Larger Language Models Don't Care How You Think: Why Chain-of-Thought Prompting Fails in Subjective Tasks

0
Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can generate human-like text.
- Chain-of-thought prompting is a technique used to get LLMs to engage in multi-step reasoning.
- This paper examines why chain-of-thought prompting fails for subjective tasks that require assessing emotions, morality, or personal preferences.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly capable at generating human-like text. Researchers have found that by giving these models a series of prompts that walk through a multi-step reasoning process, they can produce more coherent and insightful responses, a technique known as chain-of-thought prompting.
However, this paper argues that chain-of-thought prompting has limitations when it comes to subjective tasks that require assessing things like emotions, morality, or personal preferences. The authors suggest that LLMs, no matter how large, simply don't "care" about these subjective aspects in the same way humans do. The models are optimized to generate text that sounds plausible, but they don't have the same depth of understanding or internal experience that would be needed to truly reason about these types of subjective phenomena.
The paper provides examples showing how chain-of-thought prompting breaks down for tasks like evaluating the morality of an action or assessing the emotional impact of a situation. The models may be able to generate multi-step arguments, but their responses often miss the nuance and contextual understanding that would be required to make sound judgments on these subjective matters.
Technical Explanation
This paper investigates the limitations of chain-of-thought prompting when applied to subjective tasks that require reasoning about emotions, morality, or personal preferences. The authors argue that even the largest language models (LLMs) lack the inherent understanding of these subjective phenomena that would be needed to engage in coherent multi-step reasoning.
Through a series of experiments, the paper demonstrates how chain-of-thought prompting breaks down for tasks like evaluating the morality of an action or assessing the emotional impact of a situation. The models may be able to generate plausible-sounding multi-step arguments, but their responses often miss key nuances and fail to capture the depth of understanding that would be required to make sound judgments on these subjective matters.
The authors suggest that this limitation arises from the fact that LLMs are fundamentally optimized to generate text that sounds convincing, rather than to develop a true understanding of the subjective experiences and contextual factors that shape human reasoning about emotions, morality, and personal preferences. No matter how large the model, it cannot simply "care" about these subjective aspects in the same way a human would.
Critical Analysis
The paper raises important points about the limitations of current large language models (LLMs) when it comes to reasoning about subjective phenomena like emotions and morality. The authors make a compelling case that chain-of-thought prompting, while effective for certain types of reasoning tasks, breaks down when applied to more nuanced, context-dependent judgments.
One potential criticism is that the paper focuses primarily on demonstrating the failure of chain-of-thought prompting, without exploring in depth potential approaches to address these limitations. The authors acknowledge that LLMs may still have value for certain types of subjective tasks, but they do not provide much insight into how these models could be improved or augmented to better handle such challenges.
Additionally, the paper does not delve deeply into the broader implications of these findings for the development and deployment of large language models. As these models become more sophisticated and widespread, it will be crucial to understand their limitations and ensure they are not overapplied to domains where their weaknesses could have significant real-world consequences.
Further research is needed to explore alternative prompting techniques, architectural modifications, or complementary systems that could help LLMs better engage with the complexities of subjective human reasoning. Ongoing critical analysis and a clear-eyed assessment of the boundaries of these models' capabilities will be essential as the field of large language models continues to evolve.
Conclusion
This paper highlights a fundamental limitation of current large language models (LLMs) when it comes to reasoning about subjective phenomena like emotions, morality, and personal preferences. The authors demonstrate that chain-of-thought prompting, while effective for certain types of tasks, breaks down when applied to more nuanced, context-dependent judgments that require a deeper understanding of these subjective aspects of human experience.
The findings in this paper serve as an important reminder that even the most advanced LLMs are still fundamentally optimized to generate plausible-sounding text, rather than to develop a true, contextual understanding of the subjective factors that shape human reasoning. As these models become more capable and widespread, it will be crucial for researchers and practitioners to carefully consider their limitations and ensure they are not overextended into domains where their weaknesses could have significant real-world consequences.
