Matching domain experts by training from scratch on domain knowledge
2405.09395
0
0
Abstract
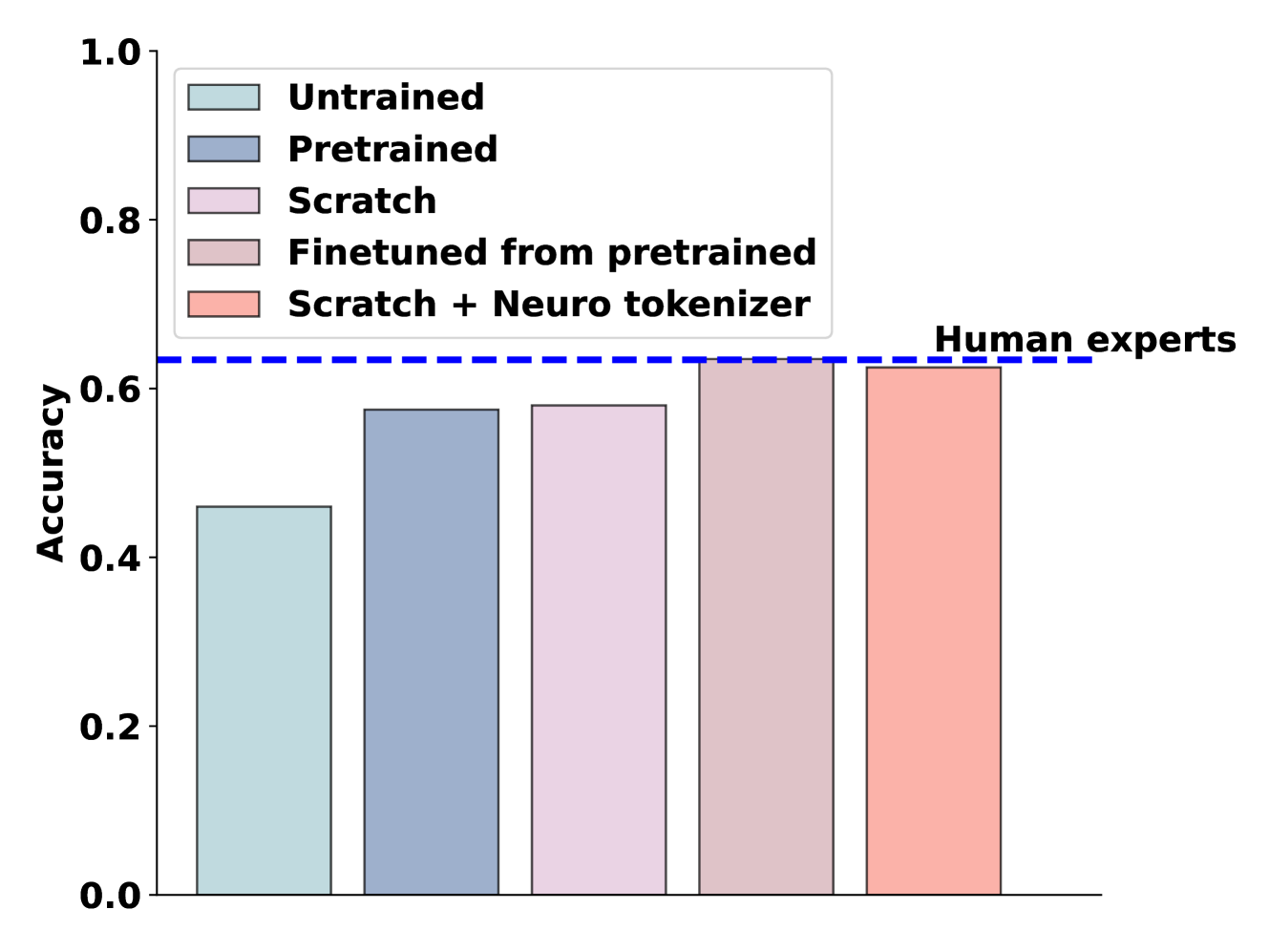
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
Create account to get full access
Overview
- This paper investigates a novel approach to matching domain experts by training large language models (LLMs) from scratch on domain-specific knowledge.
