Generating and Evolving Reward Functions for Highway Driving with Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of large language models to generate and evolve reward functions for autonomous highway driving.
- The authors propose a novel approach that combines natural language processing and reinforcement learning to enable autonomous vehicles to learn complex driving behaviors.
- The research aims to address the challenge of manually designing reward functions, which can be time-consuming and error-prone, by leveraging the capabilities of large language models.
Plain English Explanation
The paper focuses on the problem of creating reward functions for autonomous driving systems. Reward functions are a crucial component of reinforcement learning, which is a type of machine learning where an agent (in this case, an autonomous vehicle) learns to make decisions by receiving rewards or punishments for its actions.
Traditionally, designing these reward functions has been a manual and challenging process, as it requires carefully specifying the desired driving behaviors. The authors of this paper propose a new approach that uses large language models, which are powerful artificial intelligence systems that can understand and generate human-like text.
The idea is to leverage the language understanding and generation capabilities of these models to automatically generate and refine reward functions for autonomous driving. This could potentially make the process of developing autonomous driving systems more efficient and flexible, as the reward functions can be iteratively improved based on the observed driving performance.
The paper presents a technical implementation of this approach, which involves training the language model on driving-related text data and then using it to generate and evolve reward functions for a simulated highway driving scenario. The results suggest that this approach can produce effective reward functions that enable the autonomous vehicle to learn complex driving behaviors, such as lane changing, merging, and responding to other vehicles on the road.
Technical Explanation
The paper presents a novel approach for generating and evolving reward functions for autonomous highway driving using large language models.
The key elements of the paper are:
-
Reward Function Generation: The authors leverage a large language model, specifically a GPT-3 model, to generate natural language descriptions of desired driving behaviors. These descriptions are then converted into numerical reward functions that can be used by the reinforcement learning agent (the autonomous vehicle) to learn the desired behaviors.
-
Reward Function Evolution: The paper also introduces a reward function evolution mechanism, where the initial reward function is iteratively updated based on the observed performance of the autonomous vehicle. This allows the system to adapt and refine the reward function over time, potentially leading to more sophisticated and effective driving behaviors.
-
Simulation Experiments: The proposed approach is evaluated in a simulated highway driving environment, where the autonomous vehicle is trained to navigate the highway, including tasks such as lane changing, merging, and responding to other vehicles. The results demonstrate that the language model-based reward functions can enable the vehicle to learn complex driving behaviors.
-
Comparison to Baseline Approaches: The authors compare their approach to other methods for reward function design, such as manually crafted reward functions and learning reward functions from expert demonstrations. The results show that the proposed approach can outperform these baselines in terms of driving performance and adaptability.
Critical Analysis
The paper presents a promising approach for generating and evolving reward functions for autonomous highway driving using large language models. However, there are a few potential limitations and areas for further research:
-
Simulation Environment Fidelity: The experiments are conducted in a simulated environment, which may not fully capture the complexity and unpredictability of real-world highway driving. Further validation in more realistic driving scenarios would be valuable.
-
Scalability and Generalization: The paper demonstrates the approach on a specific highway driving task. More research is needed to understand how well the language model-based reward functions can scale to more complex driving scenarios and generalize to different road environments.
-
Safety and Robustness: Autonomous driving systems must be highly reliable and safe, particularly in critical situations. The paper does not extensively discuss the safety and robustness of the proposed approach, which would be an important consideration for real-world deployment.
-
Interpretability and Explainability: The use of large language models in this context raises questions about the interpretability and explainability of the generated reward functions. Further research could explore ways to make the reward function generation process more transparent and understandable.
Despite these potential limitations, the approach presented in this paper represents an important step towards more efficient and adaptive reward function design for autonomous driving, and it opens up interesting avenues for future research in this field.
Conclusion
This paper presents a novel approach for generating and evolving reward functions for autonomous highway driving using large language models. By leveraging the natural language processing capabilities of large language models, the authors demonstrate a method to automatically create and refine reward functions for reinforcement learning-based autonomous driving systems.
The key contributions of this work include the ability to generate reward functions from textual descriptions of desired driving behaviors, as well as the introduction of a reward function evolution mechanism that allows the system to adapt and improve over time. The evaluation in a simulated highway driving environment shows promising results, with the language model-based approach outperforming other baseline methods.
While further research is needed to address the potential limitations and expand the applicability of this approach, this paper represents an important step towards more efficient and adaptive reward function design for autonomous driving systems. The integration of large language models with reinforcement learning opens up new possibilities for developing advanced autonomous driving capabilities that can better navigate the complexities of real-world driving scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating and Evolving Reward Functions for Highway Driving with Large Language Models
Xu Han, Qiannan Yang, Xianda Chen, Xiaowen Chu, Meixin Zhu
Reinforcement Learning (RL) plays a crucial role in advancing autonomous driving technologies by maximizing reward functions to achieve the optimal policy. However, crafting these reward functions has been a complex, manual process in many practices. To reduce this complexity, we introduce a novel framework that integrates Large Language Models (LLMs) with RL to improve reward function design in autonomous driving. This framework utilizes the coding capabilities of LLMs, proven in other areas, to generate and evolve reward functions for highway scenarios. The framework starts with instructing LLMs to create an initial reward function code based on the driving environment and task descriptions. This code is then refined through iterative cycles involving RL training and LLMs' reflection, which benefits from their ability to review and improve the output. We have also developed a specific prompt template to improve LLMs' understanding of complex driving simulations, ensuring the generation of effective and error-free code. Our experiments in a highway driving simulator across three traffic configurations show that our method surpasses expert handcrafted reward functions, achieving a 22% higher average success rate. This not only indicates safer driving but also suggests significant gains in development productivity.
