progress has been achieved with the emergence of large language models, exhibiting unprecedented abilities such as few-shot generalization, scalability, and task generality, which are however absent in small deep models. To change the status quo of training scenario-specific small models from scratch, this paper aims at the early development of large time series models (LTSM). During pre-training, we curate large-scale datasets with up to 1 billion time points, unify heterogeneous time series into single-series sequence (S3) format, and develop the GPT-style architecture toward LTSMs. To meet diverse application needs, we convert forecasting, imputation, and anomaly detection of time series into a unified generative task. The outcome of this study is a Time Series Transformer (Timer), which is generative pre-trained by next token prediction and adapted to various downstream tasks with promising capabilities as an LTSM. Code and datasets are available at: https://github.com/thuml/Large-Time-Series-Model.
6/5/2024
Position: What Can Large Language Models Tell Us about Time Series Analysis
Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen
0
0
Time series analysis is essential for comprehending the complexities inherent in various realworld systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including time series modality switching and question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
6/4/2024