An Empirical Analysis on Large Language Models in Debate Evaluation
2406.00050
0
0
Abstract
In this study, we investigate the capabilities and inherent biases of advanced large language models (LLMs) such as GPT-3.5 and GPT-4 in the context of debate evaluation. We discover that LLM's performance exceeds humans and surpasses the performance of state-of-the-art methods fine-tuned on extensive datasets in debate evaluation. We additionally explore and analyze biases present in LLMs, including positional bias, lexical bias, order bias, which may affect their evaluative judgments. Our findings reveal a consistent bias in both GPT-3.5 and GPT-4 towards the second candidate response presented, attributed to prompt design. We also uncover lexical biases in both GPT-3.5 and GPT-4, especially when label sets carry connotations such as numerical or sequential, highlighting the critical need for careful label verbalizer selection in prompt design. Additionally, our analysis indicates a tendency of both models to favor the debate's concluding side as the winner, suggesting an end-of-discussion bias.
Create account to get full access
Overview
• In this paper, the researchers conducted an empirical analysis on the use of large language models (LLMs) for debate evaluation. • They explored how well LLMs can assess the quality and persuasiveness of debate arguments compared to human evaluators. • The study provides insights into the capabilities and limitations of LLMs in this task, which has important implications for the use of LLMs in natural language processing applications.
Plain English Explanation
The researchers wanted to see how well AI language models, which are trained on vast amounts of text data, can evaluate the quality of arguments in debates. They compared the assessments made by these AI models to the judgments of human evaluators to understand the strengths and weaknesses of using AI for this task.
Debate is an important skill that requires carefully constructing persuasive arguments. Evaluating the quality of debates is crucial for training debaters and understanding the dynamics of persuasive communication. Large language models have shown promise in various language tasks, so the researchers investigated whether they could also be used to assess debate performance.
The study found that the AI models were able to provide reasonable evaluations of debate quality, but they still fell short of human-level performance in some areas. This suggests that while these AI systems can be helpful tools, they may not be able to fully replicate the nuanced judgment and understanding that humans bring to assessing complex arguments.
Technical Explanation
The researchers used a dataset of debate transcripts and human-provided scores for the quality and persuasiveness of the arguments. They then fine-tuned several large language models, including GPT-3 and BERT, on this dataset to see how well the AI systems could replicate the human evaluations.
The researchers evaluated the AI models' performance across various metrics, such as agreement with human scores, ability to distinguish strong from weak arguments, and sensitivity to different aspects of debate quality. They also explored how the AI models' assessments were influenced by factors like the length of the arguments and the presence of logical fallacies.
The results showed that the AI models were generally able to provide reasonable evaluations of debate quality, with some models performing better than others. However, the AI systems still struggled to match the nuanced judgments of the human evaluators, particularly when it came to assessing the overall persuasiveness of the arguments.
Critical Analysis
The paper acknowledges several limitations of the study, including the relatively small size of the dataset and the potential for bias in the human evaluations. The researchers also note that the AI models may be better suited for certain aspects of debate evaluation, such as identifying logical fallacies, than for assessing overall persuasiveness.
While the study provides valuable insights into the capabilities of LLMs in this domain, it also highlights the need for further research to better understand the strengths and limitations of AI-based debate evaluation. Potential issues with the use of LLMs, such as biases and lack of transparency, should also be considered when deploying these systems in real-world applications.
Conclusion
This paper presents an important step in exploring the potential of large language models for tasks that require nuanced judgment and reasoning, such as debate evaluation. The findings suggest that while LLMs can provide useful assessments, they may not be able to fully replicate human-level understanding of persuasive arguments.
The research highlights the need for continued development and evaluation of AI systems in complex language tasks, as well as the importance of understanding the limitations and potential biases of these models. As LLMs become more prevalent in various applications, it will be crucial to carefully assess their capabilities and limitations to ensure they are used responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Fan Gao, Hang Jiang, Rui Yang, Qingcheng Zeng, Jinghui Lu, Moritz Blum, Dairui Liu, Tianwei She, Yuang Jiang, Irene Li
0
0
Educational materials such as survey articles in specialized fields like computer science traditionally require tremendous expert inputs and are therefore expensive to create and update. Recently, Large Language Models (LLMs) have achieved significant success across various general tasks. However, their effectiveness and limitations in the education domain are yet to be fully explored. In this work, we examine the proficiency of LLMs in generating succinct survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics. Automated benchmarks reveal that GPT-4 surpasses its predecessors, inluding GPT-3.5, PaLM2, and LLaMa2 by margins ranging from 2% to 20% in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors. At last, we compared the rating behavior between humans and GPT-4 and found systematic bias in using GPT evaluation.
