Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
2402.17944
2
0

Abstract
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
Create account to get full access
Overview
- This paper provides a comprehensive survey of the use of large language models (LLMs) on tabular data, which is a common type of structured data found in many real-world applications.
- The paper examines the characteristics of tabular data, the limitations of traditional machine learning approaches, and how LLMs can be leveraged to address these challenges.
- It also covers various techniques and use cases for applying LLMs to tabular data, including feature engineering, handling class imbalance, and time series forecasting.
- The paper concludes by discussing the efficiency and scalability of LLMs for tabular data tasks, as well as potential areas for future research and development.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. This paper explores how these powerful models can be used to work with tabular data, which is a common format for organizing information in spreadsheets, databases, and other applications.
Tabular data has some unique characteristics, such as the need to handle numerical values, categorical variables, and relationships between different columns. Traditional machine learning methods can struggle with these aspects of tabular data, but the authors show how LLMs can be a more effective solution.
For example, LLMs can automatically generate new features from the raw tabular data, which can improve the performance of downstream machine learning models. They can also help overcome issues like class imbalance, where one category of data is much more common than others.
Additionally, the paper explores how LLMs can be used for time series forecasting on tabular data, which is a common task in areas like finance and supply chain management.
Overall, the paper demonstrates the versatility of LLMs and how they can be a powerful tool for working with tabular data, which is essential in many real-world applications. The authors also discuss the efficiency and scalability of LLMs for these types of tasks, as well as areas for future research and development.
Technical Explanation
The paper begins by examining the characteristics of tabular data, which is structured in rows and columns, often containing a mix of numerical values, categorical variables, and complex relationships between different attributes. Traditional machine learning approaches, such as decision trees and linear regression, can struggle to effectively capture these nuances of tabular data.
The authors then introduce the potential of large language models (LLMs) to address the limitations of traditional methods. LLMs, such as GPT and BERT, are trained on vast amounts of text data and have shown impressive performance on a wide range of natural language processing tasks. The paper explores how these powerful models can be adapted and applied to tabular data problems.
One key area covered is feature engineering with LLMs. The authors demonstrate how LLMs can automatically generate new, informative features from the raw tabular data, which can significantly improve the performance of downstream machine learning models.
The paper also delves into techniques for addressing class imbalance in tabular data using LLMs. Class imbalance occurs when one category of data is much more common than others, which can cause issues for traditional machine learning algorithms. The authors explore various prompting methods that leverage the language understanding capabilities of LLMs to overcome this challenge.
Additionally, the paper investigates the use of LLMs for time series forecasting on tabular data. Time series data, which tracks values over time, is prevalent in many industries, and the authors demonstrate how LLMs can be effectively applied to these types of tasks.
Finally, the paper discusses the efficiency and scalability of LLMs for tabular data tasks, highlighting the potential for these models to be deployed at scale in real-world applications.
Critical Analysis
The paper provides a comprehensive and insightful survey of the use of large language models (LLMs) for tabular data, highlighting the unique challenges and opportunities presented by this type of structured data. The authors have done an excellent job of covering a wide range of techniques and use cases, while also acknowledging the limitations and areas for further research.
One potential limitation of the paper is that it does not delve deeply into the specific architectural choices and hyperparameter tuning required to effectively apply LLMs to tabular data tasks. While the authors provide a high-level overview, more detailed technical guidance could be beneficial for researchers and practitioners looking to implement these techniques in their own work.
Additionally, the paper does not address the potential ethical and societal implications of using LLMs for tabular data, such as issues around bias, fairness, and transparency. As these models become more widely adopted, it will be important to consider these important considerations.
Overall, this paper serves as an invaluable resource for anyone interested in understanding the current state of the art in applying large language models to tabular data problems. The authors have provided a solid foundation for further research and development in this rapidly evolving field.
Conclusion
This comprehensive survey paper demonstrates the exciting potential of large language models (LLMs) for working with tabular data, a ubiquitous type of structured information found in many real-world applications. The authors have highlighted how LLMs can address the limitations of traditional machine learning approaches, offering powerful techniques for feature engineering, handling class imbalance, and even time series forecasting.