- The researchers aim to assess whether LLMs can be trained to perform on par with human experts in specific domains, without relying on pre-trained models.
- The study explores the potential for LLMs to serve as scalable and cost-effective alternatives to human experts for certain tasks.
Plain English Explanation
The researchers in this study wanted to see if they could train large language models (LLMs) - powerful AI systems that can understand and generate human-like text - to be as knowledgeable and capable as human experts in specific subject areas. ^1 Instead of starting with a pre-trained LLM and fine-tuning it, they trained the models entirely from scratch using only domain-specific information.
The core idea is that if LLMs can be trained this way, they could potentially serve as scalable and cost-effective replacements for human experts in certain tasks. Rather than relying on a limited number of human experts, a well-trained LLM could be deployed more widely to provide expert-level insights and analysis.
The researchers wanted to rigorously test this approach to see how the LLM's performance compares to that of actual domain experts. By training the LLM from the ground up on relevant knowledge, they hope to push the boundaries of what these AI systems are capable of.
Technical Explanation
The researchers developed a novel training approach to imbue LLMs with domain-specific expertise. Rather than starting with a pre-trained LLM and fine-tuning it on a smaller amount of domain data, they trained the models entirely from scratch using only the relevant domain knowledge. ^2
This training process involved compiling a comprehensive dataset of domain-specific information, including academic papers, textbooks, and other authoritative sources. The researchers then used this data to train the LLMs using standard language modeling techniques.
The key innovation was to train the LLMs in a way that closely mirrored how human experts acquire and apply their knowledge. By immersing the models in the same domain-specific information that experts study, the researchers aimed to imbue the LLMs with comparable levels of understanding and reasoning ability.
To evaluate the performance of the trained LLMs, the researchers designed a series of experiments that pitted the models against human domain experts on a variety of relevant tasks. This allowed them to directly compare the LLMs' capabilities to those of the experts, providing valuable insights into the strengths and limitations of the AI-based approach.
Critical Analysis
The researchers acknowledge several important caveats and limitations to their approach. First, the success of the training process is heavily dependent on the quality and comprehensiveness of the domain-specific dataset used. If the dataset is incomplete or biased, the resulting LLM may not achieve true expert-level performance.
Additionally, the researchers note that their study focused on a relatively narrow set of domains, and it's unclear whether the same training approach would be effective across a broader range of subject areas. Further research would be needed to assess the generalizability of the method.
Another potential concern is the interpretability and transparency of the trained LLMs. As with many AI systems, it can be challenging to fully understand the inner workings and decision-making process of the models. This could limit their usefulness in certain high-stakes or safety-critical applications where transparency is paramount. ^3
Despite these limitations, the researchers make a compelling case for the potential of this approach to serve as a scalable and cost-effective alternative to human experts in selected domains. By pushing the boundaries of what LLMs can achieve, this study contributes valuable insights to the ongoing discussion around the capabilities and limitations of large language models.
Conclusion
This study presents a novel approach to training large language models (LLMs) from scratch on domain-specific knowledge, with the goal of enabling these AI systems to perform on par with human experts. The researchers demonstrate that by immersing the LLMs in comprehensive datasets of domain information, they can imbue the models with comparable levels of understanding and reasoning ability.
The potential implications of this work are significant. If LLMs can be reliably trained to match the performance of human experts, it could lead to the development of scalable and cost-effective alternatives to human-based expertise in certain domains. This could have far-reaching impacts on fields like scientific research, medical diagnosis, and policy decision-making, where expert knowledge is in high demand but limited supply.
However, the researchers also acknowledge the limitations and challenges of their approach, including the need for high-quality training data and the potential issues around model interpretability. Addressing these concerns will be crucial as this line of research continues to evolve. [^4]
Overall, this study represents an important step forward in the ongoing quest to push the boundaries of what large language models can achieve, with potentially significant implications for the future of human-AI collaboration and the democratization of expert knowledge.