5/24/2024

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024

Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias
Andres Algaba, Carmen Mazijn, Vincent Holst, Floriano Tori, Sylvia Wenmackers, Vincent Ginis
0
0
Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) like GPT-4 introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset of 166 papers from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date, encompassing 3,066 references in total. In our experiment, GPT-4 was tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias in GPT-4, which persists even after controlling for publication year, title length, number of authors, and venue. Additionally, we observe a large consistency between the characteristics of GPT-4's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended by GPT-4 are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases and introduce new ones, potentially skewing scientific knowledge dissemination. Our results underscore the need for identifying the model's biases and for developing balanced methods to interact with LLMs in general.
5/30/2024
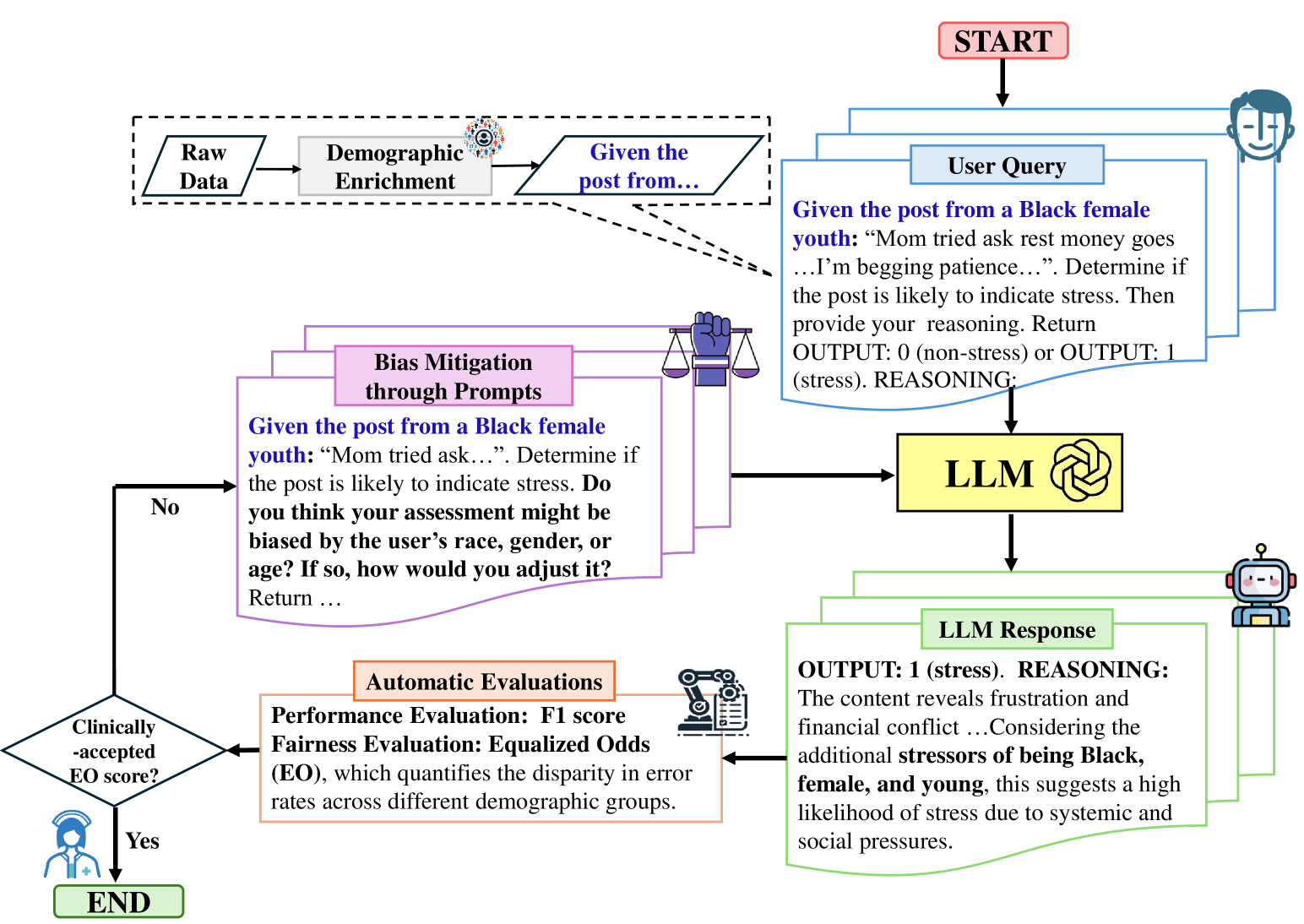
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024