By exploring the unique characteristics of tabular data and the various ways LLMs can be leveraged to tackle these challenges, the paper provides a valuable roadmap for researchers and practitioners looking to push the boundaries of what is possible with these advanced AI models. As the field of AI continues to evolve, the insights and techniques presented in this survey are sure to have a lasting impact on how we approach and solve a wide range of tabular data problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
0
0
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
4/9/2024

Large Scale Transfer Learning for Tabular Data via Language Modeling
Josh Gardner, Juan C. Perdomo, Ludwig Schmidt
0
0
Tabular data -- structured, heterogeneous, spreadsheet-style data with rows and columns -- is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.
6/19/2024
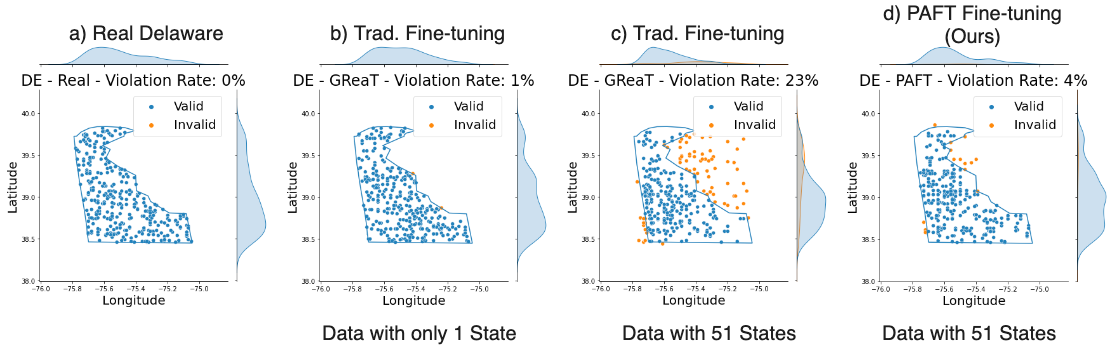
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
0
0
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024
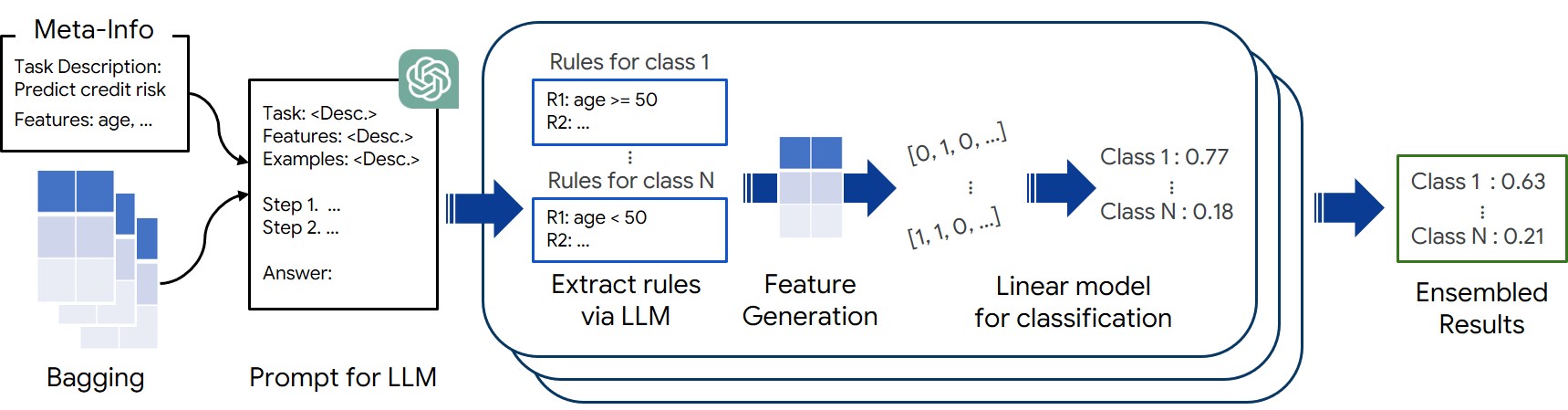
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, Tomas Pfister
0
0
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
5/7/2024