UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
2310.02973
0
0
💬
Abstract
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
Create account to get full access
Overview
- Researchers have explored using large language models with multi-tasking capabilities and natural language prompts to surpass the performance of task-specific models.
- This paper investigates whether a single model can jointly perform various spoken language understanding (SLU) tasks.
- The approach involves adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers and instruction tuning.
- The resulting multi-task learning model, UniverSLU, is evaluated on 12 speech classification and sequence generation tasks across 17 datasets and 9 languages.
Plain English Explanation
The researchers were inspired by recent studies showing that large AI language models can take on multiple tasks by using natural language instructions. They wanted to see if they could build a single AI model that could handle various spoken language understanding tasks, like classifying speech or generating text from speech.
To do this, they started with an existing AI model trained to transcribe speech. They then adapted this model to handle additional tasks, like detecting the sentiment of speech or summarizing speech, by introducing special tokens to indicate the task. They also fine-tuned the model by providing natural language instructions describing each task and the possible responses.
This approach allows the model to be more user-friendly, as it can adapt to new task descriptions during use, rather than requiring the user to pick from a fixed set of tasks. The researchers evaluated this multi-task model, called UniverSLU, on 12 different spoken language understanding tasks across many datasets and languages. They found that UniverSLU performed competitively with and often exceeded the performance of models trained specifically for each individual task.
Additionally, the researchers discovered that UniverSLU could generalize to handle new datasets and languages for the same types of tasks it was trained on, without any additional training. This "zero-shot" capability makes the model even more versatile and convenient to use.
Technical Explanation
The researchers started with a pre-trained automatic speech recognition (ASR) model as the base for their multi-task learning approach. To adapt this model to additional SLU tasks, they introduced single-token task specifiers that indicated the target task. For example, a token like "[SENTIMENT]" would signal to the model that the task was sentiment analysis.
They further enhanced this approach through "instruction tuning" - fine-tuning the model by providing natural language descriptions of each task followed by the list of possible labels or outputs. This allows the model to generalize to new task descriptions during inference, making it more user-friendly.
The resulting multi-task model, UniverSLU, was evaluated on 12 speech classification and sequence generation tasks spanning 17 datasets and 9 languages. These tasks included intent detection, slot filling, sentiment analysis, named entity recognition, and speech summarization, among others.
On most of these tasks, UniverSLU achieved competitive or even superior performance compared to task-specific models. The researchers also tested UniverSLU's zero-shot capabilities, finding that it could generalize to new datasets and languages for the same task types it was trained on, without any additional training.
Critical Analysis
The paper provides a thorough evaluation of the UniverSLU model's performance on a diverse set of SLU tasks and datasets. However, the researchers acknowledge that the model's zero-shot capabilities are limited to generalizing to new data for the same task types it was trained on. Extending this zero-shot ability to truly novel task types would be an important next step.
Additionally, the paper does not delve into the model's efficiency or inference speed, which are important practical considerations for real-world deployments. Further analysis of the model's computational and memory requirements would help assess its suitability for different deployment scenarios.
While the researchers demonstrate the versatility of their approach, it would be valuable to explore the model's robustness to noisy or challenging speech data, as well as its performance on tasks that require more complex reasoning or world knowledge.
Conclusion
This research showcases an innovative approach to building a single multi-task model for spoken language understanding. By adapting a pre-trained ASR model and utilizing instruction tuning, the researchers have created a versatile system that can handle a wide range of SLU tasks while maintaining competitive, and often superior, performance compared to task-specific models.
The model's ability to generalize to new task descriptions and even new datasets and languages for seen task types is a particularly promising feature, as it enhances the model's user-friendliness and real-world applicability. As the field of natural language processing continues to evolve, this work represents an important step towards developing more flexible and adaptable language understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Spoken Language Understanding via Multi-level Multi-grained Contrastive Learning
Xuxin Cheng, Wanshi Xu, Zhihong Zhu, Hongxiang Li, Yuexian Zou
0
0
Spoken language understanding (SLU) is a core task in task-oriented dialogue systems, which aims at understanding the user's current goal through constructing semantic frames. SLU usually consists of two subtasks, including intent detection and slot filling. Although there are some SLU frameworks joint modeling the two subtasks and achieving high performance, most of them still overlook the inherent relationships between intents and slots and fail to achieve mutual guidance between the two subtasks. To solve the problem, we propose a multi-level multi-grained SLU framework MMCL to apply contrastive learning at three levels, including utterance level, slot level, and word level to enable intent and slot to mutually guide each other. For the utterance level, our framework implements coarse granularity contrastive learning and fine granularity contrastive learning simultaneously. Besides, we also apply the self-distillation method to improve the robustness of the model. Experimental results and further analysis demonstrate that our proposed model achieves new state-of-the-art results on two public multi-intent SLU datasets, obtaining a 2.6 overall accuracy improvement on the MixATIS dataset compared to previous best models.
