Lazy Diffusion Transformer for Interactive Image Editing
2404.12382
0
1

Abstract
We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a lazy fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
Create account to get full access
Overview
- This paper introduces the Lazy Diffusion Transformer, a novel approach to interactive image editing that combines the power of diffusion models and transformers.
- The key idea is to leverage a pre-trained diffusion model to generate high-quality image samples, while using a transformer-based architecture to efficiently refine and edit these samples based on user inputs.
- This approach aims to enable fast, intuitive, and precise image editing without the need for time-consuming iterative refinement.
Plain English Explanation
The Lazy Diffusion Transformer is a new way to edit images interactively. It combines the strengths of two powerful AI techniques: diffusion models and transformers.
Diffusion models are a type of AI that can generate high-quality images from scratch. However, they can be slow and tedious to use for editing existing images.
Transformers, on the other hand, are great at understanding and manipulating complex data, like text or images. They can quickly refine and edit images based on user inputs.
The Lazy Diffusion Transformer leverages the best of both worlds. It uses a pre-trained diffusion model to generate an initial high-quality image. Then, it uses a transformer-based architecture to let users quickly and precisely edit that image, without having to start from scratch.
This approach aims to make interactive image editing faster, more intuitive, and more precise than traditional methods. Users can make changes to an image and see the results instantly, without waiting for a lengthy iterative process.
Technical Explanation
The key innovation of the Lazy Diffusion Transformer is its hybrid architecture, which combines a pre-trained diffusion model with a transformer-based refinement module.
The diffusion model is used to generate an initial high-quality image based on some user input or prompts. This provides a strong starting point for further editing.
The transformer-based refinement module then takes this initial image and allows the user to make targeted edits and changes. The transformer architecture is well-suited for this task, as it can efficiently understand and manipulate the complex visual information in the image.
The authors demonstrate that this approach outperforms traditional interactive editing methods, such as ClickDiffusion and Sketch-Guided Image Inpainting, in terms of both speed and quality of the edited results.
Additionally, the authors show that the Lazy Diffusion Transformer can be extended to other generative tasks, such as neural radiance field generation and image super-resolution, demonstrating the versatility of the approach.
Critical Analysis
The Lazy Diffusion Transformer represents an exciting advance in interactive image editing, but it does have some potential limitations and areas for further research:
-
The performance of the system is heavily dependent on the quality and capabilities of the pre-trained diffusion model. If the diffusion model struggles with certain types of images or visual features, the Lazy Diffusion Transformer may also have difficulties.
-
The paper does not explore the potential for the system to generate or edit novel content that deviates significantly from the training data. The ability to perform truly creative and open-ended editing remains an open challenge.
-
The computational and memory requirements of the Lazy Diffusion Transformer may limit its deployment on resource-constrained devices, such as mobile phones or embedded systems. Further optimizations may be needed to improve its efficiency.
Despite these potential limitations, the Lazy Diffusion Transformer represents an important step forward in making interactive image editing more powerful, flexible, and accessible to a wide range of users. As the field of generative AI continues to advance, we can expect to see more innovative approaches like this one emerge.
Conclusion
The Lazy Diffusion Transformer is a novel approach to interactive image editing that combines the strengths of diffusion models and transformers. By leveraging a pre-trained diffusion model to generate high-quality initial images and a transformer-based refinement module to enable fast and precise editing, this system aims to make interactive image editing more intuitive, efficient, and accessible.
While the system has some potential limitations, the authors have demonstrated its effectiveness in various generative tasks, and its hybrid architecture suggests a promising direction for further research and development in the field of interactive AI-powered image editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Streamlining Image Editing with Layered Diffusion Brushes
Peyman Gholami, Robert Xiao
0
0
Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
5/2/2024
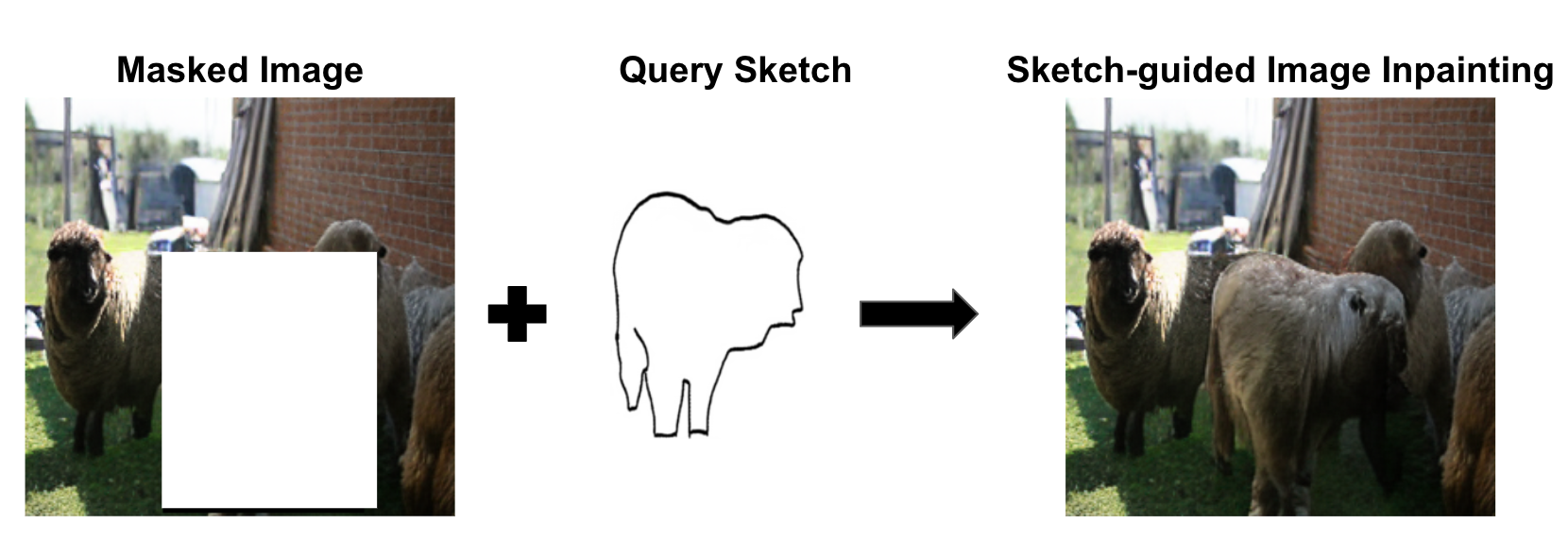
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
0
0
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
4/19/2024
Diffusion-based image inpainting with internal learning
Nicolas Cherel, Andr'es Almansa, Yann Gousseau, Alasdair Newson
0
0
Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
6/7/2024

ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
Alec Helbling, Seongmin Lee, Polo Chau
0
0
Recently, researchers have proposed powerful systems for generating and manipulating images using natural language instructions. However, it is difficult to precisely specify many common classes of image transformations with text alone. For example, a user may wish to change the location and breed of a particular dog in an image with several similar dogs. This task is quite difficult with natural language alone, and would require a user to write a laboriously complex prompt that both disambiguates the target dog and describes the destination. We propose ClickDiffusion, a system for precise image manipulation and generation that combines natural language instructions with visual feedback provided by the user through a direct manipulation interface. We demonstrate that by serializing both an image and a multi-modal instruction into a textual representation it is possible to leverage LLMs to perform precise transformations of the layout and appearance of an image. Code available at https://github.com/poloclub/ClickDiffusion.
4/9/2024