Exploring the Impact of a Transformer's Latent Space Geometry on Downstream Task Performance

0

Sign in to get full access
Overview
- This paper explores the relationship between the geometry of a transformer's latent space and its performance on downstream tasks.
- The researchers investigate how the latent space geometry, such as the curvature and dimensionality, can impact a transformer's ability to capture relevant features for specific tasks.
- The findings have implications for understanding the inductive biases and limitations of transformer models, as well as informing their design and training to improve performance on a wide range of applications.
Plain English Explanation
Transformer models are a type of deep learning architecture that have become increasingly popular for a variety of natural language processing tasks. These models work by converting input text into a numerical representation, called a latent space, which can then be used to perform various downstream tasks like sentiment analysis, question answering, or text generation.
The geometry of this latent space - how the different dimensions and curvature of the space relate to each other - can have a significant impact on the model's performance. If the latent space is not well-suited to the specific task at hand, the model may struggle to capture the relevant features and patterns in the data, leading to suboptimal results.
This paper dives into this relationship between latent space geometry and downstream task performance. The researchers explore how factors like the dimensionality, curvature, and other properties of the latent space can influence a transformer's ability to learn and apply knowledge effectively. By understanding these connections, we can gain insights into the fundamental capabilities and limitations of transformer models, and potentially find ways to design and train them more effectively for different applications.
Technical Explanation
The paper begins by noting that the latent space of transformer models can exhibit complex geometric properties, such as high dimensionality and non-Euclidean curvature. The researchers hypothesize that these latent space characteristics may have a significant impact on the model's performance on downstream tasks.
To investigate this, they conduct a series of experiments using various transformer architectures (e.g., BERT, GPT-2) and a range of benchmark tasks (e.g., text classification, question answering). They analyze the geometric properties of the latent space, such as dimensionality, curvature, and the distribution of data points, and correlate these with the model's performance on the downstream tasks.
The results reveal several interesting insights. For example, the researchers find that transformers with higher-dimensional latent spaces tend to perform better on tasks that require capturing complex, abstract relationships in the data. Conversely, transformers with lower-dimensional latent spaces may be better suited for tasks that rely more on capturing simple, local patterns. Additionally, the curvature of the latent space appears to play a role, with models exhibiting non-Euclidean curvature potentially better able to represent certain types of hierarchical or relational structures in the data.
These findings suggest that the geometry of a transformer's latent space is a crucial factor in determining its strengths and limitations for different applications. The paper highlights the importance of considering the inductive biases inherent in the model architecture and exploring ways to tailor the latent space to the specific requirements of a task.
Critical Analysis
The paper presents a compelling and rigorous investigation into the relationship between transformer latent space geometry and downstream task performance. The experimental approach is well-designed, and the analysis of the latent space properties is thorough and insightful.
One potential limitation of the study is that it focuses primarily on relatively simple, well-defined benchmark tasks, rather than more complex, real-world applications. While these benchmarks provide a controlled environment for studying the underlying mechanisms, it would be valuable to also explore the impact of latent space geometry on the performance of transformers in more realistic, messy data scenarios.
Additionally, the paper does not delve into the practical implications of its findings for transformer model design and training. While it highlights the importance of considering latent space geometry, it would be helpful to have more guidance on how to actually optimize this geometry to improve performance on specific tasks.
Overall, this research makes a significant contribution to our understanding of the fundamental capabilities and limitations of transformer models. By shedding light on the role of latent space geometry, it opens up new avenues for improving the robustness and versatility of these powerful language models.
Conclusion
This paper provides valuable insights into the relationship between the geometry of a transformer's latent space and its performance on downstream tasks. The findings suggest that factors such as dimensionality, curvature, and the distribution of data points in the latent space can have a substantial impact on a model's ability to capture relevant features and patterns for specific applications.
These insights have important implications for the design and training of transformer models, as they highlight the need to consider the inductive biases inherent in the model architecture and to tailor the latent space accordingly. By understanding the geometric properties of the latent space and how they interact with the requirements of different tasks, researchers and developers can work towards creating more robust and versatile language models that can excel across a wide range of applications.
Moving forward, it will be important to further explore these connections in the context of more complex, real-world scenarios, and to develop practical guidelines for optimizing latent space geometry to improve transformer performance. This research represents an important step towards a deeper understanding of the fundamental capabilities and limitations of these powerful deep learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring the Impact of a Transformer's Latent Space Geometry on Downstream Task Performance
Anna C. Marbut, John W. Chandler, Travis J. Wheeler
It is generally thought that transformer-based large language models benefit from pre-training by learning generic linguistic knowledge that can be focused on a specific task during fine-tuning. However, we propose that much of the benefit from pre-training may be captured by geometric characteristics of the latent space representations, divorced from any specific linguistic knowledge. In this work we explore the relationship between GLUE benchmarking task performance and a variety of measures applied to the latent space resulting from BERT-type contextual language models. We find that there is a strong linear relationship between a measure of quantized cell density and average GLUE performance and that these measures may be predictive of otherwise surprising GLUE performance for several non-standard BERT-type models from the literature. These results may be suggestive of a strategy for decreasing pre-training requirements, wherein model initialization can be informed by the geometric characteristics of the model's latent space.
Read more6/19/2024
0
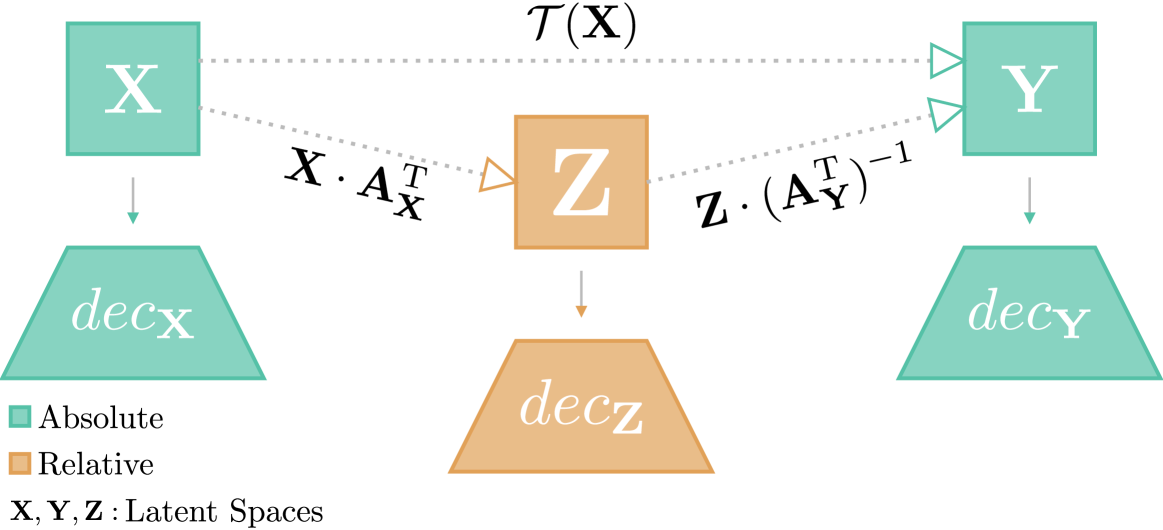
Latent Space Translation via Inverse Relative Projection
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, Emanuele Rodol`a
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Read more6/24/2024