Ongoing critical analysis and the development of new techniques to address the challenges highlighted in this paper will be essential for unlocking the full potential of large language models while also ensuring they are deployed responsibly and ethically.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Larger Language Models Don't Care How You Think: Why Chain-of-Thought Prompting Fails in Subjective Tasks
Georgios Chochlakis, Niyantha Maruthu Pandiyan, Kristina Lerman, Shrikanth Narayanan
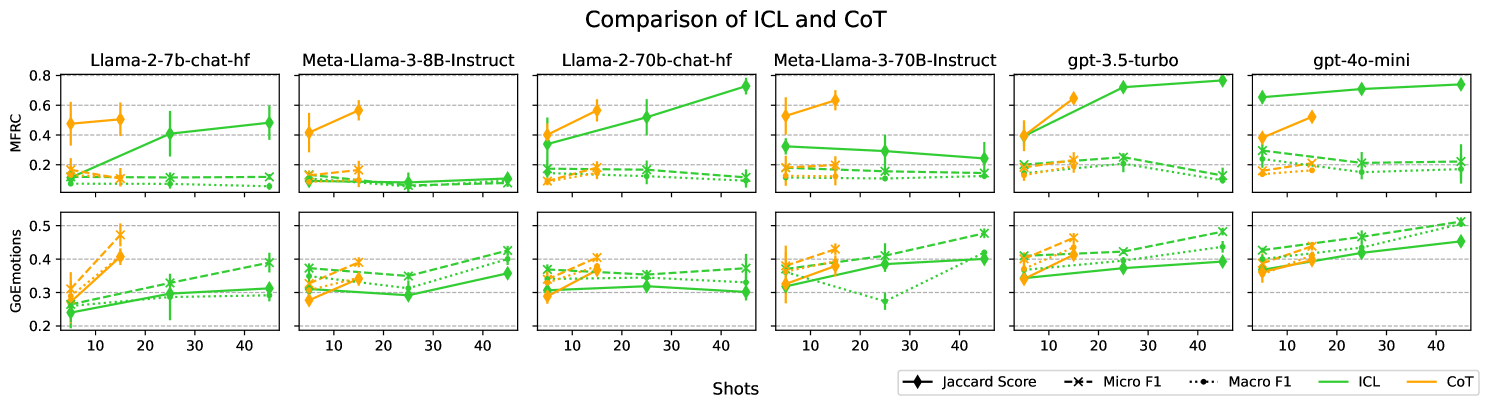
In-Context Learning (ICL) in Large Language Models (LLM) has emerged as the dominant technique for performing natural language tasks, as it does not require updating the model parameters with gradient-based methods. ICL promises to adapt the LLM to perform the present task at a competitive or state-of-the-art level at a fraction of the computational cost. ICL can be augmented by incorporating the reasoning process to arrive at the final label explicitly in the prompt, a technique called Chain-of-Thought (CoT) prompting. However, recent work has found that ICL relies mostly on the retrieval of task priors and less so on learning to perform tasks, especially for complex subjective domains like emotion and morality, where priors ossify posterior predictions. In this work, we examine whether enabling reasoning also creates the same behavior in LLMs, wherein the format of CoT retrieves reasoning priors that remain relatively unchanged despite the evidence in the prompt. We find that, surprisingly, CoT indeed suffers from the same posterior collapse as ICL for larger language models. Code is avalaible at https://github.com/gchochla/cot-priors.
Read more9/18/2024
💬
0
Active Prompting with Chain-of-Thought for Large Language Models
Shizhe Diao, Pengcheng Wang, Yong Lin, Rui Pan, Xiang Liu, Tong Zhang
The increasing scale of large language models (LLMs) brings emergent abilities to various complex tasks requiring reasoning, such as arithmetic and commonsense reasoning. It is known that the effective design of task-specific prompts is critical for LLMs' ability to produce high-quality answers. In particular, an effective approach for complex question-and-answer tasks is example-based prompting with chain-of-thought (CoT) reasoning, which significantly improves the performance of LLMs. However, current CoT methods rely on a fixed set of human-annotated exemplars, which are not necessarily the most effective examples for different tasks. This paper proposes a new method, Active-Prompt, to adapt LLMs to different tasks with task-specific example prompts (annotated with human-designed CoT reasoning). For this purpose, we propose a solution to the key problem of determining which questions are the most important and helpful ones to annotate from a pool of task-specific queries. By borrowing ideas from the related problem of uncertainty-based active learning, we introduce several metrics to characterize the uncertainty so as to select the most uncertain questions for annotation. Experimental results demonstrate the superiority of our proposed method, achieving state-of-the-art on eight complex reasoning tasks. Further analyses of different uncertainty metrics, pool sizes, zero-shot learning, and accuracy-uncertainty relationship demonstrate the effectiveness of our method. Our code will be available at https://github.com/shizhediao/active-prompt.
Read more7/23/2024
🖼️
0
Unveiling the Statistical Foundations of Chain-of-Thought Prompting Methods
Xinyang Hu, Fengzhuo Zhang, Siyu Chen, Zhuoran Yang
Chain-of-Thought (CoT) prompting and its variants have gained popularity as effective methods for solving multi-step reasoning problems using pretrained large language models (LLMs). In this work, we analyze CoT prompting from a statistical estimation perspective, providing a comprehensive characterization of its sample complexity. To this end, we introduce a multi-step latent variable model that encapsulates the reasoning process, where the latent variable encodes the task information. Under this framework, we demonstrate that when the pretraining dataset is sufficiently large, the estimator formed by CoT prompting is equivalent to a Bayesian estimator. This estimator effectively solves the multi-step reasoning problem by aggregating a posterior distribution inferred from the demonstration examples in the prompt. Moreover, we prove that the statistical error of the CoT estimator can be decomposed into two main components: (i) a prompting error, which arises from inferring the true task using CoT prompts, and (ii) the statistical error of the pretrained LLM. We establish that, under appropriate assumptions, the prompting error decays exponentially to zero as the number of demonstrations increases. Additionally, we explicitly characterize the approximation and generalization errors of the pretrained LLM. Notably, we construct a transformer model that approximates the target distribution of the multi-step reasoning problem with an error that decreases exponentially in the number of transformer blocks. Our analysis extends to other variants of CoT, including Self-Consistent CoT, Tree-of-Thought, and Selection-Inference, offering a broad perspective on the efficacy of these methods. We also provide numerical experiments to validate the theoretical findings.
Read more8/29/2024
🌀
0
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Aaron Mueller, Albert Webson, Jackson Petty, Tal Linzen
In-context learning (ICL) is now a common method for teaching large language models (LLMs) new tasks: given labeled examples in the input context, the LLM learns to perform the task without weight updates. Do models guided via ICL infer the underlying structure of the task defined by the context, or do they rely on superficial heuristics that only generalize to identically distributed examples? We address this question using transformations tasks and an NLI task that assess sensitivity to syntax - a requirement for robust language understanding. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs. The variance is explained more by the composition of the pre-training corpus and supervision methods than by model size; in particular, models pre-trained on code generalize better, and benefit more from chain-of-thought prompting.
Read more4/11/2024