Latent mixed-effect models for high-dimensional longitudinal data

0

Sign in to get full access
Overview
- Latent mixed-effect models for high-dimensional longitudinal data
- Addresses modeling challenges with complex, high-dimensional longitudinal data
- Proposes a new statistical framework that can capture nonlinear, heterogeneous relationships in the data
Plain English Explanation
Over time, people or objects can generate a lot of complex data points that change in intricate ways. This type of longitudinal data can be difficult to model accurately. The authors present a new statistical approach called "latent mixed-effect models" that can handle these challenges.
The key idea is to use "latent variables" - unobserved factors that influence the data in complex, nonlinear ways. These latent variables are combined with traditional "fixed" and "random" effects to capture both population-level trends and individual-level variations. This allows the model to flexibly adapt to the heterogeneous, high-dimensional nature of the longitudinal data.
The authors demonstrate the effectiveness of their approach on several real-world datasets, showing how it can outperform existing methods. This suggests their latent mixed-effect models could be a valuable tool for researchers and analysts working with complex longitudinal data in fields like healthcare, finance, and beyond.
Technical Explanation
The paper presents a new class of latent mixed-effect models for analyzing high-dimensional longitudinal data. Traditional mixed-effect models struggle to capture the complex, nonlinear relationships present in such data. To address this, the authors introduce latent variables that can flexibly model the underlying data-generating process.
Specifically, the model consists of three key components:
- Fixed effects: Represent population-level trends and the influence of observed covariates.
- Random effects: Capture individual-level variations and allow for subject-specific predictions.
- Latent effects: Unobserved factors that introduce additional nonlinear, heterogeneous structure into the model.
By combining these components, the latent mixed-effect model can adaptively learn the complex patterns in high-dimensional longitudinal data. The authors develop efficient algorithms for model fitting and inference, allowing the approach to scale to large datasets.
Through extensive experiments on real-world datasets, the authors demonstrate the superior performance of their latent mixed-effect models compared to existing alternatives. The models are able to uncover meaningful insights and generate accurate predictions, highlighting their practical utility for researchers and practitioners.
Critical Analysis
The authors acknowledge several limitations and potential avenues for future research. First, the model assumes the latent variables follow a Gaussian distribution, which may not always be appropriate. Exploring non-Gaussian latent structures could further enhance the model's flexibility.
Additionally, the current framework focuses on continuous longitudinal outcomes. Extending the approach to handle mixed data types, such as categorical or time-to-event data, would broaden the applicability of the method.
Finally, the interpretability of the learned latent variables is an important consideration. Developing techniques to better understand the underlying factors discovered by the model could aid in domain-specific knowledge discovery and decision-making.
Overall, the latent mixed-effect model represents a promising step forward in the analysis of complex longitudinal data. Future research addressing the noted limitations could further strengthen the capabilities of this statistical framework.
Conclusion
This paper introduces a novel class of latent mixed-effect models that can effectively analyze high-dimensional longitudinal data. By incorporating latent variables alongside traditional fixed and random effects, the approach is able to capture the intricate, nonlinear patterns present in such data.
The authors demonstrate the practical utility of their method through extensive real-world experiments, showing how it can outperform existing techniques. This suggests the latent mixed-effect model could be a valuable tool for researchers and practitioners working with complex, time-varying data in fields such as healthcare, finance, and beyond.
While the current framework has some limitations, the authors identify promising directions for future research. Continued advancements in this area could lead to even more powerful statistical tools for understanding and making predictions from high-dimensional longitudinal data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Latent mixed-effect models for high-dimensional longitudinal data
Priscilla Ong, Manuel Hau{ss}mann, Otto Lonnroth, Harri Lahdesmaki
Modelling longitudinal data is an important yet challenging task. These datasets can be high-dimensional, contain non-linear effects and time-varying covariates. Gaussian process (GP) prior-based variational autoencoders (VAEs) have emerged as a promising approach due to their ability to model time-series data. However, they are costly to train and struggle to fully exploit the rich covariates characteristic of longitudinal data, making them difficult for practitioners to use effectively. In this work, we leverage linear mixed models (LMMs) and amortized variational inference to provide conditional priors for VAEs, and propose LMM-VAE, a scalable, interpretable and identifiable model. We highlight theoretical connections between it and GP-based techniques, providing a unified framework for this class of methods. Our proposal performs competitively compared to existing approaches across simulated and real-world datasets.
Read more9/18/2024
📈
0
Latent variable model for high-dimensional point process with structured missingness
Maksim Sinelnikov, Manuel Haussmann, Harri Lahdesmaki
Longitudinal data are important in numerous fields, such as healthcare, sociology and seismology, but real-world datasets present notable challenges for practitioners because they can be high-dimensional, contain structured missingness patterns, and measurement time points can be governed by an unknown stochastic process. While various solutions have been suggested, the majority of them have been designed to account for only one of these challenges. In this work, we propose a flexible and efficient latent-variable model that is capable of addressing all these limitations. Our approach utilizes Gaussian processes to capture temporal correlations between samples and their associated missingness masks as well as to model the underlying point process. We construct our model as a variational autoencoder together with deep neural network parameterised encoder and decoder models, and develop a scalable amortised variational inference approach for efficient model training. We demonstrate competitive performance using both simulated and real datasets.
