HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
2406.06027
0
0
🧠
Abstract
Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
Create account to get full access
Overview
- Large Language Models (LLMs) are skilled at answering simple questions, but struggle with more complex, multi-step queries.
- This is due to the difficulty of understanding the complex question and then filtering and combining information from unstructured text.
- Recent approaches have tried to integrate structured knowledge (in the form of triples) into the text, but this is not tailored to the specific query and the extracted facts lack context.
- To address these issues, the researchers propose using a compressed, distilled knowledge graph that is focused on the relevant information for answering the given query.
Plain English Explanation
Large language models are very good at answering basic questions where the answer can be found in a single piece of information. However, when the questions get more complex and require combining multiple pieces of information, these models start to struggle. The researchers believe this is because the models have a hard time both understanding the complex question and then finding and putting together all the relevant information from the unstructured text.
To try to make this process easier, some recent methods have added structured knowledge in the form of "triples" (basic facts like "dog - is a - animal") to the text. But this approach is not tailored to the specific question being asked, so the extracted facts may not be very useful. Plus, the facts are taken out of context, so it's hard for the model to really understand their meaning.
To solve this problem, the researchers developed a knowledge graph - a structured way of representing information and the connections between different concepts. Crucially, they "distilled" and compressed this knowledge graph to only include the information that is actually relevant to answering the given question. This allows the language model to focus on the key facts it needs, rather than having to sift through a lot of extraneous information.
Technical Explanation
The researchers propose a method that uses a compressed, distilled knowledge graph (KG) as input to a large language model (LLM) to improve its ability to answer complex, multi-hop questions.
Compared to the state-of-the-art approach, their method is able to represent the query-relevant information from the supporting documents using up to 67% fewer tokens. This is achieved by:
- Constructing a comprehensive knowledge graph from the raw text.
- Distilling this KG to only include information that is directly relevant to answering the given query, based on the knowledge paths needed to arrive at the answer.
