Large Language Models and Knowledge Graphs for Astronomical Entity Disambiguation
2406.11400
0
0
💬
Abstract
This paper presents an experiment conducted during a hackathon, focusing on using large language models (LLMs) and knowledge graph clustering to extract entities and relationships from astronomical text. The study demonstrates an approach to disambiguate entities that can appear in various contexts within the astronomical domain. By collecting excerpts around specific entities and leveraging the GPT-4 language model, relevant entities and relationships are extracted. The extracted information is then used to construct a knowledge graph, which is clustered using the Leiden algorithm. The resulting Leiden communities are utilized to identify the percentage of association of unknown excerpts to each community, thereby enabling disambiguation. The experiment showcases the potential of combining LLMs and knowledge graph clustering techniques for information extraction in astronomical research. The results highlight the effectiveness of the approach in identifying and disambiguating entities, as well as grouping them into meaningful clusters based on their relationships.
Create account to get full access
Overview
- This paper explores using large language models (LLMs) and knowledge graph clustering techniques to extract entities and relationships from astronomical text.
- The researchers demonstrate an approach to disambiguate entities that can appear in various contexts within the astronomical domain.
- By leveraging the GPT-4 language model and constructing a knowledge graph, the study showcases the potential of combining LLMs and graph clustering for effective information extraction.
Plain English Explanation
The researchers in this study wanted to find a way to better understand the relationships between different concepts and ideas in astronomical research papers. They used a combination of powerful language models and graph-based clustering techniques to extract important entities (like the names of stars, planets, or scientific concepts) and the connections between them.
The key idea is that by collecting excerpts of text around specific entities and feeding them into a large language model like GPT-4, they could identify relevant entities and the relationships between them. They then used a graph-based clustering algorithm called Leiden to group these entities into meaningful clusters or "communities" based on their connections. This allowed them to better understand how different concepts are related in the astronomical domain.
For example, if the model identified that the terms "star," "galaxy," and "black hole" often appeared together, it could infer that they are closely related concepts in the field of astronomy. By understanding these relationships, researchers can more easily navigate and make sense of the wealth of information contained in astronomical literature.
Technical Explanation
The researchers used a multi-step approach to extract entities and relationships from astronomical text:
-
Entity and Relationship Extraction: They collected excerpts of text around specific entities (e.g., names of stars, planets, scientific concepts) and used the GPT-4 language model to identify relevant entities and the relationships between them. This process is similar to the techniques described in this paper on entity disambiguation.
-
Knowledge Graph Construction: The extracted entities and relationships were then used to construct a knowledge graph, which is a structured way of representing information as a network of interconnected nodes (entities) and edges (relationships).
-
Knowledge Graph Clustering: The researchers applied the Leiden algorithm, a community detection technique, to the knowledge graph. This allowed them to identify clusters or "communities" of related entities, which helped to disambiguate entities that may have appeared in multiple contexts.
-
Percentage of Association: To further improve entity disambiguation, the researchers calculated the percentage of association between unknown excerpts and the identified Leiden communities. This helped to determine which community, and therefore which set of related entities, the unknown excerpt was most closely associated with.
The researchers demonstrated the effectiveness of this approach through experiments on astronomical text, showing its ability to accurately identify and disambiguate entities, as well as to uncover meaningful relationships between them. This work builds on previous research exploring the interplay between large language models and knowledge graph techniques for information extraction and understanding.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper:
- The approach relies on the quality and accuracy of the underlying language model (GPT-4) and the knowledge graph construction process. Improvements in these components could lead to better entity and relationship extraction.
- The study focused on the astronomical domain, and the generalizability of the approach to other domains is yet to be explored. Further research is needed to understand how well the techniques can be applied to other scientific or technical fields.
- The paper does not provide a detailed evaluation of the accuracy and reliability of the entity disambiguation and relationship extraction. More extensive testing and comparison to other methods would help to better assess the performance of the proposed approach.
Additionally, one potential concern is the reliance on large language models, which have been shown to exhibit biases and limitations. Careful consideration should be given to the potential pitfalls of over-reliance on these models, and efforts should be made to ensure the robustness and reliability of the information extracted.