[^4]: https://aimodels.fyi/papers/arxiv/zero-shot-few-shot-study-instruction-finetuned, https://aimodels.fyi/papers/arxiv/domain-specific-improvement-psychotherapy-chatbot-using-assistant
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large language models surpass human experts in predicting neuroscience results
Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K. Nejad, Felipe Y'a~nez, Bati Yilmaz, Kangjoo Lee, Alexandra O. Cohen, Valentina Borghesani, Anton Pashkov, Daniele Marinazzo, Jonathan Nicholas, Alessandro Salatiello, Ilia Sucholutsky, Pasquale Minervini, Sepehr Razavi, Roberta Rocca, Elkhan Yusifov, Tereza Okalova, Nianlong Gu, Martin Ferianc, Mikail Khona, Kaustubh R. Patil, Pui-Shee Lee, Rui Mata, Nicholas E. Myers, Jennifer K Bizley, Sebastian Musslick, Isil Poyraz Bilgin, Guiomar Niso, Justin M. Ales, Michael Gaebler, N Apurva Ratan Murty, Leyla Loued-Khenissi, Anna Behler, Chloe M. Hall, Jessica Dafflon, Sherry Dongqi Bao, Bradley C. Love
0
0
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
6/24/2024
Self-Specialization: Uncovering Latent Expertise within Large Language Models
Junmo Kang, Hongyin Luo, Yada Zhu, Jacob Hansen, James Glass, David Cox, Alan Ritter, Rogerio Feris, Leonid Karlinsky
0
0
Recent works have demonstrated the effectiveness of self-alignment in which a large language model is aligned to follow general instructions using instructional data generated from the model itself starting from a handful of human-written seeds. Instead of general alignment, in this work, we focus on self-alignment for expert domain specialization (e.g., biomedicine, finance). As a preliminary, we quantitively show the marginal effect that generic instruction-following training has on downstream expert domains' performance. To remedy this, we propose self-specialization - allowing for effective model specialization while achieving cross-task generalization by leveraging only a few labeled seeds. Self-specialization offers a data- and parameter-efficient way of carving out an expert model out of a generalist pre-trained LLM. Exploring a variety of popular open large models as a base for specialization, our experimental results in both biomedical and financial domains show that our self-specialized models outperform their base models by a large margin, and even larger models that are generally instruction-tuned or that have been adapted to the target domain by other means.
6/7/2024
💬
Large Language Models Perform on Par with Experts Identifying Mental Health Factors in Adolescent Online Forums
Isabelle Lorge, Dan W. Joyce, Andrey Kormilitzin
0
0
Mental health in children and adolescents has been steadily deteriorating over the past few years. The recent advent of Large Language Models (LLMs) offers much hope for cost and time efficient scaling of monitoring and intervention, yet despite specifically prevalent issues such as school bullying and eating disorders, previous studies on have not investigated performance in this domain or for open information extraction where the set of answers is not predetermined. We create a new dataset of Reddit posts from adolescents aged 12-19 annotated by expert psychiatrists for the following categories: TRAUMA, PRECARITY, CONDITION, SYMPTOMS, SUICIDALITY and TREATMENT and compare expert labels to annotations from two top performing LLMs (GPT3.5 and GPT4). In addition, we create two synthetic datasets to assess whether LLMs perform better when annotating data as they generate it. We find GPT4 to be on par with human inter-annotator agreement and performance on synthetic data to be substantially higher, however we find the model still occasionally errs on issues of negation and factuality and higher performance on synthetic data is driven by greater complexity of real data rather than inherent advantage.
4/29/2024

LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law
Toni J. B. Liu, Nicolas Boull'e, Raphael Sarfati, Christopher J. Earls
0
0
Pretrained large language models (LLMs) are surprisingly effective at performing zero-shot tasks, including time-series forecasting. However, understanding the mechanisms behind such capabilities remains highly challenging due to the complexity of the models. We study LLMs' ability to extrapolate the behavior of dynamical systems whose evolution is governed by principles of physical interest. Our results show that LLaMA 2, a language model trained primarily on texts, achieves accurate predictions of dynamical system time series without fine-tuning or prompt engineering. Moreover, the accuracy of the learned physical rules increases with the length of the input context window, revealing an in-context version of neural scaling law. Along the way, we present a flexible and efficient algorithm for extracting probability density functions of multi-digit numbers directly from LLMs.
6/24/2024