Large Language Models Can Infer Psychological Dispositions of Social Media Users
2309.08631
0
0
💬
Abstract
Large Language Models (LLMs) demonstrate increasingly human-like abilities across a wide variety of tasks. In this paper, we investigate whether LLMs like ChatGPT can accurately infer the psychological dispositions of social media users and whether their ability to do so varies across socio-demographic groups. Specifically, we test whether GPT-3.5 and GPT-4 can derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores - a level of accuracy that is similar to that of supervised machine learning models specifically trained to infer personality. Our findings also highlight heterogeneity in the accuracy of personality inferences across different age groups and gender categories: predictions were found to be more accurate for women and younger individuals on several traits, suggesting a potential bias stemming from the underlying training data or differences in online self-expression. The ability of LLMs to infer psychological dispositions from user-generated text has the potential to democratize access to cheap and scalable psychometric assessments for both researchers and practitioners. On the one hand, this democratization might facilitate large-scale research of high ecological validity and spark innovation in personalized services. On the other hand, it also raises ethical concerns regarding user privacy and self-determination, highlighting the need for stringent ethical frameworks and regulation.
Create account to get full access
Overview
- This research paper investigates whether large language models (LLMs) like ChatGPT can accurately infer the psychological dispositions of social media users, and whether their ability to do so varies across demographic groups.
- The study tests whether GPT-3.5 and GPT-4 can derive the Big Five personality traits from users' Facebook status updates, using a zero-shot learning approach.
- The results show that LLMs can infer personality traits with an average correlation of r = .29 to self-reported scores, which is similar to the accuracy of supervised machine learning models.
- The paper also highlights differences in the accuracy of personality inferences across age groups and gender categories, suggesting potential biases in the underlying training data or differences in online self-expression.
Plain English Explanation
The researchers wanted to see if powerful AI language models like ChatGPT could accurately figure out people's personality traits just by looking at the text they post on social media. They tested two advanced language models, GPT-3.5 and GPT-4, to see if they could identify the "Big Five" personality traits (openness, conscientiousness, extraversion, agreeableness, and neuroticism) from people's Facebook status updates.
Interestingly, the language models were able to predict people's personality traits with about the same accuracy as specialized machine learning models that are trained specifically for this task. This suggests that these powerful AI language models have developed a pretty good understanding of how personality is reflected in the way people communicate online.
However, the researchers also found that the language models were better at inferring certain personality traits for some demographic groups than others. For example, they were more accurate in predicting the personalities of women and younger individuals on several traits. This could be because the data the models were trained on had biases, or because people from different backgrounds express their personalities differently online.
Overall, this study shows that large language models are getting remarkably good at understanding human psychology just from analyzing text. This could be useful for things like personalizing services or conducting large-scale personality research. But it also raises important ethical concerns around privacy and how this technology might be misused.
Technical Explanation
In this study, the researchers investigated the ability of large language models (LLMs) to infer the psychological dispositions of social media users. Specifically, they tested whether GPT-3.5 and GPT-4 could derive the Big Five personality traits (openness, conscientiousness, extraversion, agreeableness, and neuroticism) from users' Facebook status updates in a zero-shot learning scenario.
The researchers used a dataset of 9,923 individuals who had completed self-reported personality assessments and shared their Facebook status updates. They then used the language models to generate personality trait scores for each user based solely on the text of their status updates, without any additional training or supervision.
The results showed that the LLMs were able to infer personality traits with an average correlation of r = .29 between the model-generated scores and the self-reported trait scores. This level of accuracy was similar to that of supervised machine learning models specifically trained to predict personality from text.
Furthermore, the study revealed heterogeneity in the accuracy of personality inferences across different socio-demographic groups. The language models were found to be more accurate in predicting several personality traits for women and younger individuals, suggesting potential biases in the underlying training data or differences in online self-expression.
These findings demonstrate that large language models have developed a remarkable ability to infer psychological dispositions from user-generated text, which could have significant implications for both research and practical applications. However, the uneven performance across demographic groups also highlights the need for careful consideration of ethical and privacy concerns as this technology continues to perform on par with expert-level assessments.
Critical Analysis
The paper presents a thorough and well-designed study, but it is important to consider some of the caveats and limitations mentioned by the authors.
One key limitation is the reliance on self-reported personality assessments as the ground truth, which may not always accurately reflect an individual's true psychological dispositions. Additionally, the use of Facebook status updates as the sole source of textual data may not fully capture the nuances of how people express their personalities across different online platforms or contexts.
The study also acknowledges the potential for biases in the underlying training data used to develop the language models, which could lead to systematic differences in the accuracy of personality inferences across demographic groups. Further research is needed to better understand the sources of these biases and how they can be mitigated.
It is also worth considering the broader ethical implications of using language models to infer sensitive personal information, such as psychological traits, without the explicit consent or awareness of the individuals involved. This raises concerns about privacy, user autonomy, and the potential for misuse or exploitation of this technology.
Overall, while the findings of this study are intriguing and demonstrate the impressive capabilities of large language models, they also highlight the need for ongoing critical examination and thoughtful consideration of the social and ethical implications of these powerful AI systems.
Conclusion
This research paper provides compelling evidence that large language models can accurately infer the psychological dispositions of social media users, with performance on par with specialized machine learning models. The ability of these AI systems to derive personality traits from user-generated text has the potential to democratize access to psychometric assessments, enabling large-scale research and personalized services.
However, the study also reveals heterogeneity in the accuracy of these personality inferences across different socio-demographic groups, suggesting potential biases in the underlying training data or differences in online self-expression. This highlights the need for careful consideration of the ethical implications of using language models to infer sensitive personal information without the explicit consent of the individuals involved.
