Large language models surpass human experts in predicting neuroscience results
2403.03230
2
0
Abstract
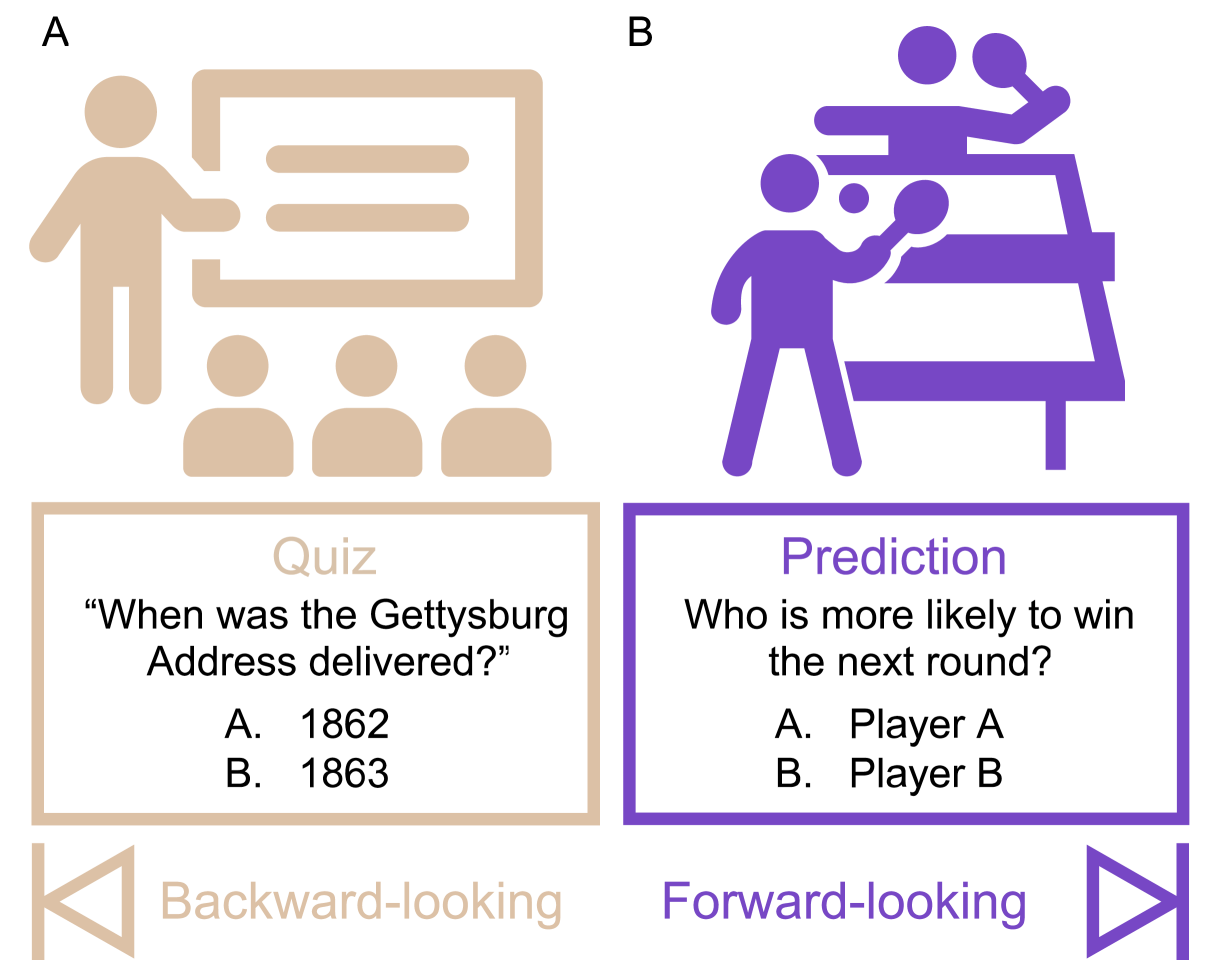
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Create account to get full access
Overview
- Large language models (LLMs) outperform human neuroscience experts on a benchmark task
- The study examined how well LLMs and human experts perform on predicting results from neuroscience experiments
- Findings show that general-purpose LLMs like GPT-3 can surpass the predictive accuracy of trained neuroscientists on the BrainBench evaluation
Plain English Explanation
In this research, the authors compared the abilities of large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to the abilities of human neuroscience experts. They found that LLMs like GPT-3 were able to outperform the neuroscientists at predicting the results of neuroscience experiments. This suggests that these AI models, even without being specifically trained on neuroscience, have developed a deep understanding of the brain and how it works.
The researchers used a benchmark called BrainBench, which includes a variety of neuroscience-related tasks like predicting brain activity patterns or behavioral responses. They found that the general-purpose LLMs were able to make more accurate predictions than the human neuroscience experts on this evaluation. This is quite remarkable, as the language models were not designed or trained for neuroscience applications - they were trained more broadly on a huge amount of text data from the internet. Yet they were still able to outperform the specialists in this domain.