Conclusion
This paper presents an innovative approach to leveraging large language models and knowledge graph clustering techniques for extracting and disambiguating entities and relationships from astronomical text. By combining these powerful tools, the researchers demonstrate the potential to gain deeper insights and understanding of the complex concepts and connections within scientific literature.
The results highlight the effectiveness of this approach in identifying relevant entities and grouping them into meaningful clusters based on their relationships. While the study is focused on the astronomical domain, the techniques could potentially be applied to other scientific and technical fields, contributing to more efficient and accurate information extraction and knowledge representation.
As the volume of scientific data continues to grow, tools like the one presented in this paper will become increasingly valuable in helping researchers navigate and make sense of the vast amount of information available. Further research and refinement of these techniques could lead to significant advancements in our ability to extract and synthesize knowledge from the ever-expanding corpus of scientific literature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
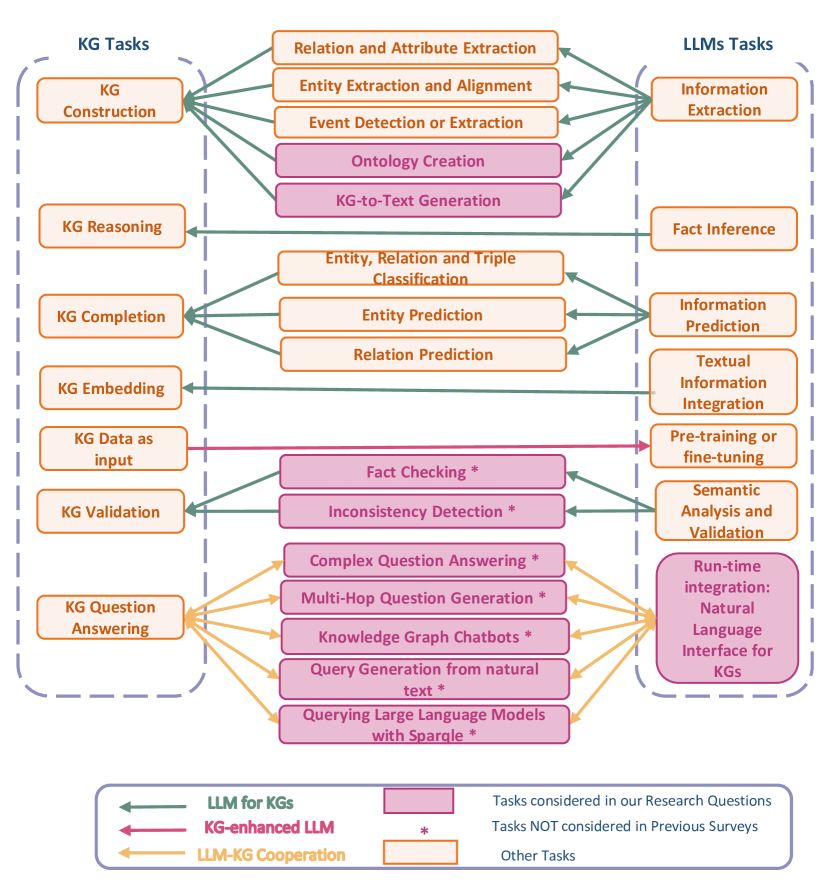
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
Disambiguate Entity Matching using Large Language Models through Relation Discovery
Zezhou Huang
0
0
Entity matching is a critical challenge in data integration and cleaning, central to tasks like fuzzy joins and deduplication. Traditional approaches have focused on overcoming fuzzy term representations through methods such as edit distance, Jaccard similarity, and more recently, embeddings and deep neural networks, including advancements from large language models (LLMs) like GPT. However, the core challenge in entity matching extends beyond term fuzziness to the ambiguity in defining what constitutes a match, especially when integrating with external databases. This ambiguity arises due to varying levels of detail and granularity among entities, complicating exact matches. We propose a novel approach that shifts focus from purely identifying semantic similarities to understanding and defining the relations between entities as crucial for resolving ambiguities in matching. By predefining a set of relations relevant to the task at hand, our method allows analysts to navigate the spectrum of similarity more effectively, from exact matches to conceptually related entities.