6/3/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
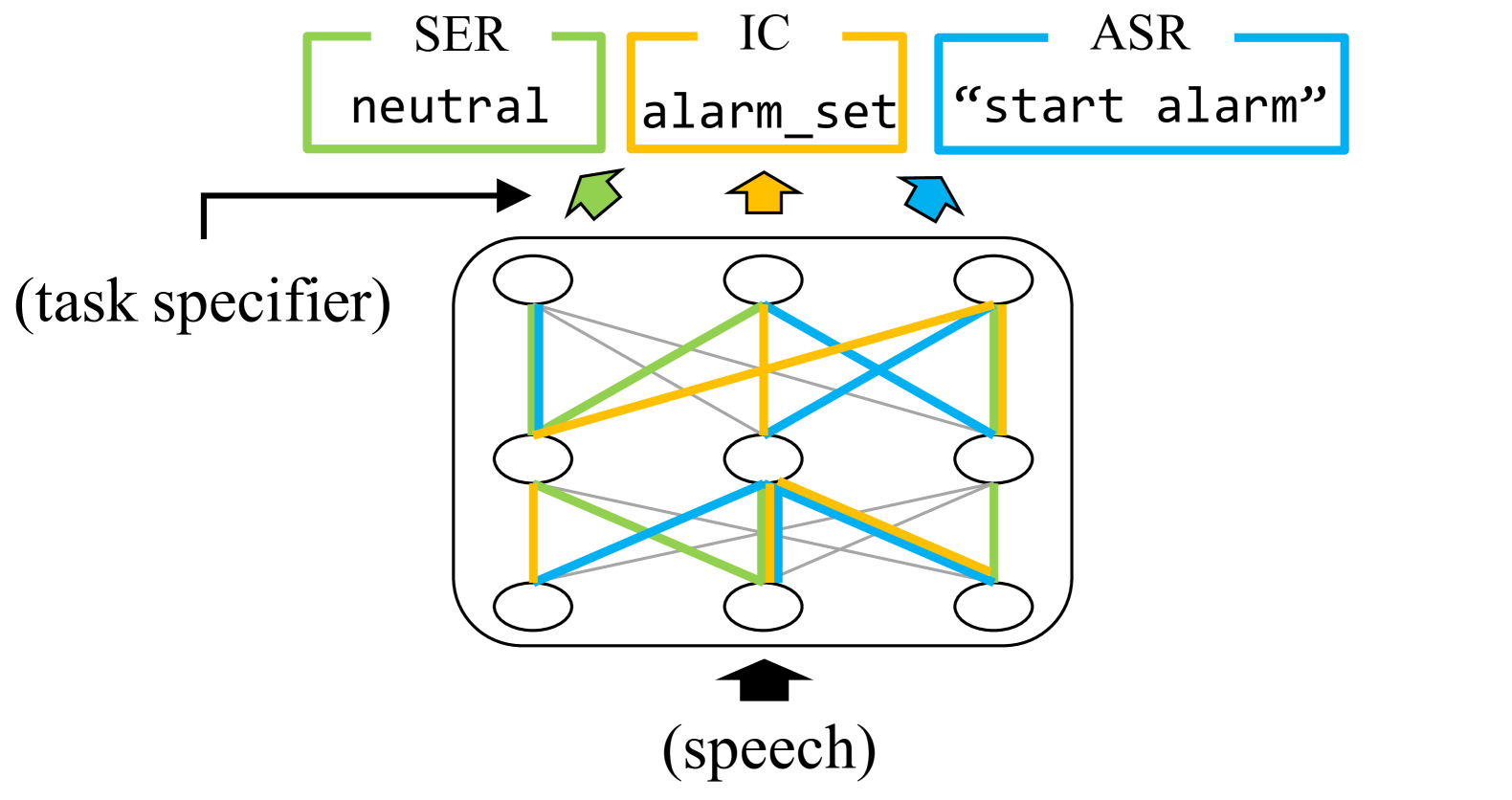
Finding Task-specific Subnetworks in Multi-task Spoken Language Understanding Model
Hayato Futami, Siddhant Arora, Yosuke Kashiwagi, Emiru Tsunoo, Shinji Watanabe
0
0
Recently, multi-task spoken language understanding (SLU) models have emerged, designed to address various speech processing tasks. However, these models often rely on a large number of parameters. Also, they often encounter difficulties in adapting to new data for a specific task without experiencing catastrophic forgetting of previously trained tasks. In this study, we propose finding task-specific subnetworks within a multi-task SLU model via neural network pruning. In addition to model compression, we expect that the forgetting of previously trained tasks can be mitigated by updating only a task-specific subnetwork. We conduct experiments on top of the state-of-the-art multi-task SLU model ``UniverSLU'', trained for several tasks such as emotion recognition (ER), intent classification (IC), and automatic speech recognition (ASR). We show that pruned models were successful in adapting to additional ASR or IC data with minimal performance degradation on previously trained tasks.
6/19/2024
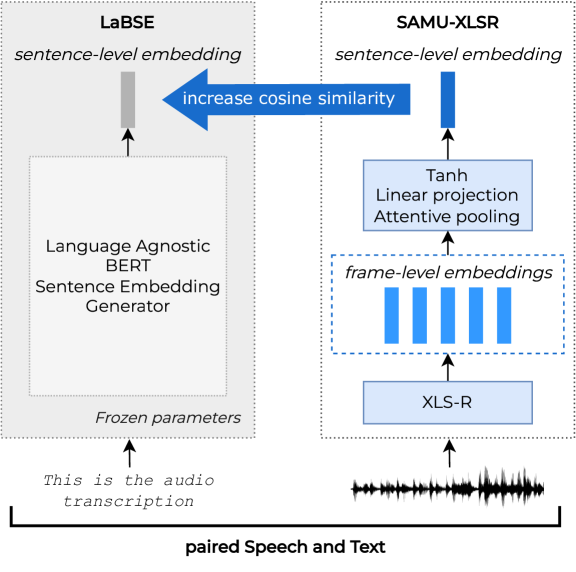
A dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Gaelle Laperri`ere, Sahar Ghannay, Bassam Jabaian, Yannick Est`eve
0
0
Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
6/19/2024