Layerwise Proximal Replay: A Proximal Point Method for Online Continual Learning

0
Sign in to get full access
Overview
- Discusses a method called "Layerwise Proximal Replay" for continual learning in neural networks
- Proposes a new optimization technique based on the proximal point method
- Aims to address the challenge of catastrophic forgetting in continual learning
Plain English Explanation
Continual learning is the ability for an artificial intelligence system to learn new tasks or information over time, without forgetting what it has learned previously. This is a challenging problem, as neural networks often suffer from "catastrophic forgetting" - where learning new information causes the system to lose or forget its previous knowledge.
The paper introduces a new method called "Layerwise Proximal Replay" that uses a technique called the "proximal point method" to help neural networks retain their previous knowledge while learning new tasks. The key idea is to update the different layers of the neural network in a way that keeps the network close to its previous state, preventing it from forgetting what it has already learned.
This is done by defining a "loss function" that not only encourages the network to learn the new task, but also penalizes it for straying too far from its previous state. The authors show that this layerwise approach outperforms other continual learning methods on several benchmark tasks, demonstrating its effectiveness at mitigating catastrophic forgetting.
Technical Explanation
The paper proposes a continual learning method called "Layerwise Proximal Replay" (LPR) that uses a proximal point optimization technique to update the different layers of a neural network. The goal is to prevent the network from forgetting its previous knowledge when learning new tasks.
The key idea is to define a loss function that has two terms: one that encourages learning the new task, and another that penalizes the network for deviating too much from its previous state. This "proximal" term keeps the network close to its previous parameters, mitigating catastrophic forgetting.
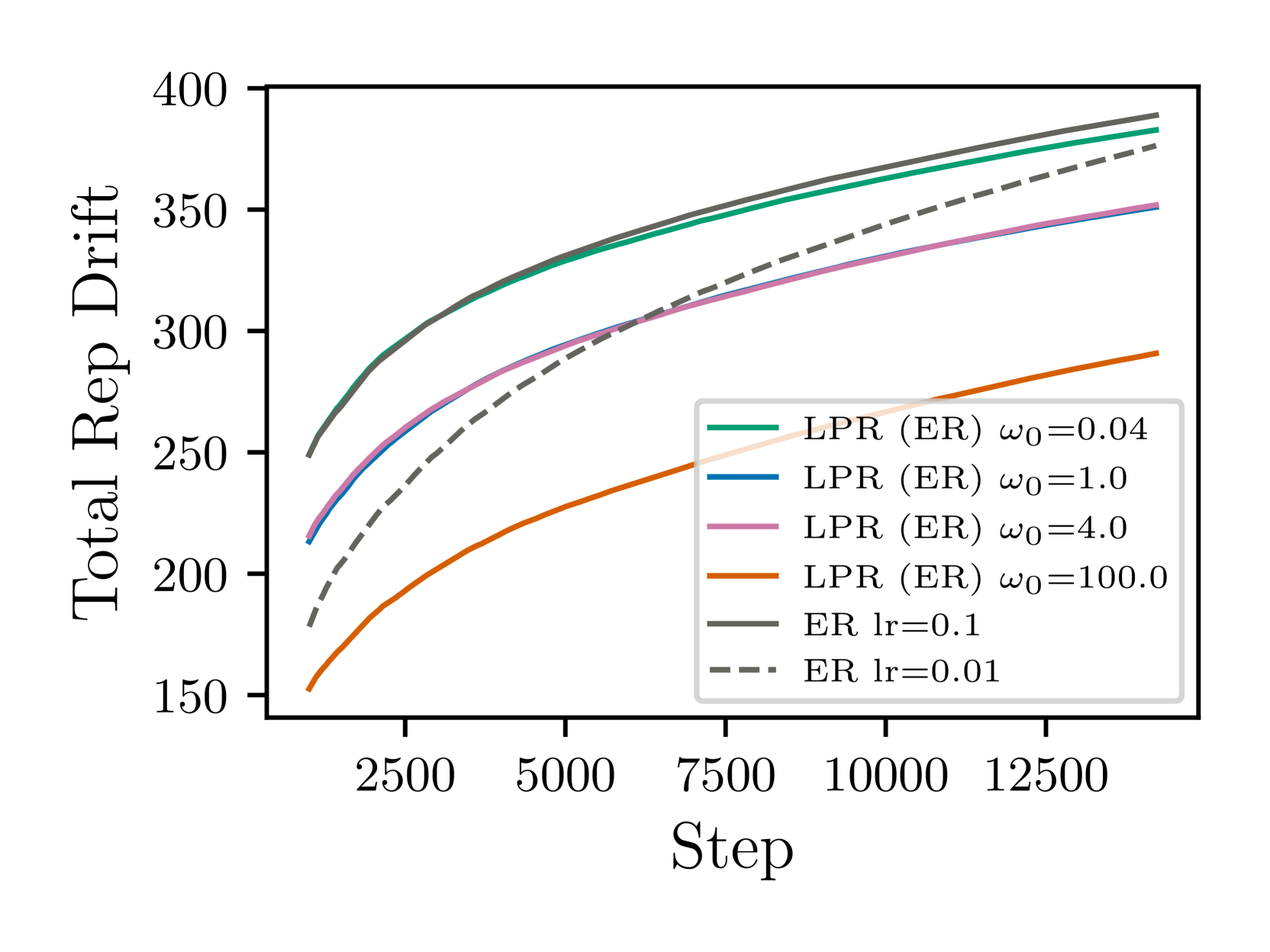
The authors show that applying this proximal point update rule link to "proximal point method" independently to each layer of the network (the "layerwise" aspect) outperforms other continual learning methods on several benchmark tasks. This includes comparisons to techniques like replay, regularization, and weight interpolation.
Critical Analysis
The paper presents a novel and principled approach to continual learning using the proximal point method. However, there are a few potential limitations and areas for further research:
- The method relies on storing and replaying previous task data, which may not be practical in all real-world scenarios where data storage is limited.
- The experiments are conducted on relatively simple benchmark tasks, and it's unclear how well the method would scale to more complex, real-world problems.
- The authors do not explore the sensitivity of the method to hyperparameter choices, such as the relative weighting of the proximal and task-specific terms in the loss function.
Additionally, it would be valuable for future work to investigate the theoretical properties of the proximal point method in the context of continual learning, such as its convergence guarantees and its ability to prevent catastrophic forgetting under different assumptions about the task distribution and network architecture.
Conclusion
The "Layerwise Proximal Replay" method proposed in this paper offers a principled approach to mitigating catastrophic forgetting in continual learning. By incorporating a proximal point term into the loss function, the method encourages the neural network to update its parameters in a way that keeps it close to its previous state, allowing it to learn new tasks without forgetting what it has already learned.
The authors demonstrate the effectiveness of this approach on several benchmark tasks, and the technique shows promise as a general-purpose continual learning method. However, further research is needed to address potential limitations and explore the method's performance on more complex, real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Layerwise Proximal Replay: A Proximal Point Method for Online Continual Learning
