Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning

0
Sign in to get full access
Overview
- Large language models (LLMs) are efficient at searching for optimal reward functions in custom-environment multi-objective reinforcement learning (MORL) tasks.
- The paper explores using LLMs to design reward functions for MORL problems, where the goal is to find a balance between multiple, potentially conflicting objectives.
- This approach could lead to more efficient and effective MORL systems compared to traditional reward function design methods.
Plain English Explanation
In the world of artificial intelligence (AI), researchers are constantly seeking ways to create systems that can navigate complex environments and achieve multiple, sometimes contradictory goals. This is the domain of multi-objective reinforcement learning (MORL).
One of the key challenges in MORL is designing the right reward function - a set of rules that guide the AI system towards the desired outcomes. Traditionally, this has been a time-consuming and often subjective process, requiring extensive domain knowledge and manual tuning.
However, the researchers in this study propose a novel approach: using large language models (LLMs) to search for and design optimal reward functions. LLMs are a type of AI model that has been trained on vast amounts of text data, allowing them to understand and generate human-like language.
The idea is that LLMs can efficiently explore the space of possible reward functions, quickly identifying those that strike the best balance between the multiple objectives in a given MORL problem. This could lead to more effective and efficient MORL systems, as the reward function design process is automated and optimized.
Technical Explanation
The paper presents a framework for using LLMs as reward function searchers in custom-environment MORL tasks. The key steps are:
-
Defining the MORL problem: The researchers start by defining the specific MORL problem they want to solve, including the environment, the multiple objectives, and the constraints.
-
Generating candidate reward functions: The LLM is used to generate a diverse set of candidate reward functions that could potentially solve the MORL problem. This is done by prompting the LLM with information about the problem and asking it to propose reward function formulations.
-
Evaluating the reward functions: The candidate reward functions are then evaluated in the custom environment, using a reinforcement learning (RL) algorithm to measure their performance across the multiple objectives.
-
Iterating and refining: The process of generating, evaluating, and refining the reward functions is repeated, with the LLM using the feedback from the previous iterations to propose increasingly better reward functions.
The researchers demonstrate the effectiveness of their approach on several MORL benchmark problems, showing that the LLM-based reward function search outperforms traditional methods in terms of efficiency and performance.
Critical Analysis
One of the key strengths of this approach is its ability to leverage the powerful language understanding and generation capabilities of LLMs to efficiently explore the space of possible reward functions. This could be particularly useful in complex, custom-environment MORL problems where traditional reward function design methods may struggle.
However, the paper does not address some potential limitations and challenges:
-
Generalization: It's not clear how well the LLM-based approach would generalize to vastly different MORL problems or environments, as the language model's performance may be heavily dependent on the specific training data and problem formulation.
-
Interpretability: The reward functions generated by the LLM may be difficult to interpret and understand, which could be a challenge for human-in-the-loop systems or applications where explainability is important.
-
Robustness: The paper does not explore the stability and robustness of the LLM-generated reward functions, which could be crucial in real-world applications where the environment or objectives may change over time.
Future research could address these issues and further explore the potential of LLMs as efficient reward function searchers in MORL and other related domains.
Conclusion
This paper presents a novel and promising approach to designing reward functions for multi-objective reinforcement learning tasks. By leveraging the capabilities of large language models, the researchers have shown that it is possible to efficiently search for and optimize reward functions that balance multiple, potentially conflicting objectives.
This work could have significant implications for the field of reinforcement learning, as it could lead to more effective and efficient systems for solving complex real-world problems. Additionally, the ideas presented in this paper could inspire further research into the use of language models in other areas of AI, such as automated task planning, decision-making, and policy generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning
