Preventing Model Collapse in Gaussian Process Latent Variable Models
2404.01697
0
0
Abstract
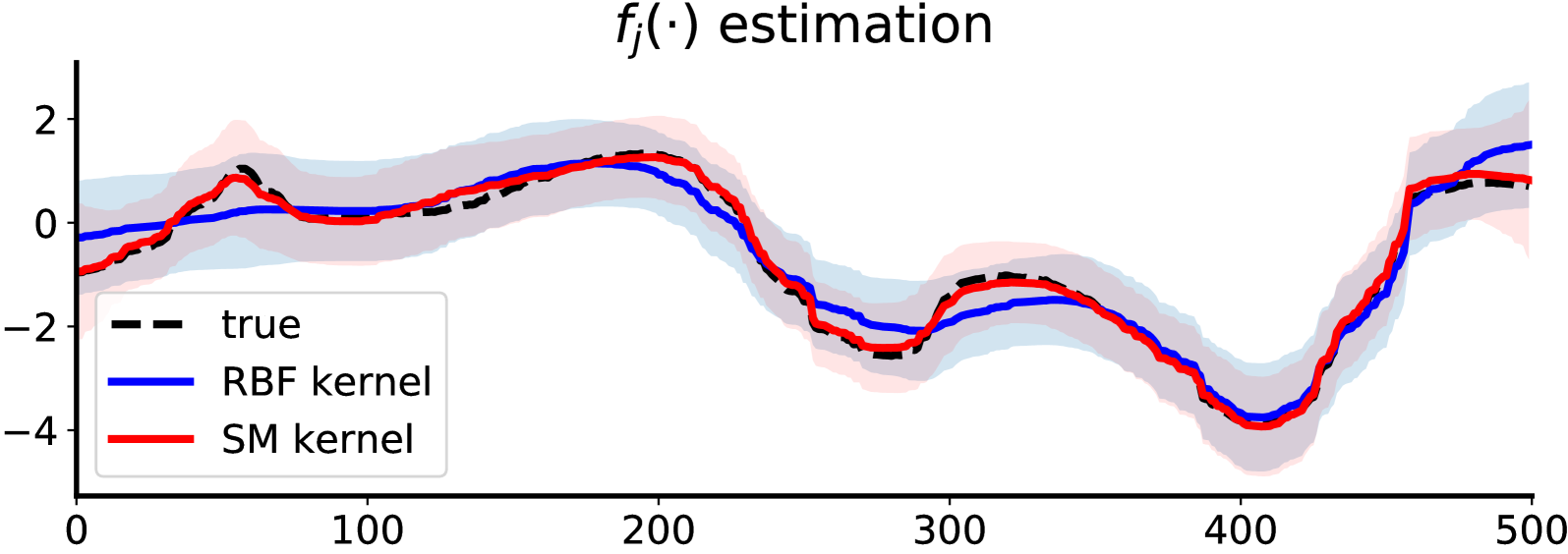
Gaussian process latent variable models (GPLVMs) are a versatile family of unsupervised learning models commonly used for dimensionality reduction. However, common challenges in modeling data with GPLVMs include inadequate kernel flexibility and improper selection of the projection noise, leading to a type of model collapse characterized by vague latent representations that do not reflect the underlying data structure. This paper addresses these issues by, first, theoretically examining the impact of projection variance on model collapse through the lens of a linear GPLVM. Second, we tackle model collapse due to inadequate kernel flexibility by integrating the spectral mixture (SM) kernel and a differentiable random Fourier feature (RFF) kernel approximation, which ensures computational scalability and efficiency through off-the-shelf automatic differentiation tools for learning the kernel hyperparameters, projection variance, and latent representations within the variational inference framework. The proposed GPLVM, named advisedRFLVM, is evaluated across diverse datasets and consistently outperforms various salient competing models, including state-of-the-art variational autoencoders (VAEs) and other GPLVM variants, in terms of informative latent representations and missing data imputation.
Create account to get full access
Overview
- This paper explores ways to prevent "model collapse" in Gaussian Process Latent Variable Models (GP-LVMs), a type of machine learning model.
- Model collapse occurs when the learned latent variables (hidden representations) become uninformative, limiting the model's ability to capture complex relationships in the data.
- The authors propose several techniques to mitigate model collapse and improve the performance of GP-LVMs.
Plain English Explanation
Gaussian Process Latent Variable Models are a powerful machine learning tool that can uncover hidden patterns in data. They work by finding a low-dimensional representation (latent variables) that captures the key features of the input data.
However, these models can sometimes suffer from "model collapse", where the latent variables become too simple and fail to represent the full complexity of the data. This is like trying to describe a detailed painting using only a few colors - you lose a lot of the nuance and richness.
The researchers in this paper tested different methods to prevent this model collapse and keep the latent variables informative. One approach was to add a penalty term that encourages the latent variables to be more spread out and diverse. Another was to initialize the model in a clever way to avoid getting stuck in a poor solution.
By using these techniques, the researchers were able to train GP-LVMs that could better capture the underlying structure of the data, leading to improved performance on various machine learning tasks. This is an important step forward, as these models have many potential applications in fields like computer vision, robotics, and bioinformatics.
Technical Explanation
The paper focuses on addressing the problem of "model collapse" in Gaussian Process Latent Variable Models (GP-LVMs), a class of probabilistic models that learn a low-dimensional latent representation of high-dimensional observed data.
The authors identify two key causes of model collapse in GP-LVMs: (1) the tendency of the latent variables to become degenerate (i.e., collapse to a single point) during training, and (2) the difficulty in learning meaningful latent representations when the data lies on a nonlinear manifold.
To mitigate these issues, the paper proposes several techniques:
-
Manifold Regularization: The authors introduce a regularization term that encourages the latent variables to lie on a manifold, preventing them from collapsing to a single point.