Read more6/18/2024

0
REvolve: Reward Evolution with Large Language Models for Autonomous Driving
Rishi Hazra, Alkis Sygkounas, Andreas Persson, Amy Loutfi, Pedro Zuidberg Dos Martires
Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate human-aligned reward functions. Specifically, we study this in the challenging setting of autonomous driving (AD), wherein notions of good driving are tacit and hard to quantify. To this end, we introduce REvolve, an evolutionary framework that uses LLMs for reward design in AD. REvolve creates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. We demonstrate that agents trained on REvolve-designed rewards align closely with human driving standards, thereby outperforming other state-of-the-art baselines.
Read more6/4/2024
0
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
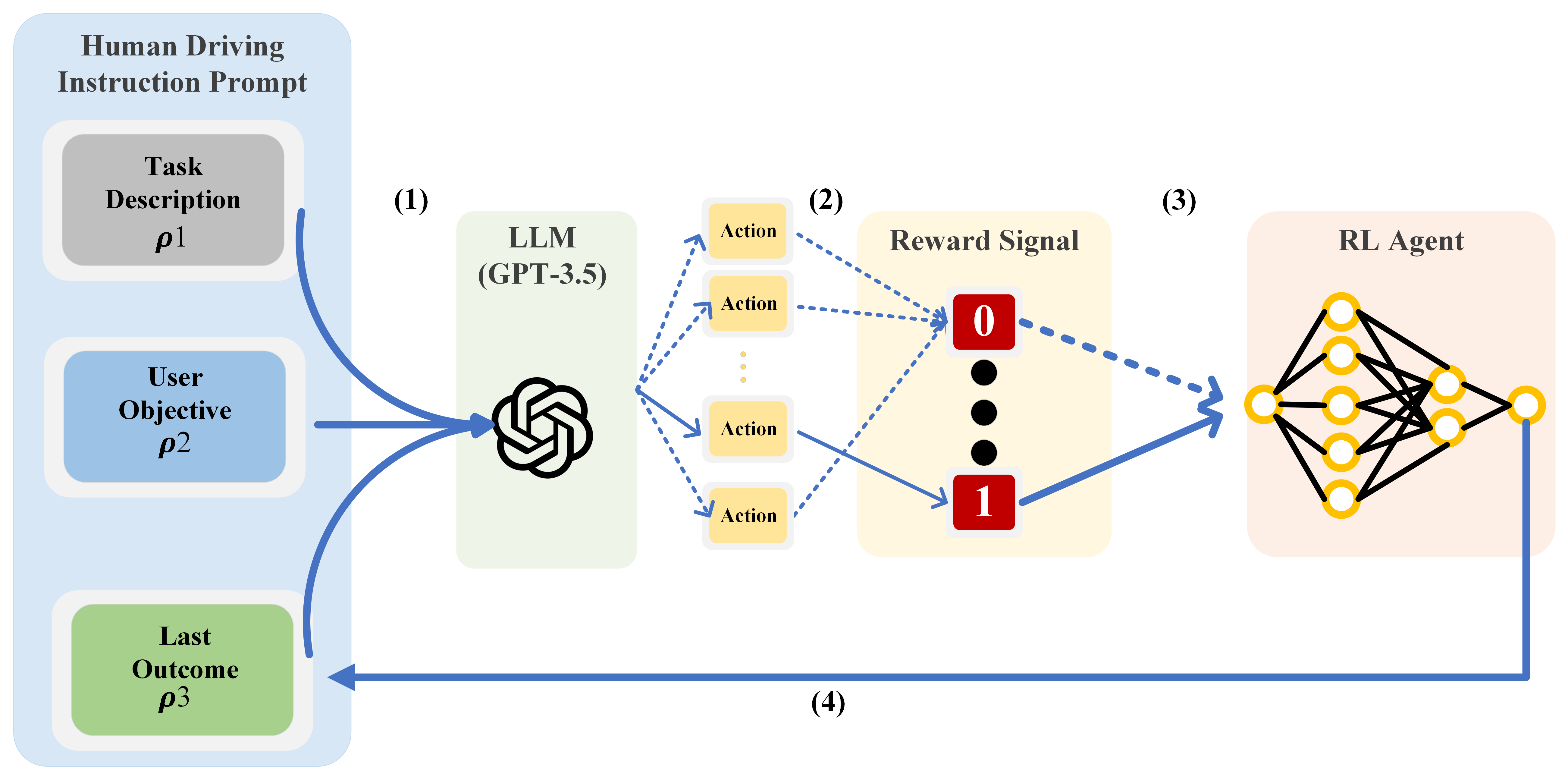
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
Read more5/8/2024
0
Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning
Guanwen Xie, Jingzehua Xu, Yiyuan Yang, Shuai Zhang
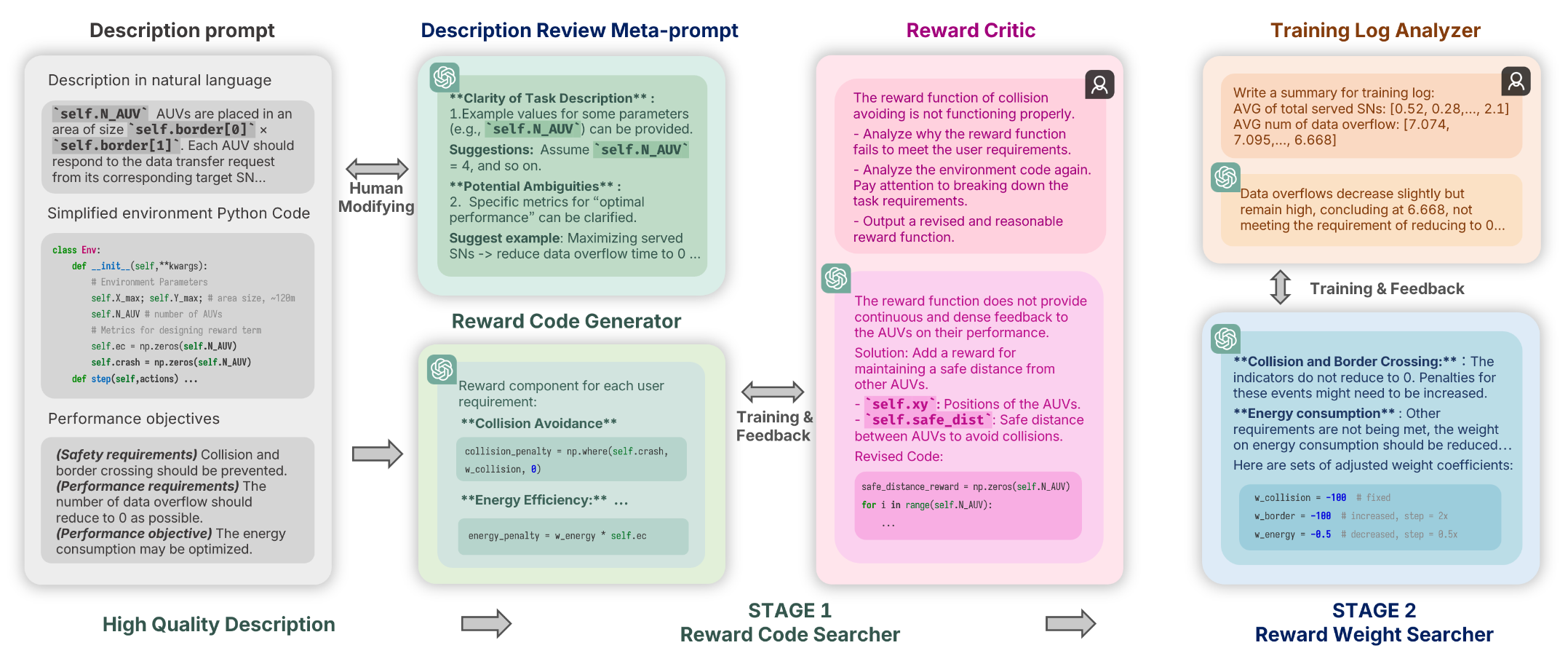
Leveraging large language models (LLMs) for designing reward functions demonstrates significant potential. However, achieving effective design and improvement of reward functions in reinforcement learning (RL) tasks with complex custom environments and multiple requirements presents considerable challenges. In this paper, we enable LLMs to be effective white-box searchers, highlighting their advanced semantic understanding capabilities. Specifically, we generate reward components for each explicit user requirement and employ the reward critic to identify the correct code form. Then, LLMs assign weights to the reward components to balance their values and iteratively search and optimize these weights based on the context provided by the training log analyzer, while adaptively determining the search step size. We applied the framework to an underwater information collection RL task without direct human feedback or reward examples (zero-shot). The reward critic successfully correct the reward code with only one feedback for each requirement, effectively preventing irreparable errors that can occur when reward function feedback is provided in aggregate. The effective initialization of weights enables the acquisition of different reward functions within the Pareto solution set without weight search. Even in the case where a weight is 100 times off, fewer than four iterations are needed to obtain solutions that meet user requirements. The framework also works well with most prompts utilizing GPT-3.5 Turbo, since it does not require advanced numerical understanding or calculation.
Read more9/5/2024