Latent Anomaly Detection Through Density Matrices

0
Sign in to get full access
Overview
- The paper introduces a novel approach called "Latent Anomaly Detection Through Density Matrices" for detecting anomalies in data.
- The method leverages density matrices - mathematical representations of probability distributions - to identify unusual patterns in the latent space of a neural network.
- This allows for more accurate anomaly detection compared to traditional techniques that operate directly on the input data.
Plain English Explanation
In this research, the authors developed a new way to find unusual or unexpected data points within a dataset. Their approach is based on analyzing the "latent space" of a neural network - a hidden layer that captures important features of the data.
The key insight is that by looking at the density matrix, which represents the probability distribution in this latent space, the researchers can identify data points that don't fit the normal pattern. This is more powerful than just looking at the raw input data, because the latent space has extracted the most relevant information.
Intuitively, you can think of the latent space as a compressed representation of the data, where unusual points stand out more clearly. The density matrix then gives a way to quantify and measure this "unusualness" in a principled statistical way.
Technical Explanation
The paper introduces a new technique called "Latent Anomaly Detection Through Density Matrices" for identifying anomalies in data. The core idea is to leverage the latent representations learned by a neural network to detect unusual patterns, rather than operating directly on the raw input data.
Specifically, the authors propose using the density matrix - a mathematical representation of the probability distribution in the latent space - to quantify how anomalous each data point is. This allows the method to capture higher-order statistical properties of the data that are lost when only considering the input features.
The density matrix is computed by projecting the latent representations onto a set of random feature vectors, allowing for efficient estimation even in high-dimensional spaces. The authors then define an anomaly score based on the difference between the density matrix of a test point and the reference density matrix learned from normal training data.
Through experiments on various anomaly detection benchmarks, the authors demonstrate that their latent density matrix approach outperforms traditional techniques that operate directly on the input data. They attribute this improved performance to the ability of the neural network to learn relevant latent representations, and the density matrix's effectiveness at capturing statistical anomalies in this learned feature space.
Critical Analysis
The paper presents a compelling approach for anomaly detection that leverages the representational power of neural networks. By shifting the focus to the latent space, the method can potentially identify more nuanced and complex anomalies that may be obscured in the original input features.
However, the paper does not explore the limitations or failure modes of the proposed technique. For example, the performance may degrade if the neural network fails to learn appropriate latent representations, or if the anomalies manifest in ways that are not well-captured by the density matrix formulation.
Additionally, the paper does not discuss the computational complexity and scalability of the approach, which could be an important practical consideration for real-world applications. Further research is needed to understand the robustness and limitations of latent anomaly detection through density matrices.
Conclusion
The "Latent Anomaly Detection Through Density Matrices" paper presents a novel approach for identifying unusual patterns in data by leveraging the latent representations learned by a neural network. By modeling the probability distribution in this latent space using density matrices, the method can capture higher-order statistical properties that are often missed by traditional anomaly detection techniques.
The experimental results demonstrate the effectiveness of this approach, suggesting that it could be a valuable tool for a wide range of anomaly detection tasks. However, further research is needed to fully understand the strengths, limitations, and practical considerations of this technique. As the field of anomaly detection continues to evolve, approaches like the one proposed in this paper may play an increasingly important role in uncovering hidden patterns and outliers in complex, high-dimensional datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent Anomaly Detection Through Density Matrices