Jason Yoo, Yunpeng Liu, Frank Wood, Geoff Pleiss
In online continual learning, a neural network incrementally learns from a non-i.i.d. data stream. Nearly all online continual learning methods employ experience replay to simultaneously prevent catastrophic forgetting and underfitting on past data. Our work demonstrates a limitation of this approach: neural networks trained with experience replay tend to have unstable optimization trajectories, impeding their overall accuracy. Surprisingly, these instabilities persist even when the replay buffer stores all previous training examples, suggesting that this issue is orthogonal to catastrophic forgetting. We minimize these instabilities through a simple modification of the optimization geometry. Our solution, Layerwise Proximal Replay (LPR), balances learning from new and replay data while only allowing for gradual changes in the hidden activation of past data. We demonstrate that LPR consistently improves replay-based online continual learning methods across multiple problem settings, regardless of the amount of available replay memory.
Read more7/22/2024
0
Learning fast changing slow in spiking neural networks
Cristiano Capone, Paolo Muratore
Reinforcement learning (RL) faces substantial challenges when applied to real-life problems, primarily stemming from the scarcity of available data due to limited interactions with the environment. This limitation is exacerbated by the fact that RL often demands a considerable volume of data for effective learning. The complexity escalates further when implementing RL in recurrent spiking networks, where inherent noise introduced by spikes adds a layer of difficulty. Life-long learning machines must inherently resolve the plasticity-stability paradox. Striking a balance between acquiring new knowledge and maintaining stability is crucial for artificial agents. To address this challenge, we draw inspiration from machine learning technology and introduce a biologically plausible implementation of proximal policy optimization, referred to as lf-cs (learning fast changing slow). Our approach results in two notable advancements: firstly, the capacity to assimilate new information into a new policy without requiring alterations to the current policy; and secondly, the capability to replay experiences without experiencing policy divergence. Furthermore, when contrasted with other experience replay (ER) techniques, our method demonstrates the added advantage of being computationally efficient in an online setting. We demonstrate that the proposed methodology enhances the efficiency of learning, showcasing its potential impact on neuromorphic and real-world applications.
Read more4/10/2024

0
Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
Read more4/22/2024

0
Watch Your Step: Optimal Retrieval for Continual Learning at Scale
Truman Hickok, Dhireesha Kudithipudi
In continual learning, a model learns incrementally over time while minimizing interference between old and new tasks. One of the most widely used approaches in continual learning is referred to as replay. Replay methods support interleaved learning by storing past experiences in a replay buffer. Although there are methods for selectively constructing the buffer and reprocessing its contents, there is limited exploration of the problem of selectively retrieving samples from the buffer. Current solutions have been tested in limited settings and, more importantly, in isolation. Existing work has also not explored the impact of duplicate replays on performance. In this work, we propose a framework for evaluating selective retrieval strategies, categorized by simple, independent class- and sample-selective primitives. We evaluated several combinations of existing strategies for selective retrieval and present their performances. Furthermore, we propose a set of strategies to prevent duplicate replays and explore whether new samples with low loss values can be learned without replay. In an effort to match our problem setting to a realistic continual learning pipeline, we restrict our experiments to a setting involving a large, pre-trained, open vocabulary object detection model, which is fully fine-tuned on a sequence of 15 datasets.
Read more5/13/2024