As large language models continue to demonstrate their impressive capabilities, it is crucial that researchers, practitioners, and policymakers work together to develop stringent ethical frameworks and regulations to ensure these technologies are deployed in a responsible and equitable manner, balancing innovation and personalization with the protection of user privacy and self-determination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models Can Infer Personality from Free-Form User Interactions
Heinrich Peters, Moran Cerf, Sandra C. Matz
0
0
This study investigates the capacity of Large Language Models (LLMs) to infer the Big Five personality traits from free-form user interactions. The results demonstrate that a chatbot powered by GPT-4 can infer personality with moderate accuracy, outperforming previous approaches drawing inferences from static text content. The accuracy of inferences varied across different conversational settings. Performance was highest when the chatbot was prompted to elicit personality-relevant information from users (mean r=.443, range=[.245, .640]), followed by a condition placing greater emphasis on naturalistic interaction (mean r=.218, range=[.066, .373]). Notably, the direct focus on personality assessment did not result in a less positive user experience, with participants reporting the interactions to be equally natural, pleasant, engaging, and humanlike across both conditions. A chatbot mimicking ChatGPT's default behavior of acting as a helpful assistant led to markedly inferior personality inferences and lower user experience ratings but still captured psychologically meaningful information for some of the personality traits (mean r=.117, range=[-.004, .209]). Preliminary analyses suggest that the accuracy of personality inferences varies only marginally across different socio-demographic subgroups. Our results highlight the potential of LLMs for psychological profiling based on conversational interactions. We discuss practical implications and ethical challenges associated with these findings.
5/24/2024
💬
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
0
0
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
4/3/2024
💬
New!Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
0
0
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
6/28/2024
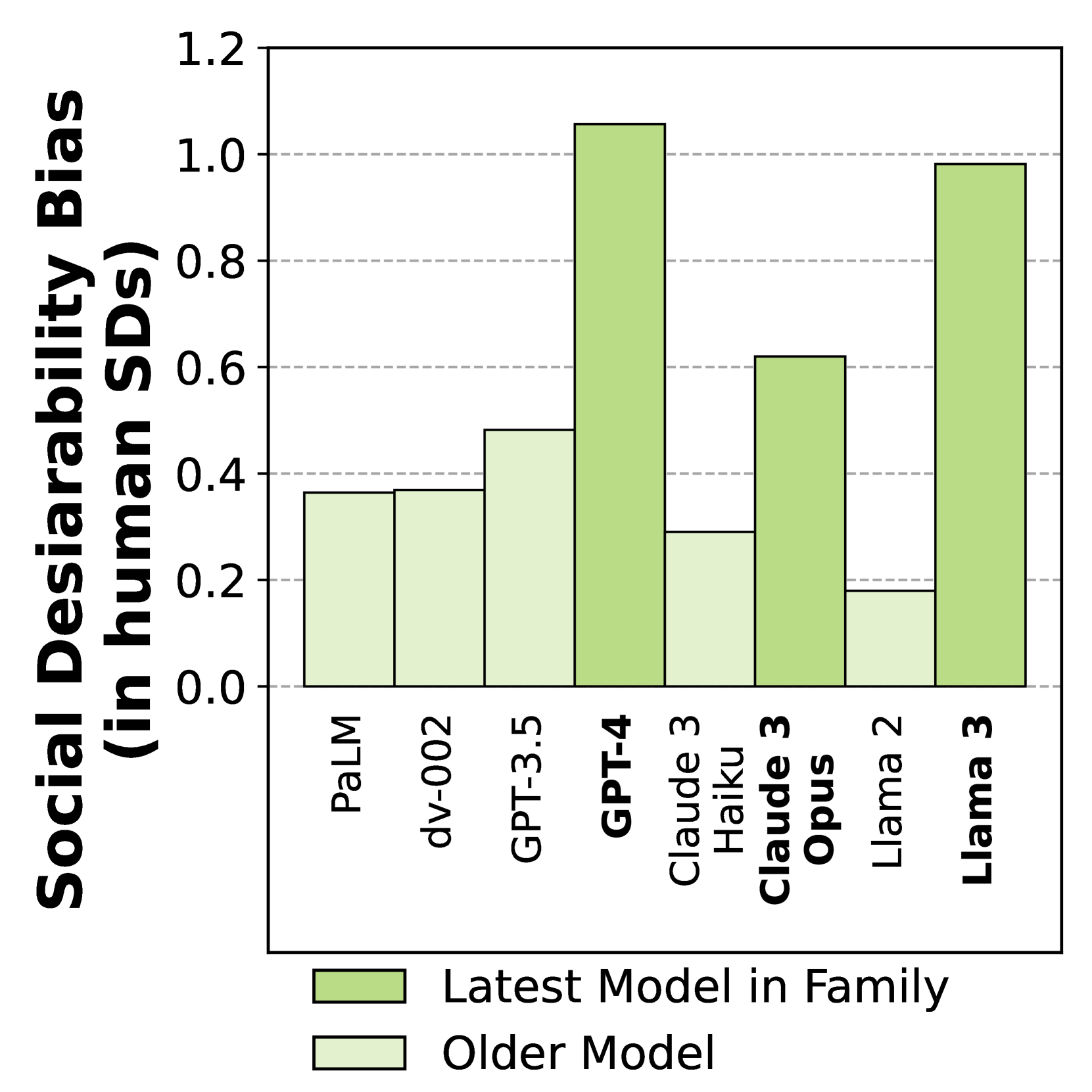
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024