0
Does learning the right latent variables necessarily improve in-context learning?
Sarthak Mittal, Eric Elmoznino, Leo Gagnon, Sangnie Bhardwaj, Dhanya Sridhar, Guillaume Lajoie
Large autoregressive models like Transformers can solve tasks through in-context learning (ICL) without learning new weights, suggesting avenues for efficiently solving new tasks. For many tasks, e.g., linear regression, the data factorizes: examples are independent given a task latent that generates the data, e.g., linear coefficients. While an optimal predictor leverages this factorization by inferring task latents, it is unclear if Transformers implicitly do so or if they instead exploit heuristics and statistical shortcuts enabled by attention layers. Both scenarios have inspired active ongoing work. In this paper, we systematically investigate the effect of explicitly inferring task latents. We minimally modify the Transformer architecture with a bottleneck designed to prevent shortcuts in favor of more structured solutions, and then compare performance against standard Transformers across various ICL tasks. Contrary to intuition and some recent works, we find little discernible difference between the two; biasing towards task-relevant latent variables does not lead to better out-of-distribution performance, in general. Curiously, we find that while the bottleneck effectively learns to extract latent task variables from context, downstream processing struggles to utilize them for robust prediction. Our study highlights the intrinsic limitations of Transformers in achieving structured ICL solutions that generalize, and shows that while inferring the right latents aids interpretability, it is not sufficient to alleviate this problem.
Read more5/30/2024

0
Local Topology Measures of Contextual Language Model Latent Spaces With Applications to Dialogue Term Extraction
Benjamin Matthias Ruppik, Michael Heck, Carel van Niekerk, Renato Vukovic, Hsien-chin Lin, Shutong Feng, Marcus Zibrowius, Milica Gav{s}i'c
A common approach for sequence tagging tasks based on contextual word representations is to train a machine learning classifier directly on these embedding vectors. This approach has two shortcomings. First, such methods consider single input sequences in isolation and are unable to put an individual embedding vector in relation to vectors outside the current local context of use. Second, the high performance of these models relies on fine-tuning the embedding model in conjunction with the classifier, which may not always be feasible due to the size or inaccessibility of the underlying feature-generation model. It is thus desirable, given a collection of embedding vectors of a corpus, i.e., a datastore, to find features of each vector that describe its relation to other, similar vectors in the datastore. With this in mind, we introduce complexity measures of the local topology of the latent space of a contextual language model with respect to a given datastore. The effectiveness of our features is demonstrated through their application to dialogue term extraction. Our work continues a line of research that explores the manifold hypothesis for word embeddings, demonstrating that local structure in the space carved out by word embeddings can be exploited to infer semantic properties.
Read more8/9/2024