Anomalies, Representations, and Self-Supervision

0
🔮
Sign in to get full access
Overview
- The researchers develop a self-supervised method called AnomalyCLR for detecting anomalies in particle physics data using contrastive learning.
- They test the method on event-level anomaly data from the CMS ADC2021 dataset.
- AnomalyCLR uses data augmentations of the background data to mimic non-Standard-Model events in a model-agnostic way.
- It employs a permutation-invariant Transformer Encoder architecture to map particle physics events to a representation space.
- An AutoEncoder trained on background representations then computes anomaly scores for various signals in the representation space.
- The researchers find significant performance improvements over the raw data baseline for all signals tested.
Plain English Explanation
The researchers have created a new technique called AnomalyCLR to detect anomalies, or unusual events, in particle physics data. Particle physics experiments like the Large Hadron Collider produce massive amounts of data, and scientists are always on the lookout for events that don't fit the Standard Model of particle physics, as these could lead to new discoveries.
AnomalyCLR works by taking the "normal" particle physics events and creating slightly modified versions of them. These modified versions are meant to mimic the kind of unusual, non-Standard-Model events that the researchers are trying to detect. They then use a neural network architecture called a Transformer Encoder to represent each event as a point in a high-dimensional space.
The key insight is that the normal events and the modified events should end up in different regions of this representation space. An AutoEncoder neural network is then trained to compress the normal events into a compact representation. Events that don't fit well into this compressed representation are flagged as potential anomalies.
The researchers tested AnomalyCLR on data from the CMS experiment at the Large Hadron Collider and found that it significantly outperformed the baseline method of just looking at the raw data.
Technical Explanation
The researchers develop a self-supervised method for density-based anomaly detection using contrastive learning. Their AnomalyCLR technique is data-driven and uses data augmentations of the background data to mimic non-Standard-Model events in a model-agnostic way.
The architecture uses a permutation-invariant Transformer Encoder to map the objects measured in a collider event to a representation space, where the data augmentations define a representation space that is sensitive to potential anomalous features. An AutoEncoder trained on background representations then computes anomaly scores for a variety of signals in the representation space.
The researchers find significant improvements on performance metrics for all signals tested when compared to the raw data baseline.
Critical Analysis
The paper provides a thorough evaluation of the AnomalyCLR method on the CMS ADC2021 dataset, including comparisons to various baselines. However, the authors acknowledge that the method relies on the ability to effectively model the background data through data augmentations, which may be challenging for complex physics processes.
Additionally, the paper does not address the interpretability of the anomaly scores computed by the AutoEncoder. In many applications, it is important to understand the reasons behind anomaly detection, which the current approach may not provide.
Further research could explore ways to enhance the interpretability of the anomaly detection, potentially by incorporating domain knowledge into the model architecture or the data augmentation process. Extending the evaluation to a broader range of anomaly detection tasks in particle physics would also help to validate the generalizability of the AnomalyCLR approach.
Conclusion
The researchers have developed a promising self-supervised anomaly detection technique called AnomalyCLR that leverages contrastive learning and data augmentation to achieve significant performance improvements over a raw data baseline on particle physics anomaly detection tasks. While the method shows strong potential, further research is needed to address interpretability and generalizability concerns. Overall, the work represents an important step forward in applying advanced machine learning techniques to the challenging problem of anomaly detection in complex physics datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Anomalies, Representations, and Self-Supervision
Barry M. Dillon, Luigi Favaro, Friedrich Feiden, Tanmoy Modak, Tilman Plehn
We develop a self-supervised method for density-based anomaly detection using contrastive learning, and test it using event-level anomaly data from CMS ADC2021. The AnomalyCLR technique is data-driven and uses augmentations of the background data to mimic non-Standard-Model events in a model-agnostic way. It uses a permutation-invariant Transformer Encoder architecture to map the objects measured in a collider event to the representation space, where the data augmentations define a representation space which is sensitive to potential anomalous features. An AutoEncoder trained on background representations then computes anomaly scores for a variety of signals in the representation space. With AnomalyCLR we find significant improvements on performance metrics for all signals when compared to the raw data baseline.
Read more8/9/2024
❗
0
CARLA: Self-supervised Contrastive Representation Learning for Time Series Anomaly Detection
Zahra Zamanzadeh Darban, Geoffrey I. Webb, Shirui Pan, Charu C. Aggarwal, Mahsa Salehi
One main challenge in time series anomaly detection (TSAD) is the lack of labelled data in many real-life scenarios. Most of the existing anomaly detection methods focus on learning the normal behaviour of unlabelled time series in an unsupervised manner. The normal boundary is often defined tightly, resulting in slight deviations being classified as anomalies, consequently leading to a high false positive rate and a limited ability to generalise normal patterns. To address this, we introduce a novel end-to-end self-supervised ContrAstive Representation Learning approach for time series Anomaly detection (CARLA). While existing contrastive learning methods assume that augmented time series windows are positive samples and temporally distant windows are negative samples, we argue that these assumptions are limited as augmentation of time series can transform them to negative samples, and a temporally distant window can represent a positive sample. Our contrastive approach leverages existing generic knowledge about time series anomalies and injects various types of anomalies as negative samples. Therefore, CARLA not only learns normal behaviour but also learns deviations indicating anomalies. It creates similar representations for temporally closed windows and distinct ones for anomalies. Additionally, it leverages the information about representations' neighbours through a self-supervised approach to classify windows based on their nearest/furthest neighbours to further enhance the performance of anomaly detection. In extensive tests on seven major real-world time series anomaly detection datasets, CARLA shows superior performance over state-of-the-art self-supervised and unsupervised TSAD methods. Our research shows the potential of contrastive representation learning to advance time series anomaly detection.