Joseph Gallego-Mejia, Oscar Bustos-Brinez, Fabio A. Gonz'alez
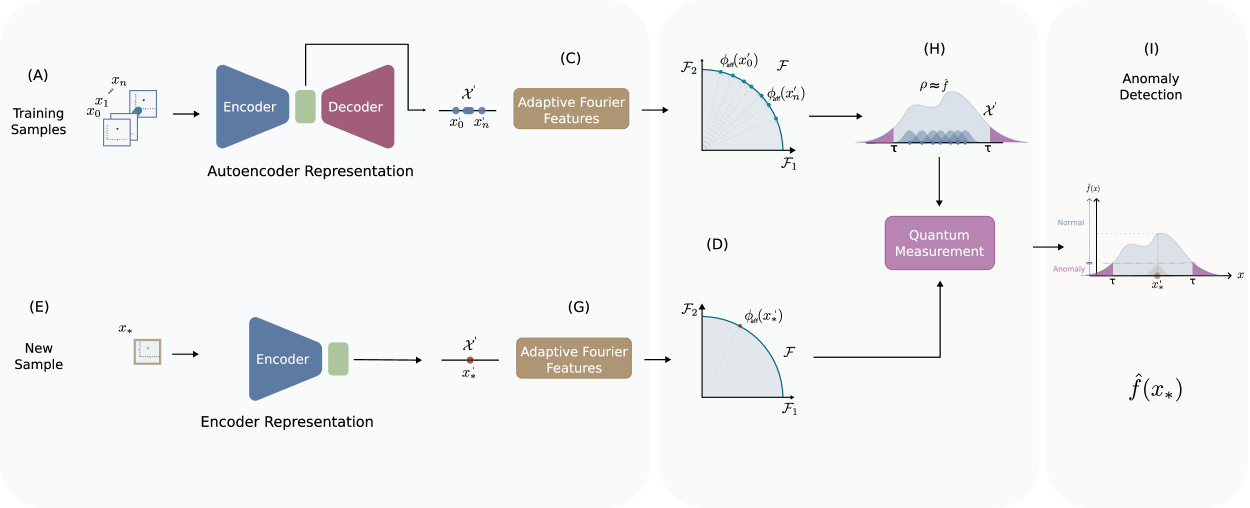
This paper introduces a novel anomaly detection framework that combines the robust statistical principles of density-estimation-based anomaly detection methods with the representation-learning capabilities of deep learning models. The method originated from this framework is presented in two different versions: a shallow approach employing a density-estimation model based on adaptive Fourier features and density matrices, and a deep approach that integrates an autoencoder to learn a low-dimensional representation of the data. By estimating the density of new samples, both methods are able to find normality scores. The methods can be seamlessly integrated into an end-to-end architecture and optimized using gradient-based optimization techniques. To evaluate their performance, extensive experiments were conducted on various benchmark datasets. The results demonstrate that both versions of the method can achieve comparable or superior performance when compared to other state-of-the-art methods. Notably, the shallow approach performs better on datasets with fewer dimensions, while the autoencoder-based approach shows improved performance on datasets with higher dimensions.
Read more8/15/2024
🏷️
0
Learning with Density Matrices and Random Features
Fabio A. Gonz'alez, Alejandro Gallego, Santiago Toledo-Cort'es, Vladimir Vargas-Calder'on
A density matrix describes the statistical state of a quantum system. It is a powerful formalism to represent both the quantum and classical uncertainty of quantum systems and to express different statistical operations such as measurement, system combination and expectations as linear algebra operations. This paper explores how density matrices can be used as a building block for machine learning models exploiting their ability to straightforwardly combine linear algebra and probability. One of the main results of the paper is to show that density matrices coupled with random Fourier features could approximate arbitrary probability distributions over $mathbb{R}^n$. Based on this finding the paper builds different models for density estimation, classification and regression. These models are differentiable, so it is possible to integrate them with other differentiable components, such as deep learning architectures and to learn their parameters using gradient-based optimization. In addition, the paper presents optimization-less training strategies based on estimation and model averaging. The models are evaluated in benchmark tasks and the results are reported and discussed.
Read more5/1/2024
🔮
0
Anomalies, Representations, and Self-Supervision
Barry M. Dillon, Luigi Favaro, Friedrich Feiden, Tanmoy Modak, Tilman Plehn
We develop a self-supervised method for density-based anomaly detection using contrastive learning, and test it using event-level anomaly data from CMS ADC2021. The AnomalyCLR technique is data-driven and uses augmentations of the background data to mimic non-Standard-Model events in a model-agnostic way. It uses a permutation-invariant Transformer Encoder architecture to map the objects measured in a collider event to the representation space, where the data augmentations define a representation space which is sensitive to potential anomalous features. An AutoEncoder trained on background representations then computes anomaly scores for a variety of signals in the representation space. With AnomalyCLR we find significant improvements on performance metrics for all signals when compared to the raw data baseline.
Read more8/9/2024
❗
0
Anomaly Detection with Variance Stabilized Density Estimation
Amit Rozner, Barak Battash, Henry Li, Lior Wolf, Ofir Lindenbaum
We propose a modified density estimation problem that is highly effective for detecting anomalies in tabular data. Our approach assumes that the density function is relatively stable (with lower variance) around normal samples. We have verified this hypothesis empirically using a wide range of real-world data. Then, we present a variance-stabilized density estimation problem for maximizing the likelihood of the observed samples while minimizing the variance of the density around normal samples. To obtain a reliable anomaly detector, we introduce a spectral ensemble of autoregressive models for learning the variance-stabilized distribution. We have conducted an extensive benchmark with 52 datasets, demonstrating that our method leads to state-of-the-art results while alleviating the need for data-specific hyperparameter tuning. Finally, we have used an ablation study to demonstrate the importance of each of the proposed components, followed by a stability analysis evaluating the robustness of our model.
Read more5/9/2024