- Compressing the distilled KG to further reduce the token count while preserving the necessary information.
The compressed, distilled KG is then provided as input to the LLM, alongside the original question. The experiments show that this approach leads to consistent improvements over the state-of-the-art on several benchmark datasets for complex, multi-hop question answering.
Critical Analysis
The researchers have presented a novel approach to leveraging structured knowledge to improve the performance of LLMs on complex questions. By distilling the knowledge graph to only include information relevant to the query, they are able to provide the model with a more concise and focused representation of the necessary facts and relationships.
However, the paper does not explore the limitations of this approach. For example, it's unclear how well the method would scale to very large knowledge graphs or a broad range of question types. There is also no discussion of the potential for the distillation process to introduce bias or lose important contextual information.
Additionally, while the results show improvements over the state-of-the-art, the absolute performance on the benchmark tasks is still far from perfect. This suggests that there is room for further research to fully unlock the potential of combining LLMs with knowledge graphs to handle complex, multi-hop questions.
Conclusion
This research presents a promising approach to enhancing the ability of large language models to answer complex, multi-step questions. By distilling a comprehensive knowledge graph down to only the most relevant information, the model is able to focus on the key facts and relationships needed to arrive at the correct answer.
The significant reduction in the number of tokens required to represent the supporting information, combined with the consistent performance improvements on benchmark datasets, suggests that this method could be a valuable tool for building more capable question-answering systems. As the field of AI continues to push the boundaries of what language models can achieve, techniques like this that combine structured knowledge with powerful language understanding will likely play an important role.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
0
0
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
5/1/2024
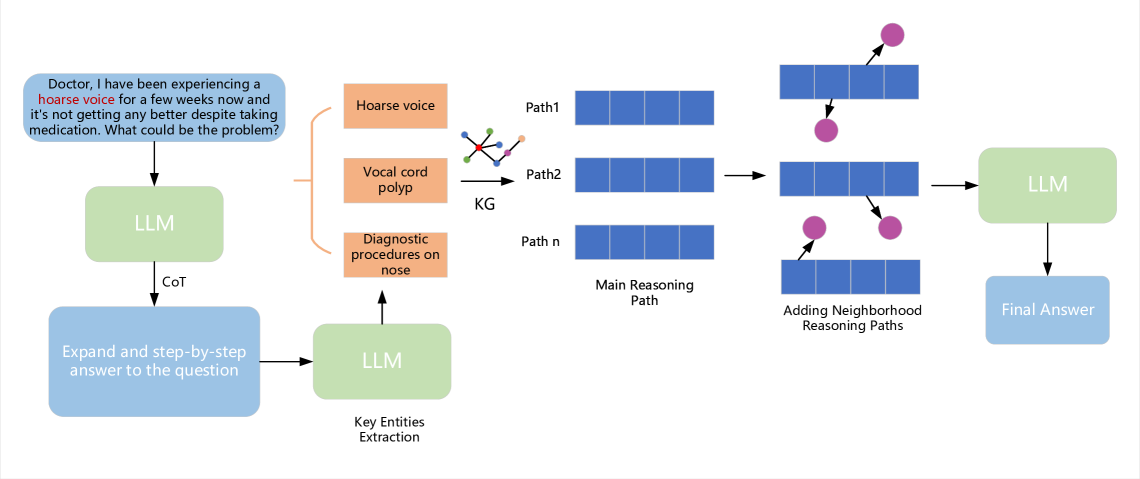
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
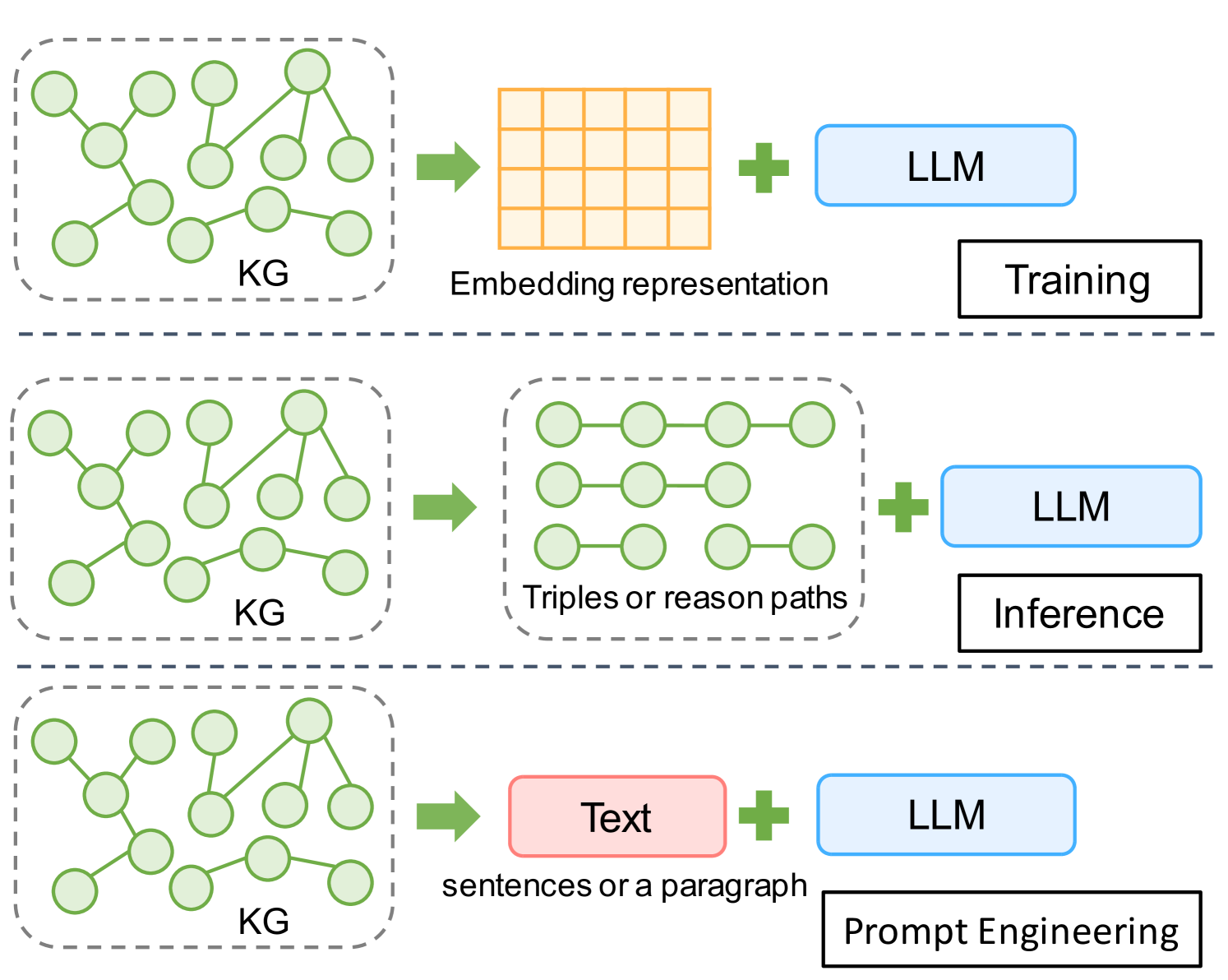
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024

Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Tuan Bui, Oanh Tran, Phuong Nguyen, Bao Ho, Long Nguyen, Thang Bui, Tho Quan
0
0
In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
4/16/2024