Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
2404.16563
0
0
💬
Abstract
Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a framework for rigorously evaluating the capabilities of Large Language Models (LLMs) on time series analysis and understanding.
- The researchers introduce a comprehensive taxonomy of time series features and use it to systematically design and synthesize a diverse dataset for assessing LLM performance.
- The experiments shed light on the strengths and limitations of state-of-the-art LLMs in comprehending various time series characteristics, including sensitivity to data formatting, query position, and series length.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can process and generate human-like text. The researchers believe these models could be useful for automatically analyzing and reporting on time series data, which is essential in fields like healthcare, finance, climate, and energy.
To test how well LLMs can handle time series data, the researchers created a detailed taxonomy (or classification system) that describes the different features and characteristics that time series data can have. Using this taxonomy, they designed a diverse dataset of time series examples, covering a wide range of these features.
The researchers then tested several state-of-the-art LLMs on this dataset, to see how well the models could understand and work with the different time series characteristics. The results showed that the LLMs have some strengths in comprehending time series data, but also have notable limitations. For example, the models were sensitive to how the data was formatted, where in the series a query was made, and how long the overall time series was.
Overall, this research provides important insights into the current capabilities and shortcomings of LLMs when it comes to time series analysis and understanding. This can help guide the development of more powerful AI systems for working with time-dependent data in the future.
Technical Explanation
The researchers propose a framework for evaluating the capabilities of LLMs on time series understanding. They introduce a comprehensive taxonomy of time series features, which delineates the various characteristics inherent in time series data. Leveraging this taxonomy, the team systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features.
The researchers then conducted experiments to assess the proficiency of state-of-the-art LLMs in comprehending time series. The results revealed the strengths and limitations of these models, showing which time series features they readily understand and where they falter. The experiments also uncovered the sensitivity of LLMs to factors like data formatting, query position, and series length.
Critical Analysis
The paper provides a robust and systematic approach to evaluating LLM capabilities on time series understanding, which is a critical task across many domains. The carefully designed taxonomy and dataset offer a solid foundation for assessing model performance.
However, the researchers acknowledge that their experiments focused on a limited set of LLMs and time series characteristics. There may be other factors, such as the specific application domain or the way the time series data is presented to the models, that could also impact performance. Further research is needed to explore these additional variables.
Additionally, the paper does not delve deeply into the underlying reasons why the LLMs struggled with certain time series features. Understanding the specific challenges and limitations of these models could inform the development of more effective techniques for time series analysis and forecasting.
Conclusion
This research represents an important step towards understanding the capabilities and limitations of LLMs when it comes to time series analysis and understanding. The findings suggest that while these models show promise, there is still work to be done to fully leverage their potential for automating time series tasks. The insights from this paper can help guide the development of more robust and versatile AI systems for working with time-dependent data in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024

A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Mode
Jiexia Ye, Weiqi Zhang, Ke Yi, Yongzi Yu, Ziyue Li, Jia Li, Fugee Tsung
0
0
Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).
5/8/2024
Language Models Still Struggle to Zero-shot Reason about Time Series
Mike A. Merrill, Mingtian Tan, Vinayak Gupta, Tom Hartvigsen, Tim Althoff
0
0
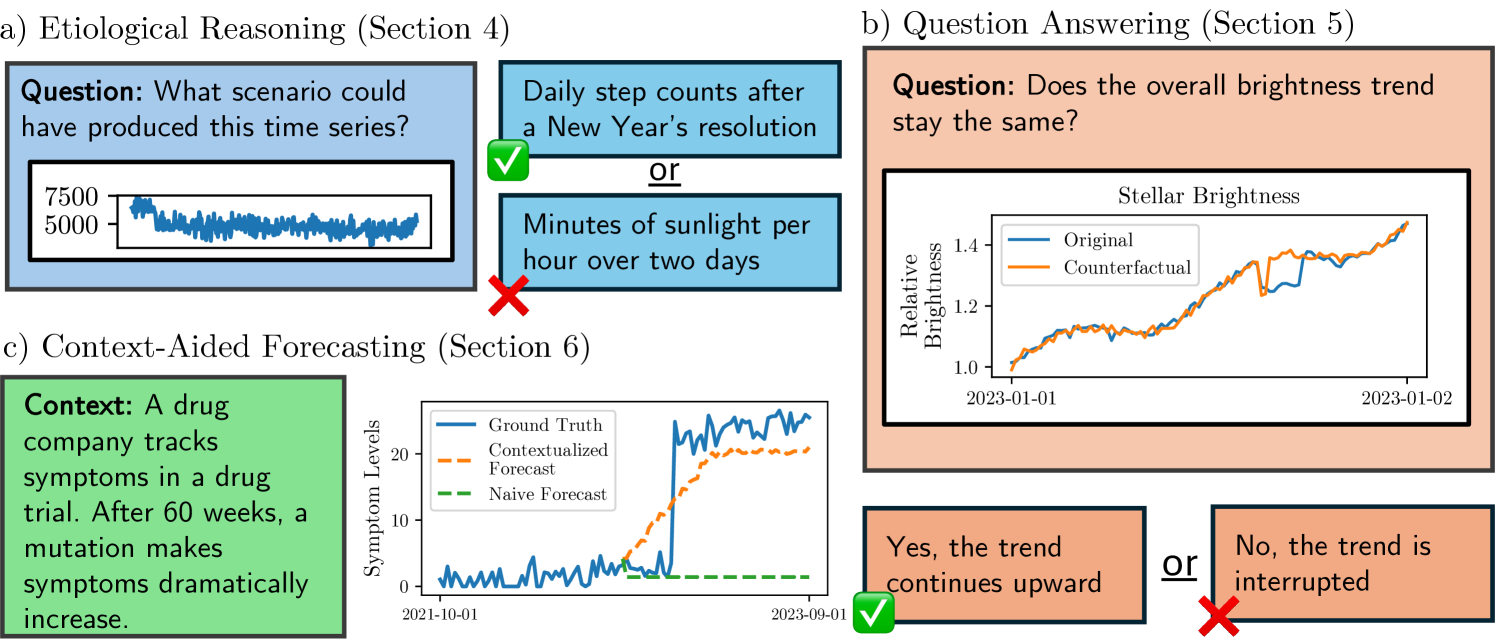
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
4/19/2024