This work adds to a growing body of research showing that large language models can surpass human experts in certain specialized tasks, even without being explicitly trained on that subject matter. It suggests that these powerful AI systems may be developing a sophisticated, general understanding of the world that allows them to excel at a wide variety of specialized tasks.
Technical Explanation
The researchers evaluated the performance of several large language models, including GPT-3 and GPT-J, on the BrainBench benchmark. BrainBench consists of a suite of neuroscience-related prediction tasks, such as predicting brain activity patterns from stimuli or behavioral responses from brain activity.
The language models were fine-tuned on the BrainBench training data using a few-shot learning approach. This involved training the models on just a small number of examples, rather than doing full end-to-end training from scratch. The fine-tuned models were then evaluated on held-out test sets and their performance was compared to that of human neuroscience experts who had also completed the BrainBench tasks.
The results showed that the general-purpose language models were able to outperform the human experts across a range of BrainBench subtasks, including those related to cognitive neuroscience, neuroimaging, and computational neuroscience. This was true even though the language models had not been explicitly trained on neuroscience data.
The researchers hypothesize that the language models' strong performance is due to their ability to leverage deep, general-purpose knowledge about the world, which allows them to make inferences and draw connections that human experts may miss. The models' Bayesian statistical modeling capabilities may also contribute to their success on these predictive neuroscience tasks.
Critical Analysis
The results presented in this paper are quite impressive, showing that large language models can outperform human neuroscience experts on a range of prediction tasks. However, the authors acknowledge several important limitations and caveats to their findings.
First, the BrainBench dataset, while comprehensive, may not fully capture the breadth and complexity of real-world neuroscience problems. The tasks involved are relatively narrow and specific, whereas in practice, neuroscientists often need to draw insights from broader contexts and make holistic judgments.
Additionally, the human experts that participated in the BrainBench evaluation were not necessarily representative of the entire neuroscience field. They may have had varying levels of experience and expertise, and their performance could have been influenced by factors like fatigue or time constraints during the study.
It's also unclear how well the language models would generalize to entirely novel neuroscience domains or experimental paradigms that are very different from the training data. Their strong performance may be limited to the specific types of tasks included in the benchmark.
Further research is needed to better understand the mechanisms underlying the language models' success, and to explore how these findings might translate to real-world neuroscience applications. Collaborations between AI researchers and neuroscientists will be crucial for advancing our understanding in this area.
Conclusion