Read more7/1/2024
📈
0
Scalable mixed-domain Gaussian process modeling and model reduction for longitudinal data
Juho Timonen, Harri Lahdesmaki
Gaussian process (GP) models that combine both categorical and continuous input variables have found use in longitudinal data analysis of and computer experiments. However, standard inference for these models has the typical cubic scaling, and common scalable approximation schemes for GPs cannot be applied since the covariance function is non-continuous. In this work, we derive a basis function approximation scheme for mixed-domain covariance functions, which scales linearly with respect to the number of observations and total number of basis functions. The proposed approach is naturally applicable to also Bayesian GP regression with discrete observation models. We demonstrate the scalability of the approach and compare model reduction techniques for additive GP models in a longitudinal data context. We confirm that we can approximate the exact GP model accurately in a fraction of the runtime compared to fitting the corresponding exact model. In addition, we demonstrate a scalable model reduction workflow for obtaining smaller and more interpretable models when dealing with a large number of candidate predictors.
Read more9/9/2024
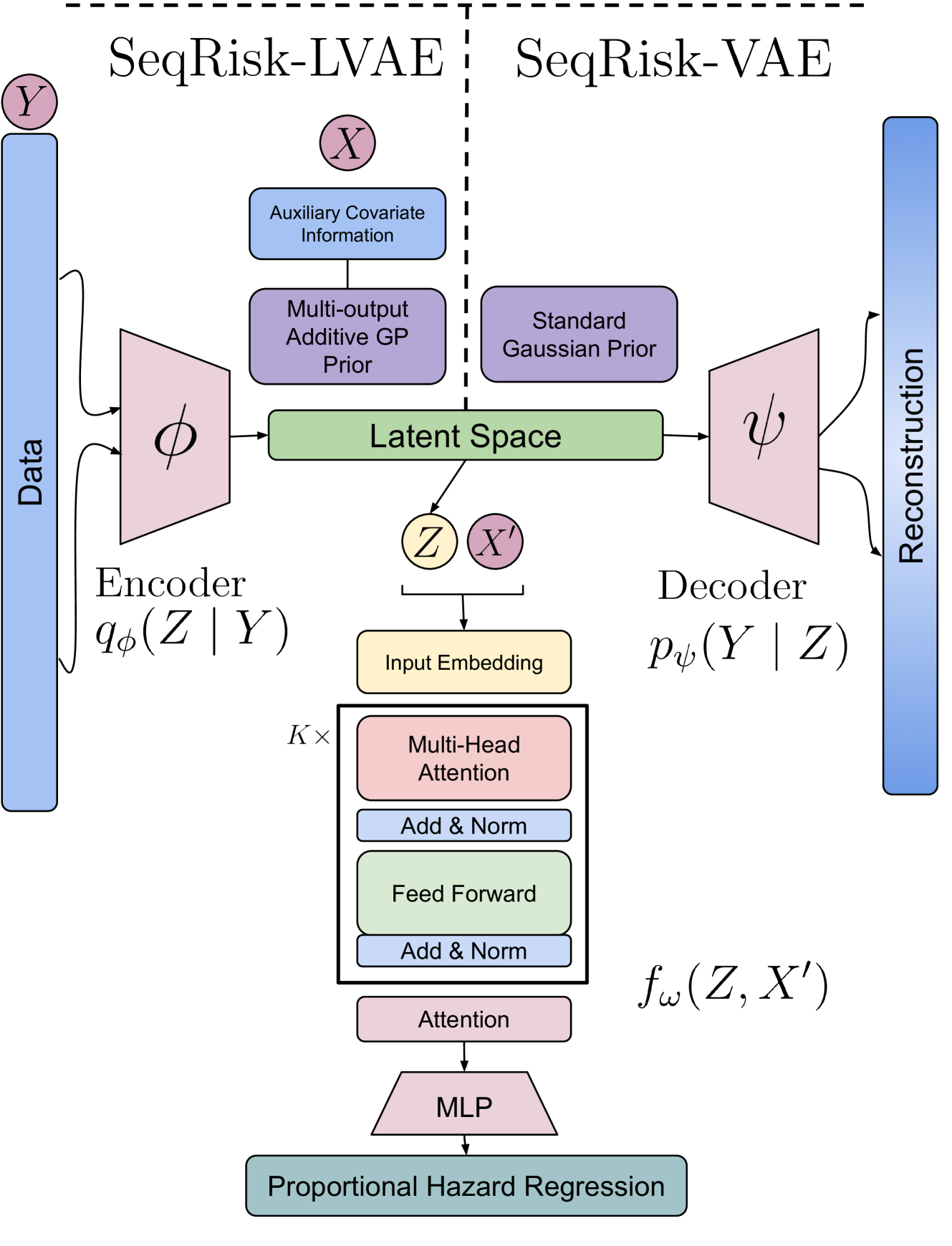
0
SeqRisk: Transformer-augmented latent variable model for improved survival prediction with longitudinal data
Mine Ou{g}retir, Miika Koskinen, Juha Sinisalo, Risto Renkonen, Harri Lahdesmaki
In healthcare, risk assessment of different patient outcomes has for long time been based on survival analysis, i.e. modeling time-to-event associations. However, conventional approaches rely on data from a single time-point, making them suboptimal for fully leveraging longitudinal patient history and capturing temporal regularities. Focusing on clinical real-world data and acknowledging its challenges, we utilize latent variable models to effectively handle irregular, noisy, and sparsely observed longitudinal data. We propose SeqRisk, a method that combines variational autoencoder (VAE) or longitudinal VAE (LVAE) with a transformer encoder and Cox proportional hazards module for risk prediction. SeqRisk captures long-range interactions, improves patient trajectory representations, enhances predictive accuracy and generalizability, as well as provides partial explainability for sample population characteristics in attempts to identify high-risk patients. We demonstrate that SeqRisk performs competitively compared to existing approaches on both simulated and real-world datasets.
Read more9/20/2024