Large Language Models as Recommender Systems: A Study of Popularity Bias
2406.01285
0
0
Abstract
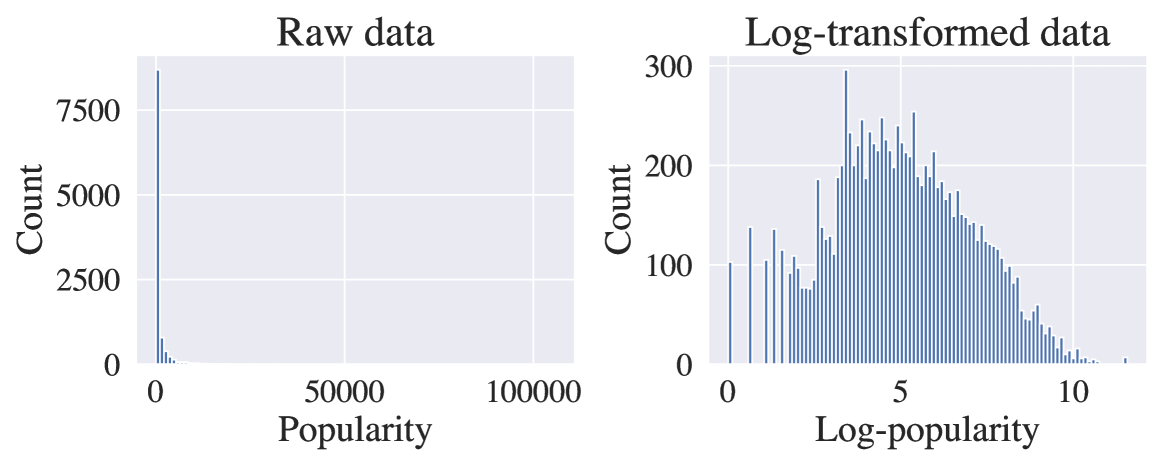
The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
Create account to get full access
Overview
- This paper explores the impact of popularity bias in large language models (LLMs) when used as recommender systems.
- The researchers investigate how LLMs' inherent biases towards popular items can affect the diversity and accuracy of their recommendations.
- The study provides insights into the challenges of leveraging LLMs for recommendation tasks and the importance of addressing popularity bias in these models.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. In recent years, researchers have explored using LLMs as the basis for recommender systems, which suggest products, content, or information to users based on their preferences and behaviors.
However, the researchers of this paper found that LLMs can exhibit a strong popularity bias, meaning they tend to recommend the most popular items rather than a diverse range of options. This can lead to a narrowing of user exposure and potentially less-relevant recommendations.
The researchers conducted experiments to understand the extent of this popularity bias in LLMs and how it affects the quality of their recommendations. They found that LLMs often prioritize well-known, high-profile items over lesser-known but potentially more suitable options.
This popularity bias is an important consideration for anyone looking to use LLMs in recommender systems, as it can undermine the goal of providing personalized and diverse recommendations. The researchers suggest that addressing this bias, perhaps through additional training or model modifications, could help LLMs become more effective recommender systems.
Technical Explanation
The paper begins by highlighting the growing interest in leveraging large language models (LLMs) as the foundation for recommender systems, given their impressive natural language capabilities. However, the authors note that LLMs may exhibit inherent biases, such as a tendency to favor popular or well-known items, which could negatively impact the quality and diversity of their recommendations.
To investigate this issue, the researchers conducted a series of experiments using several prominent LLMs, including GPT-3 and BERT, as well as traditional collaborative filtering-based recommender systems. The experiments involved generating recommendations for a range of products, movies, and other items, and then analyzing the degree of popularity bias present in the recommendations produced by the different systems.
The results showed that LLMs indeed displayed a significant popularity bias, tending to recommend the most popular items more frequently than less well-known but potentially more relevant options. This bias was observed across various domains, including e-commerce, media, and even academic publications.
Furthermore, the researchers found that the popularity bias exhibited by LLMs was often more pronounced than that of traditional collaborative filtering-based recommender systems. This suggests that the inherent biases present in LLMs' training data and model architectures can amplify the tendency to favor popular items.
The paper also explores potential reasons for this popularity bias, including the way LLMs are trained on large, heterogeneous datasets that may reflect societal biases, as well as the models' tendency to rely on common patterns and associations in their language generation.
Overall, the findings of this study highlight the importance of carefully considering the biases and limitations of LLMs when deploying them in real-world recommender systems. The researchers suggest that addressing these biases, potentially through debiasing techniques or the incorporation of additional information sources, could be a crucial step in unlocking the full potential of LLMs as effective and unbiased recommender systems.
Critical Analysis
The paper provides a valuable contribution to the ongoing discussion around the use of large language models (LLMs) in recommender systems. By rigorously investigating the presence and extent of popularity bias in LLM-based recommendations, the researchers have shed light on an important limitation that must be addressed for these models to be effectively deployed in real-world applications.
One particular strength of the study is the breadth of domains and datasets used, which helps to demonstrate the generalizability of the popularity bias phenomenon across different types of recommendations. The comparative analysis with traditional collaborative filtering-based systems also serves to highlight the unique challenges posed by the biases inherent in LLM architectures and training.
However, the paper could have delved deeper into potential root causes of the popularity bias, beyond the general explanations provided. A more detailed examination of the specific model architectures, training data, and learning mechanisms that contribute to this bias could have offered further insights and potential avenues for mitigation.
Additionally, while the study identifies the existence of popularity bias, it does not extensively explore potential solutions or debiasing techniques that could be applied to LLM-based recommender systems. Further research in this direction could provide valuable guidance for practitioners looking to develop more robust and unbiased recommendation engines powered by LLMs.
Overall, this paper serves as an important wake-up call for the AI research community, highlighting the need to carefully consider and address the biases inherent in large language models, particularly when they are being applied to high-stakes domains like recommendation systems. By continuing to investigate and mitigate these biases, researchers can work towards unlocking the full potential of LLMs as unbiased and effective decision-making tools.
Conclusion
This paper presents a timely and important study on the prevalence of popularity bias in large language models (LLMs) used as recommender systems. The researchers' findings demonstrate that LLMs, despite their impressive natural language capabilities, can exhibit a strong tendency to favor well-known, popular items over less familiar but potentially more relevant options.
This popularity bias can undermine the core purpose of recommendation engines, which is to provide personalized and diverse suggestions to users. As LLMs continue to be explored as the foundation for recommender systems, addressing this bias will be a crucial challenge for the research community to overcome.
The insights and methodologies presented in this paper offer a valuable starting point for further investigation and development of debiasing techniques that could help LLMs become more effective and equitable recommendation engines. By tackling the complex issue of popularity bias, researchers can pave the way for LLMs to truly shine as powerful and unbiased decision-making tools across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
0
0
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
5/1/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, Chanyoung Park
0
0
Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
6/4/2024