Guanwen Xie, Jingzehua Xu, Yiyuan Yang, Shuai Zhang
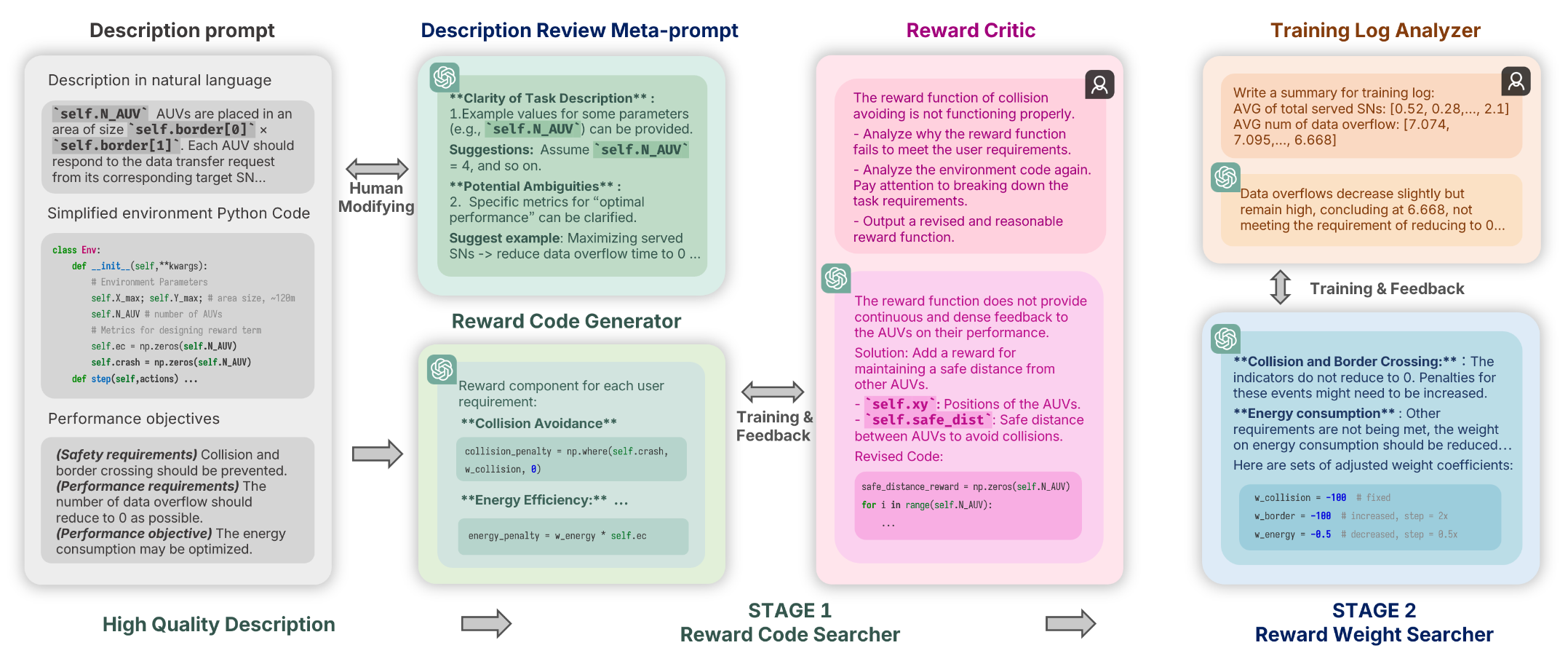
Leveraging large language models (LLMs) for designing reward functions demonstrates significant potential. However, achieving effective design and improvement of reward functions in reinforcement learning (RL) tasks with complex custom environments and multiple requirements presents considerable challenges. In this paper, we enable LLMs to be effective white-box searchers, highlighting their advanced semantic understanding capabilities. Specifically, we generate reward components for each explicit user requirement and employ the reward critic to identify the correct code form. Then, LLMs assign weights to the reward components to balance their values and iteratively search and optimize these weights based on the context provided by the training log analyzer, while adaptively determining the search step size. We applied the framework to an underwater information collection RL task without direct human feedback or reward examples (zero-shot). The reward critic successfully correct the reward code with only one feedback for each requirement, effectively preventing irreparable errors that can occur when reward function feedback is provided in aggregate. The effective initialization of weights enables the acquisition of different reward functions within the Pareto solution set without weight search. Even in the case where a weight is 100 times off, fewer than four iterations are needed to obtain solutions that meet user requirements. The framework also works well with most prompts utilizing GPT-3.5 Turbo, since it does not require advanced numerical understanding or calculation.
Read more9/5/2024
💬
0
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
Read more5/17/2024
0
Efficient Reinforcement Learning via Large Language Model-based Search
Siddhant Bhambri, Amrita Bhattacharjee, Huan Liu, Subbarao Kambhampati
Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is pronounced if there are stochastic transitions. To improve the sample efficiency, reward shaping is a well-studied approach to introduce intrinsic rewards that can help the RL agent converge to an optimal policy faster. However, designing a useful reward shaping function specific to each problem is challenging, even for domain experts. They would either have to rely on task-specific domain knowledge or provide an expert demonstration independently for each task. Given, that Large Language Models (LLMs) have rapidly gained prominence across a magnitude of natural language tasks, we aim to answer the following question: Can we leverage LLMs to construct a reward shaping function that can boost the sample efficiency of an RL agent? In this work, we aim to leverage off-the-shelf LLMs to generate a guide policy by solving a simpler deterministic abstraction of the original problem that can then be used to construct the reward shaping function for the downstream RL agent. Given the ineffectiveness of directly prompting LLMs, we propose MEDIC: a framework that augments LLMs with a Model-based feEDback critIC, which verifies LLM-generated outputs, to generate a possibly sub-optimal but valid plan for the abstract problem. Our experiments across domains from the BabyAI environment suite show 1) the effectiveness of augmenting LLMs with MEDIC, 2) a significant improvement in the sample complexity of PPO and A2C-based RL agents when guided by our LLM-generated plan, and finally, 3) pave the direction for further explorations of how these models can be used to augment existing RL pipelines.
Read more5/27/2024

0
Generating and Evolving Reward Functions for Highway Driving with Large Language Models
Xu Han, Qiannan Yang, Xianda Chen, Xiaowen Chu, Meixin Zhu
Reinforcement Learning (RL) plays a crucial role in advancing autonomous driving technologies by maximizing reward functions to achieve the optimal policy. However, crafting these reward functions has been a complex, manual process in many practices. To reduce this complexity, we introduce a novel framework that integrates Large Language Models (LLMs) with RL to improve reward function design in autonomous driving. This framework utilizes the coding capabilities of LLMs, proven in other areas, to generate and evolve reward functions for highway scenarios. The framework starts with instructing LLMs to create an initial reward function code based on the driving environment and task descriptions. This code is then refined through iterative cycles involving RL training and LLMs' reflection, which benefits from their ability to review and improve the output. We have also developed a specific prompt template to improve LLMs' understanding of complex driving simulations, ensuring the generation of effective and error-free code. Our experiments in a highway driving simulator across three traffic configurations show that our method surpasses expert handcrafted reward functions, achieving a 22% higher average success rate. This not only indicates safer driving but also suggests significant gains in development productivity.
Read more6/18/2024