This study provides compelling evidence that large language models can surpass human experts in predicting the results of neuroscience experiments, even without being specifically trained on neuroscience data. The findings suggest that these powerful AI systems may be developing a deep, general understanding of the world that allows them to excel at a wide variety of specialized tasks.
While the results are impressive, it's important to consider the limitations and caveats discussed. Continuing research in this area, with close collaboration between AI and neuroscience researchers, will be crucial for understanding the full potential and limitations of language models in this domain. Ultimately, these findings could have significant implications for how we approach neuroscience research and the development of AI systems that can assist and augment human experts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Matching domain experts by training from scratch on domain knowledge
Xiaoliang Luo, Guangzhi Sun, Bradley C. Love
0
0
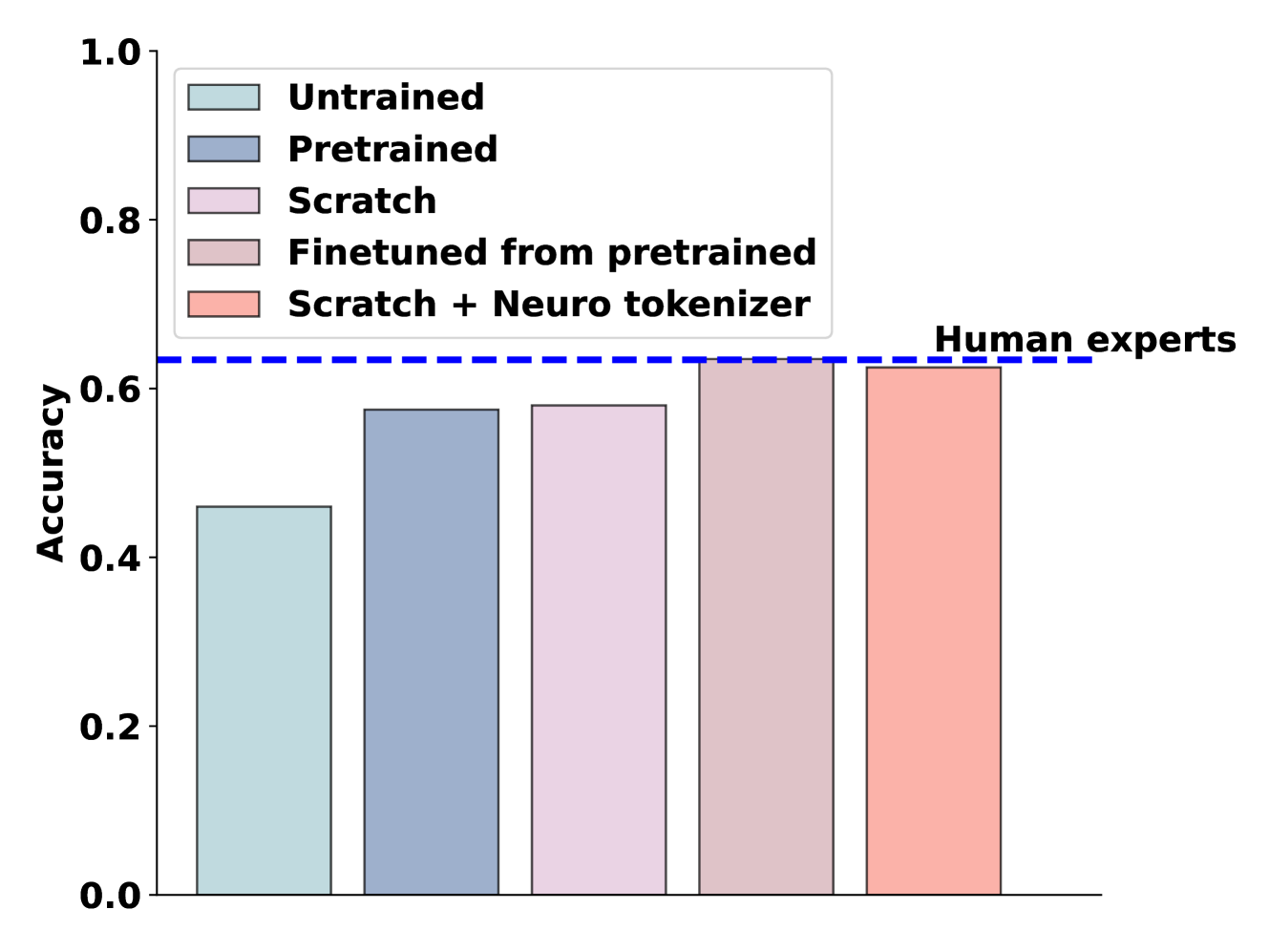
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
5/16/2024
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
0
0
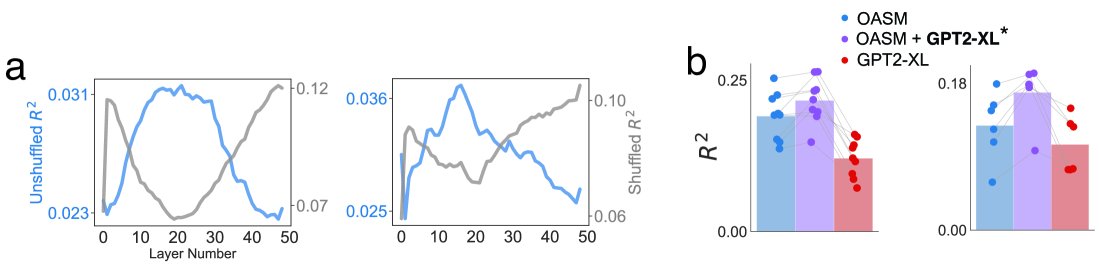
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
6/24/2024
💬
Are large language models superhuman chemists?
Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Benedict Emoekabu, Aswanth Krishnan, Mara Wilhelmi, Macjonathan Okereke, Juliane Eberhardt, Amir Mohammad Elahi, Maximilian Greiner, Caroline T. Holick, Tanya Gupta, Mehrdad Asgari, Christina Glaubitz, Lea C. Klepsch, Yannik Koster, Jakob Meyer, Santiago Miret, Tim Hoffmann, Fabian Alexander Kreth, Michael Ringleb, Nicole Roesner, Ulrich S. Schubert, Leanne M. Stafast, Dinga Wonanke, Michael Pieler, Philippe Schwaller, Kevin Maik Jablonka
0
0
Large language models (LLMs) have gained widespread interest due to their ability to process human language and perform tasks on which they have not been explicitly trained. This is relevant for the chemical sciences, which face the problem of small and diverse datasets that are frequently in the form of text. LLMs have shown promise in addressing these issues and are increasingly being harnessed to predict chemical properties, optimize reactions, and even design and conduct experiments autonomously. However, we still have only a very limited systematic understanding of the chemical reasoning capabilities of LLMs, which would be required to improve models and mitigate potential harms. Here, we introduce ChemBench, an automated framework designed to rigorously evaluate the chemical knowledge and reasoning abilities of state-of-the-art LLMs against the expertise of human chemists. We curated more than 7,000 question-answer pairs for a wide array of subfields of the chemical sciences, evaluated leading open and closed-source LLMs, and found that the best models outperformed the best human chemists in our study on average. The models, however, struggle with some chemical reasoning tasks that are easy for human experts and provide overconfident, misleading predictions, such as about chemicals' safety profiles. These findings underscore the dual reality that, although LLMs demonstrate remarkable proficiency in chemical tasks, further research is critical to enhancing their safety and utility in chemical sciences. Our findings also indicate a need for adaptations to chemistry curricula and highlight the importance of continuing to develop evaluation frameworks to improve safe and useful LLMs.
4/3/2024
🤿
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
0
0
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
6/14/2024