-
Initialization Strategies: The paper explores different initialization schemes for the latent variables, including a novel approach that aligns the initial latent variables with the principal components of the data.
-
Hybrid Models: The authors combine GP-LVMs with other latent variable models, such as Variational Autoencoders, to leverage the strengths of multiple approaches and further improve the learned representations.
The proposed methods are evaluated on several benchmark datasets, demonstrating significant improvements in the quality of the learned latent representations and the downstream task performance, compared to standard GP-LVM training.
Critical Analysis
The paper provides a thorough analysis of the model collapse problem in GP-LVMs and presents effective techniques to address it. The proposed solutions are well-grounded in theory and show promising empirical results.
One potential limitation is that the methods may not generalize equally well to all types of data and problem settings. The authors acknowledge that the performance of the techniques can depend on factors such as the complexity of the data manifold and the choice of hyperparameters.
Additionally, while the paper focuses on GP-LVMs, the insights and approaches discussed could potentially be extended to other latent variable models that suffer from similar issues of representation collapse or degeneracy.
Further research could explore the interactions between the proposed methods, as well as investigate their performance on a wider range of applications and datasets. Analyzing the robustness of the techniques to different data distributions and noise levels would also be valuable.
Conclusion
This paper presents an important contribution to the field of latent variable modeling by addressing the critical problem of model collapse in Gaussian Process Latent Variable Models. The proposed techniques, including manifold regularization and novel initialization strategies, effectively mitigate this issue and lead to significant improvements in the quality of the learned latent representations.
By overcoming the limitations of standard GP-LVM training, the methods described in this paper can unlock the full potential of these models in a wide range of applications, from computer vision and robotics to bioinformatics and beyond. The insights gained from this work could also inspire further advancements in latent variable modeling and representation learning more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scalable Amortized GPLVMs for Single Cell Transcriptomics Data
Sarah Zhao, Aditya Ravuri, Vidhi Lalchand, Neil D. Lawrence
0
0
Dimensionality reduction is crucial for analyzing large-scale single-cell RNA-seq data. Gaussian Process Latent Variable Models (GPLVMs) offer an interpretable dimensionality reduction method, but current scalable models lack effectiveness in clustering cell types. We introduce an improved model, the amortized stochastic variational Bayesian GPLVM (BGPLVM), tailored for single-cell RNA-seq with specialized encoder, kernel, and likelihood designs. This model matches the performance of the leading single-cell variational inference (scVI) approach on synthetic and real-world COVID datasets and effectively incorporates cell-cycle and batch information to reveal more interpretable latent structures as we demonstrate on an innate immunity dataset.
5/8/2024
📈
Latent variable model for high-dimensional point process with structured missingness
Maksim Sinelnikov, Manuel Haussmann, Harri Lahdesmaki
0
0
Longitudinal data are important in numerous fields, such as healthcare, sociology and seismology, but real-world datasets present notable challenges for practitioners because they can be high-dimensional, contain structured missingness patterns, and measurement time points can be governed by an unknown stochastic process. While various solutions have been suggested, the majority of them have been designed to account for only one of these challenges. In this work, we propose a flexible and efficient latent-variable model that is capable of addressing all these limitations. Our approach utilizes Gaussian processes to capture temporal correlations between samples and their associated missingness masks as well as to model the underlying point process. We construct our model as a variational autoencoder together with deep neural network parameterised encoder and decoder models, and develop a scalable amortised variational inference approach for efficient model training. We demonstrate competitive performance using both simulated and real datasets.
7/1/2024
🤿
Variational Linearized Laplace Approximation for Bayesian Deep Learning
Luis A. Ortega, Sim'on Rodr'iguez Santana, Daniel Hern'andez-Lobato
0
0
The Linearized Laplace Approximation (LLA) has been recently used to perform uncertainty estimation on the predictions of pre-trained deep neural networks (DNNs). However, its widespread application is hindered by significant computational costs, particularly in scenarios with a large number of training points or DNN parameters. Consequently, additional approximations of LLA, such as Kronecker-factored or diagonal approximate GGN matrices, are utilized, potentially compromising the model's performance. To address these challenges, we propose a new method for approximating LLA using a variational sparse Gaussian Process (GP). Our method is based on the dual RKHS formulation of GPs and retains, as the predictive mean, the output of the original DNN. Furthermore, it allows for efficient stochastic optimization, which results in sub-linear training time in the size of the training dataset. Specifically, its training cost is independent of the number of training points. We compare our proposed method against accelerated LLA (ELLA), which relies on the Nystrom approximation, as well as other LLA variants employing the sample-then-optimize principle. Experimental results, both on regression and classification datasets, show that our method outperforms these already existing efficient variants of LLA, both in terms of the quality of the predictive distribution and in terms of total computational time.
5/24/2024
📊
Inferring Manifolds From Noisy Data Using Gaussian Processes
David B Dunson, Nan Wu
0
0
In analyzing complex datasets, it is often of interest to infer lower dimensional structure underlying the higher dimensional observations. As a flexible class of nonlinear structures, it is common to focus on Riemannian manifolds. Most existing manifold learning algorithms replace the original data with lower dimensional coordinates without providing an estimate of the manifold in the observation space or using the manifold to denoise the original data. This article proposes a new methodology for addressing these problems, allowing interpolation of the estimated manifold between fitted data points. The proposed approach is motivated by novel theoretical properties of local covariance matrices constructed from noisy samples on a manifold. Our results enable us to turn a global manifold reconstruction problem into a local regression problem, allowing application of Gaussian processes for probabilistic manifold reconstruction. In addition to theory justifying the algorithm, we provide simulated and real data examples to illustrate the performance.
5/28/2024