5/30/2024
🧠
HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
Pranoy Panda, Ankush Agarwal, Chaitanya Devaguptapu, Manohar Kaul, Prathosh A P
0
0
Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
6/11/2024
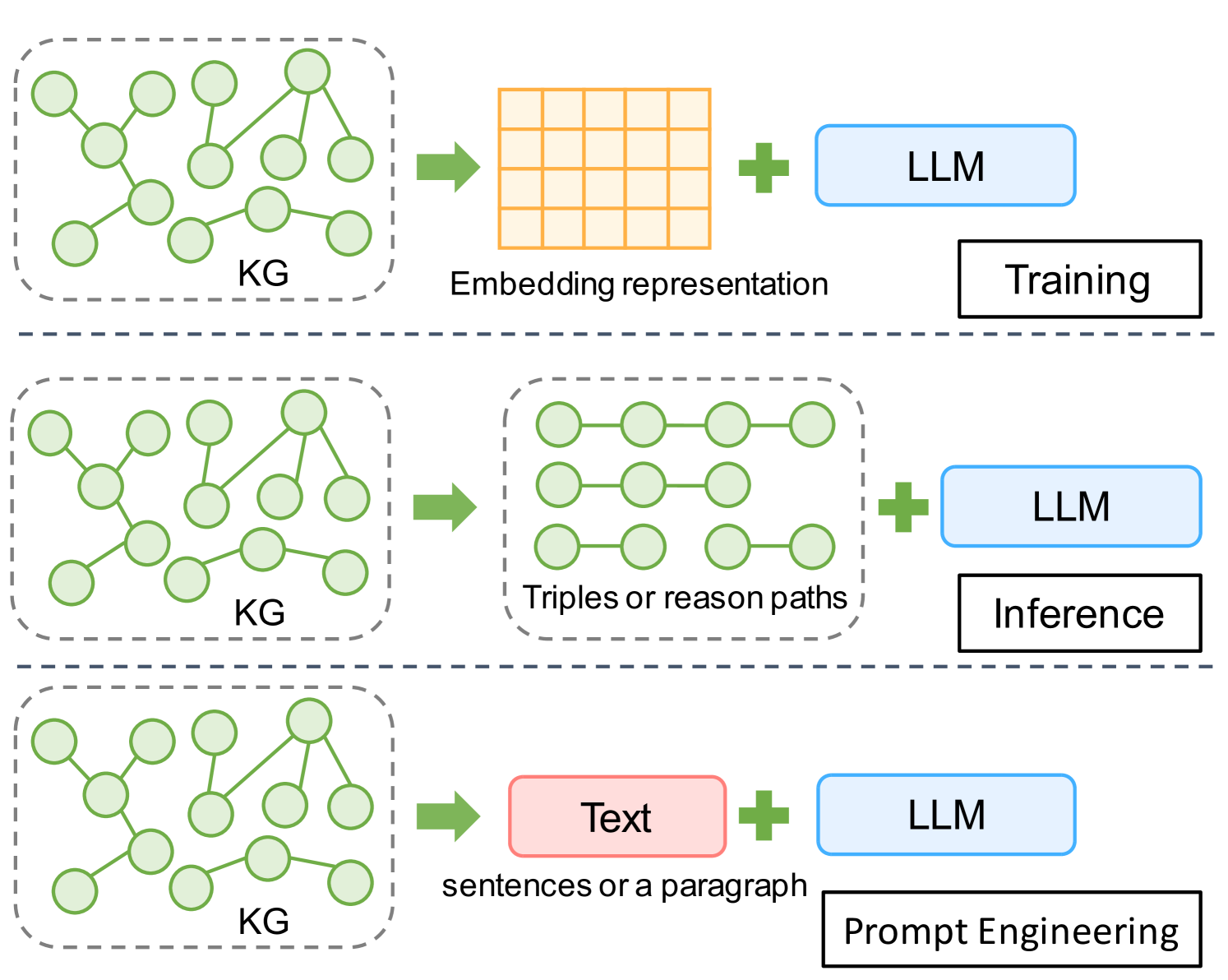
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024