Latent Space Score-based Diffusion Model for Probabilistic Multivariate Time Series Imputation

0

Sign in to get full access
Overview
- This paper proposes a latent space score-based diffusion model for probabilistic multivariate time series imputation.
- The model uses a variational graph autoencoder to learn a low-dimensional latent representation of the time series data.
- A score-based diffusion model is then trained in the learned latent space to generate plausible completions for missing data.
- The method outperforms existing imputation techniques on several benchmark datasets.
Plain English Explanation
The paper introduces a new way to fill in missing values in multivariate time series data. Multivariate time series are datasets that track multiple variables over time, like stock prices, sensor readings, or patient health metrics.
The key idea is to first learn a compact representation of the time series in a low-dimensional "latent space." This latent space captures the underlying patterns and relationships in the data.
Then, the researchers train a diffusion model in this latent space. A diffusion model is a type of generative model that can create new, plausible samples of data.
By training the diffusion model in the latent space, the authors can use it to fill in missing values in the original time series data. The model generates likely completions for the missing parts, taking into account the overall structure of the dataset.
The advantage of this approach is that it can handle complex, high-dimensional time series data in a principled, probabilistic way. It outperforms simpler imputation methods on benchmark tests.
Technical Explanation
The paper proposes a novel framework for probabilistic multivariate time series imputation using a latent space score-based diffusion model.
First, the authors use a variational graph autoencoder to learn a low-dimensional latent representation of the time series data. This captures the underlying structure and dynamics of the multivariate time series.
They then train a score-based diffusion model in the learned latent space. This model can generate plausible completions for missing values by learning the probability distribution of the latent representations.
To impute missing data, the model first encodes the partially observed time series into the latent space. It then uses the trained diffusion model to sample likely completions for the missing parts in the latent space. Finally, these latent completions are decoded back to the original data space.
The authors evaluate their approach on several benchmark multivariate time series datasets and show that it outperforms existing imputation methods in terms of reconstruction accuracy and downstream task performance.
Critical Analysis
The paper makes a compelling case for the effectiveness of the proposed latent space diffusion model approach for multivariate time series imputation. However, a few potential limitations or areas for further research are worth noting:
- The method assumes the time series data can be well-represented in a low-dimensional latent space. This may not always be the case, especially for highly complex or heterogeneous datasets.
- The performance of the imputation depends on the quality of the learned latent representation. Improving the variational graph autoencoder architecture or training process could lead to better imputation results.
- The authors only evaluate the method on relatively small to medium-sized datasets. Scaling the approach to handle truly large-scale, high-dimensional time series data may require additional considerations.
- While the probabilistic nature of the diffusion model is a strength, further analysis of the uncertainty quantification and its practical implications for downstream tasks could be valuable.
Overall, this work demonstrates the potential of combining representation learning and generative modeling techniques for principled multivariate time series imputation. Addressing the above points could lead to further advancements in this promising research area.
Conclusion
This paper presents a novel latent space score-based diffusion model for probabilistic multivariate time series imputation. By learning a compact latent representation of the data and training a generative diffusion model in this space, the method can effectively fill in missing values while capturing the underlying structure of the time series.
The approach outperforms existing imputation techniques on several benchmark datasets, showcasing the benefits of the proposed framework. This work contributes to the growing body of research on leveraging diffusion models for handling incomplete data, which could have important applications in fields such as finance, healthcare, and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Latent Space Score-based Diffusion Model for Probabilistic Multivariate Time Series Imputation
Guojun Liang, Najmeh Abiri, Atiye Sadat Hashemi, Jens Lundstrom, Stefan Byttner, Prayag Tiwari
Accurate imputation is essential for the reliability and success of downstream tasks. Recently, diffusion models have attracted great attention in this field. However, these models neglect the latent distribution in a lower-dimensional space derived from the observed data, which limits the generative capacity of the diffusion model. Additionally, dealing with the original missing data without labels becomes particularly problematic. To address these issues, we propose the Latent Space Score-Based Diffusion Model (LSSDM) for probabilistic multivariate time series imputation. Observed values are projected onto low-dimensional latent space and coarse values of the missing data are reconstructed without knowing their ground truth values by this unsupervised learning approach. Finally, the reconstructed values are fed into a conditional diffusion model to obtain the precise imputed values of the time series. In this way, LSSDM not only possesses the power to identify the latent distribution but also seamlessly integrates the diffusion model to obtain the high-fidelity imputed values and assess the uncertainty of the dataset. Experimental results demonstrate that LSSDM achieves superior imputation performance while also providing a better explanation and uncertainty analysis of the imputation mechanism. The website of the code is textit{https://github.com/gorgen2020/LSSDM_imputation}.
Read more9/16/2024

