Do Large Language Model Understand Multi-Intent Spoken Language ?
2403.04481
0
0
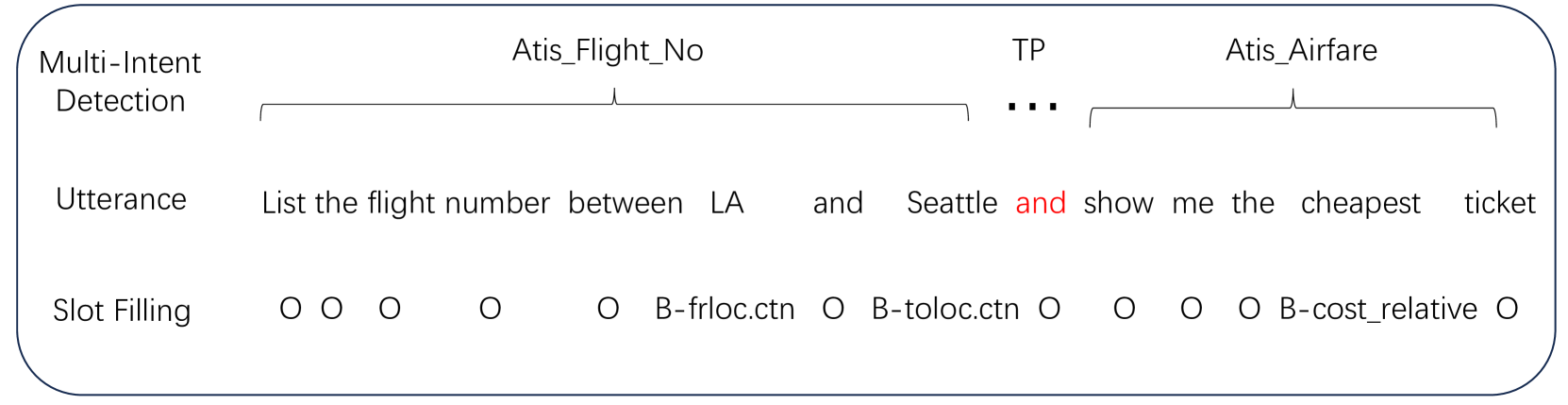
Abstract
This research signifies a considerable breakthrough in leveraging Large Language Models (LLMs) for multi-intent spoken language understanding (SLU). Our approach re-imagines the use of entity slots in multi-intent SLU applications, making the most of the generative potential of LLMs within the SLU landscape, leading to the development of the EN-LLM series. Furthermore, we introduce the concept of Sub-Intent Instruction (SII) to amplify the analysis and interpretation of complex, multi-intent communications, which further supports the creation of the ENSI-LLM models series. Our novel datasets, identified as LM-MixATIS and LM-MixSNIPS, are synthesized from existing benchmarks. The study evidences that LLMs may match or even surpass the performance of the current best multi-intent SLU models. We also scrutinize the performance of LLMs across a spectrum of intent configurations and dataset distributions. On top of this, we present two revolutionary metrics - Entity Slot Accuracy (ESA) and Combined Semantic Accuracy (CSA) - to facilitate a detailed assessment of LLM competence in this multifaceted field. Our code and datasets are available at url{https://github.com/SJY8460/SLM}.
Create account to get full access
Overview
- This paper investigates whether large language models (LLMs) can effectively understand multi-intent spoken language, which involves processing multiple intents or goals within a single spoken utterance.
- The authors explore the capabilities of LLMs in this context and provide insights on the current state of the technology and areas for future research.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can process and generate human-like text. Researchers wanted to see how well these models can handle spoken language that conveys multiple intents or goals at the same time.
For example, imagine someone saying "Can you please book a flight to New York and also make a dinner reservation for two at a nice restaurant?". This utterance has two distinct intents - booking a flight and making a dinner reservation. The researchers investigated whether LLMs can accurately detect and understand both of these intents in a single spoken statement.
Understanding multi-intent spoken language is an important capability for AI assistants and conversational interfaces to have, as it allows them to more naturally and effectively communicate with users. The findings from this research could help advance the development of more intelligent and user-friendly AI systems.
Technical Explanation
The paper defines the task of multi-intent detection as identifying all the distinct intents or goals expressed within a single spoken utterance. The authors evaluate the performance of large language models, such as GPT-3, on this task using several benchmark datasets.
The experiments involve feeding the LLMs transcripts of spoken utterances with multiple intents and measuring how accurately the models can detect all the underlying intents. The authors also explore different approaches to improving LLM performance, including incorporating multimodal information and leveraging supervised knowledge.
The results suggest that while LLMs demonstrate some capability in multi-intent detection, they still struggle compared to specialized spoken language understanding models. The paper discusses potential reasons for this, such as the models' tendency to focus on the most prominent intent and overlook less salient intents.
Critical Analysis
The paper provides a thorough analysis of the current limitations of LLMs in handling multi-intent spoken language. While the authors acknowledge the impressive capabilities of these large models, they rightly point out that specialized architectures and training approaches may be necessary to fully address the challenges of this task.
One potential area for further research mentioned in the paper is the integration of multimodal information, such as visual and acoustic cues, to supplement the text-based understanding of spoken utterances. This could help LLMs better contextualize and disambiguate the multiple intents expressed.
Additionally, the authors suggest that leveraging supervised knowledge from specialized spoken language understanding models may be a promising approach to improve LLM performance on this task. Combining the broad and flexible capabilities of LLMs with the targeted expertise of domain-specific models could lead to more robust and accurate multi-intent detection.
Conclusion
This paper provides valuable insights into the current limitations of large language models in understanding multi-intent spoken language. While LLMs have demonstrated impressive language understanding capabilities, the authors show that specialized approaches may be necessary to fully address the challenges of this task.
The findings from this research could inform the development of more advanced conversational AI systems, enabling them to more effectively communicate with users and understand their varied intents and goals. As the field of natural language processing continues to evolve, this work contributes to our understanding of the strengths and weaknesses of large language models and points to promising directions for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024

Towards Spoken Language Understanding via Multi-level Multi-grained Contrastive Learning
Xuxin Cheng, Wanshi Xu, Zhihong Zhu, Hongxiang Li, Yuexian Zou
0
0
Spoken language understanding (SLU) is a core task in task-oriented dialogue systems, which aims at understanding the user's current goal through constructing semantic frames. SLU usually consists of two subtasks, including intent detection and slot filling. Although there are some SLU frameworks joint modeling the two subtasks and achieving high performance, most of them still overlook the inherent relationships between intents and slots and fail to achieve mutual guidance between the two subtasks. To solve the problem, we propose a multi-level multi-grained SLU framework MMCL to apply contrastive learning at three levels, including utterance level, slot level, and word level to enable intent and slot to mutually guide each other. For the utterance level, our framework implements coarse granularity contrastive learning and fine granularity contrastive learning simultaneously. Besides, we also apply the self-distillation method to improve the robustness of the model. Experimental results and further analysis demonstrate that our proposed model achieves new state-of-the-art results on two public multi-intent SLU datasets, obtaining a 2.6 overall accuracy improvement on the MixATIS dataset compared to previous best models.
6/3/2024
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024