Large Language Models as Evaluators for Recommendation Explanations
2406.03248
0
0

Abstract
The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
Create account to get full access
Overview
- Presents a feature-enhanced neural collaborative reasoning model for recommendation
- Aims to improve interpretability and explainability of recommendation systems
- Learns rule-based representations to enhance collaborative reasoning
Plain English Explanation
The paper describes a new approach for making recommendation systems more interpretable and explainable. Recommendation systems are algorithms that suggest products, movies, or other items that a user might like based on their past preferences and the preferences of similar users.
The researchers developed a model that combines traditional collaborative filtering (using patterns in user preferences) with an additional component that learns explicit rules to explain the recommendations. This allows the model to not just make predictions, but also provide understandable reasons for why certain items are recommended.
For example, the model might learn a rule like "if a user likes sci-fi movies and action movies, then they are likely to enjoy this new thriller film." By surfacing these types of interpretable rules, the recommendation system becomes more transparent and users can better understand the reasoning behind the suggestions.
The key innovation is the use of dense representations to capture feature-level relationships, which are then combined with the collaborative filtering to generate the final recommendations. This approach aims to strike a balance between the accuracy of collaborative filtering and the interpretability provided by the rule-based component.
Technical Explanation
The paper proposes a Feature-Enhanced Neural Collaborative Reasoning (FE-NCR) model for making recommendations. The core architecture consists of three main components:
-
Feature Extractor: This module learns dense vector representations of user and item features (e.g., user demographics, item descriptions) using neural networks.
-
Collaborative Reasoner: This component applies collaborative filtering techniques to model user-item interactions and preferences.
-
Rule Learner: This module learns a set of interpretable logical rules that can explain the recommendations, using the dense feature representations as input.
The three components are trained jointly, allowing the model to learn feature representations that are optimized for both accurate recommendations and generating human-understandable rules.
The authors evaluate FE-NCR on several standard recommendation datasets and show that it outperforms baseline collaborative filtering methods in terms of recommendation accuracy. Importantly, they also demonstrate that the learned rules provide meaningful explanations for the recommendations, making the system more transparent and trustworthy.
Critical Analysis
The paper presents a novel and promising approach to improving the interpretability and explainability of recommendation systems. By incorporating a rule learning component, the model goes beyond just making predictions and can also provide users with insights into the reasoning behind the recommendations.
However, the authors acknowledge that the rule learning process can be computationally expensive, particularly as the number of features and rules grows. There may also be challenges in scaling the approach to very large recommendation systems with millions of users and items.
Additionally, the paper does not extensively discuss the potential biases that may be introduced by the rule learning component or how to ensure the rules learned are truly representative and unbiased. This is an important consideration for real-world deployment of such systems.
Further research could explore ways to improve the efficiency and scalability of the rule learning process, as well as investigate techniques to mitigate biases and ensure the explanations provided by the system are fair and inclusive.
Conclusion
The Feature-Enhanced Neural Collaborative Reasoning (FE-NCR) model presented in this paper represents an important step towards more interpretable and explainable recommendation systems. By combining collaborative filtering with rule-based reasoning, the model can not only make accurate predictions but also provide users with understandable explanations for the recommendations.
This approach has the potential to increase user trust and engagement with recommendation systems, as well as enable better debugging and auditing of the systems. As artificial intelligence and machine learning become more pervasive in our daily lives, developing interpretable and explainable models will be crucial for ensuring these technologies are ethical, transparent, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
💬
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
0
0
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
4/17/2024
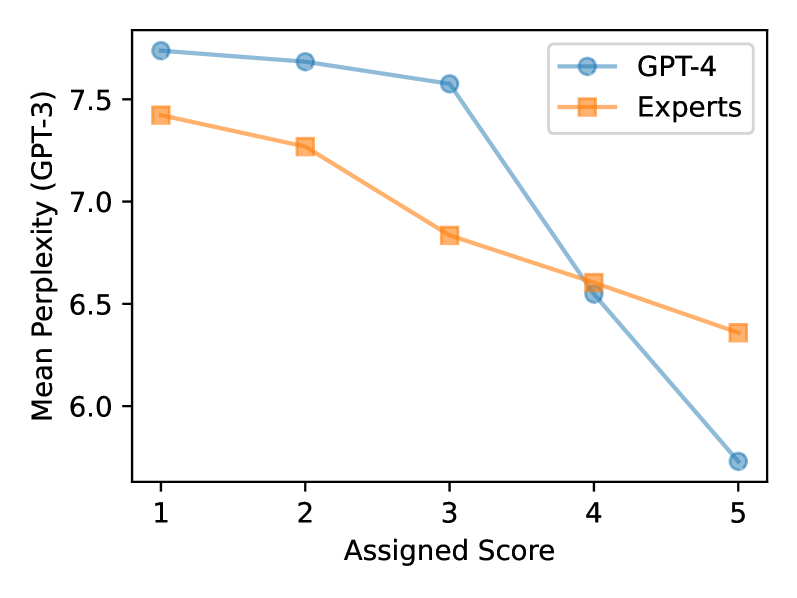
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024
💬
PRE: A Peer Review Based Large Language Model Evaluator
Zhumin Chu, Qingyao Ai, Yiteng Tu, Haitao Li, Yiqun Liu
0
0
The impressive performance of large language models (LLMs) has attracted considerable attention from the academic and industrial communities. Besides how to construct and train LLMs, how to effectively evaluate and compare the capacity of LLMs has also been well recognized as an important yet difficult problem. Existing paradigms rely on either human annotators or model-based evaluators to evaluate the performance of LLMs on different tasks. However, these paradigms often suffer from high cost, low generalizability, and inherited biases in practice, which make them incapable of supporting the sustainable development of LLMs in long term. In order to address these issues, inspired by the peer review systems widely used in academic publication process, we propose a novel framework that can automatically evaluate LLMs through a peer-review process. Specifically, for the evaluation of a specific task, we first construct a small qualification exam to select reviewers from a couple of powerful LLMs. Then, to actually evaluate the submissions written by different candidate LLMs, i.e., the evaluatees, we use the reviewer LLMs to rate or compare the submissions. The final ranking of evaluatee LLMs is generated based on the results provided by all reviewers. We conducted extensive experiments on text summarization tasks with eleven LLMs including GPT-4. The results demonstrate the existence of biasness when evaluating using a single LLM. Also, our PRE model outperforms all the baselines, illustrating the effectiveness of the peer review mechanism.
6/4/2024