0
TimeLDM: Latent Diffusion Model for Unconditional Time Series Generation
Jian Qian, Bingyu Xie, Biao Wan, Minhao Li, Miao Sun, Patrick Yin Chiang
Time series generation is a crucial research topic in the area of decision-making systems, which can be particularly important in domains like autonomous driving, healthcare, and, notably, robotics. Recent approaches focus on learning in the data space to model time series information. However, the data space often contains limited observations and noisy features. In this paper, we propose TimeLDM, a novel latent diffusion model for high-quality time series generation. TimeLDM is composed of a variational autoencoder that encodes time series into an informative and smoothed latent content and a latent diffusion model operating in the latent space to generate latent information. We evaluate the ability of our method to generate synthetic time series with simulated and real-world datasets and benchmark the performance against existing state-of-the-art methods. Qualitatively and quantitatively, we find that the proposed TimeLDM persistently delivers high-quality generated time series. For example, TimeLDM achieves new state-of-the-art results on the simulated benchmarks and an average improvement of 55% in Discriminative score with all benchmarks. Further studies demonstrate that our method yields more robust outcomes across various lengths of time series data generation. Especially, for the Context-FID score and Discriminative score, TimeLDM realizes significant improvements of 80% and 50%, respectively. The code will be released after publication.
Read more9/16/2024
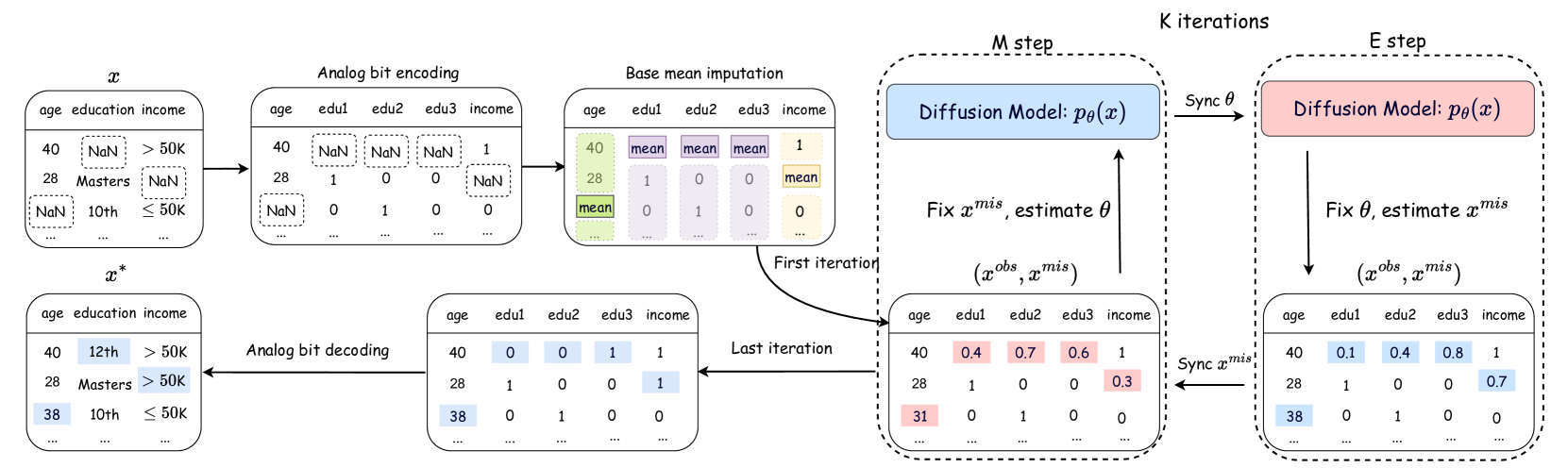
0
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
Read more6/3/2024

0
Self-Supervision Improves Diffusion Models for Tabular Data Imputation
Yixin Liu, Thalaiyasingam Ajanthan, Hisham Husain, Vu Nguyen
The ubiquity of missing data has sparked considerable attention and focus on tabular data imputation methods. Diffusion models, recognized as the cutting-edge technique for data generation, demonstrate significant potential in tabular data imputation tasks. However, in pursuit of diversity, vanilla diffusion models often exhibit sensitivity to initialized noises, which hinders the models from generating stable and accurate imputation results. Additionally, the sparsity inherent in tabular data poses challenges for diffusion models in accurately modeling the data manifold, impacting the robustness of these models for data imputation. To tackle these challenges, this paper introduces an advanced diffusion model named Self-supervised imputation Diffusion Model (SimpDM for brevity), specifically tailored for tabular data imputation tasks. To mitigate sensitivity to noise, we introduce a self-supervised alignment mechanism that aims to regularize the model, ensuring consistent and stable imputation predictions. Furthermore, we introduce a carefully devised state-dependent data augmentation strategy within SimpDM, enhancing the robustness of the diffusion model when dealing with limited data. Extensive experiments demonstrate that SimpDM matches or outperforms state-of-the-art imputation methods across various scenarios.
Read more7/26/2024