Read more4/9/2024
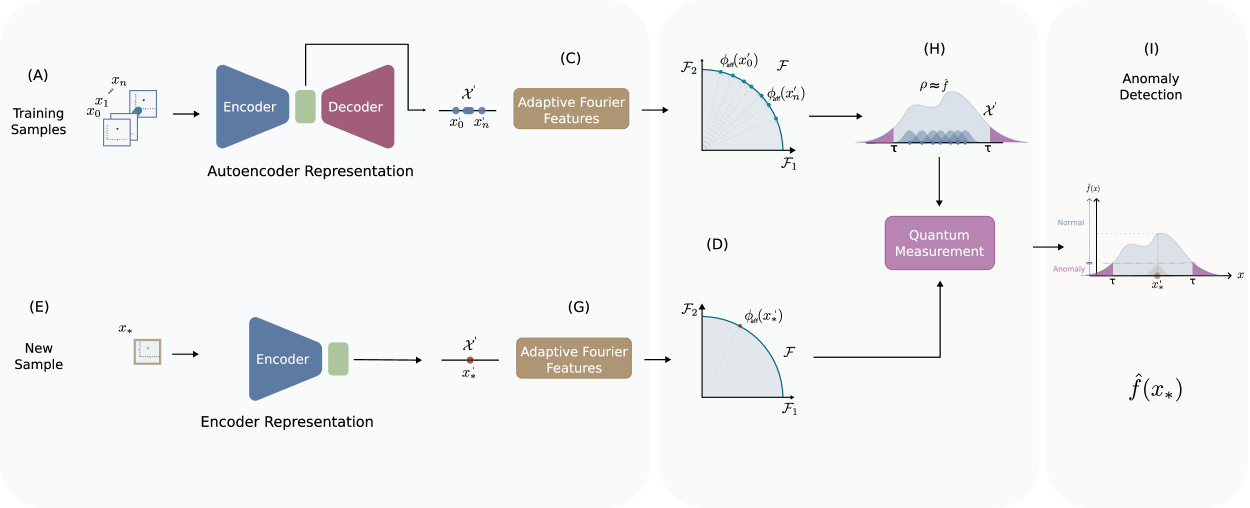
0
Latent Anomaly Detection Through Density Matrices
Joseph Gallego-Mejia, Oscar Bustos-Brinez, Fabio A. Gonz'alez
This paper introduces a novel anomaly detection framework that combines the robust statistical principles of density-estimation-based anomaly detection methods with the representation-learning capabilities of deep learning models. The method originated from this framework is presented in two different versions: a shallow approach employing a density-estimation model based on adaptive Fourier features and density matrices, and a deep approach that integrates an autoencoder to learn a low-dimensional representation of the data. By estimating the density of new samples, both methods are able to find normality scores. The methods can be seamlessly integrated into an end-to-end architecture and optimized using gradient-based optimization techniques. To evaluate their performance, extensive experiments were conducted on various benchmark datasets. The results demonstrate that both versions of the method can achieve comparable or superior performance when compared to other state-of-the-art methods. Notably, the shallow approach performs better on datasets with fewer dimensions, while the autoencoder-based approach shows improved performance on datasets with higher dimensions.
Read more8/15/2024

0
Anomaly Detection by Context Contrasting
Alain Ryser, Thomas M. Sutter, Alexander Marx, Julia E. Vogt
Anomaly Detection focuses on identifying samples that deviate from the norm. When working with high-dimensional data such as images, a crucial requirement for detecting anomalous patterns is learning lower-dimensional representations that capture normal concepts seen during training. Recent advances in self-supervised learning have shown great promise in this regard. However, many of the most successful self-supervised anomaly detection methods assume prior knowledge about the structure of anomalies and leverage synthetic anomalies during training. Yet, in many real-world applications, we do not know what to expect from unseen data, and we can solely leverage knowledge about normal data. In this work, we propose Con2, which addresses this problem by setting normal training data into distinct contexts while preserving its normal properties, letting us observe the data from different perspectives. Unseen normal data consequently adheres to learned context representations while anomalies fail to do so, letting us detect them without any knowledge about anomalies during training. Our experiments demonstrate that our approach achieves state-of-the-art performance on various benchmarks while exhibiting superior performance in a more realistic healthcare setting, where knowledge about potential anomalies is often scarce.
Read more5/30/2024