ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing

0

Sign in to get full access
Overview
- This paper presents ClickDiffusion, a novel approach that leverages large language models (LLMs) for interactive and precise image editing.
- ClickDiffusion allows users to make targeted changes to images by providing natural language instructions and clicking on specific regions, enabling an intuitive and powerful image editing experience.
- The method combines the strengths of diffusion models and LLMs to enable fine-grained control over image generation and editing, going beyond the capabilities of previous techniques.
Plain English Explanation
ClickDiffusion is a new way to edit images that uses powerful language models. With ClickDiffusion, you can make detailed changes to an image by simply clicking on a part of the image and typing in what you want to change. The language model then understands your instructions and modifies the image accordingly, allowing you to precisely edit the image in an intuitive way.
This is different from traditional image editing tools, which often require users to navigate complex software interfaces and manually adjust various settings to achieve the desired changes. ClickDiffusion, on the other hand, leverages the natural language understanding capabilities of large language models to make the image editing process more accessible and efficient.
By combining the strengths of diffusion models, which can generate high-quality images, with the flexibility of language models, ClickDiffusion enables users to have fine-grained control over the image generation and editing process. This allows for more creative and personalized image editing experiences, going beyond what was possible with previous techniques.
Technical Explanation
ClickDiffusion builds upon the success of large language models are good prompt learners and semantic augmentation of images using language to develop an interactive image editing framework that harnesses the power of large vision-language models.
The key components of ClickDiffusion include:
- A diffusion model for high-quality image generation, similar to the approach described in MOMA: Multimodal LLM Adapter for Fast Personalized Image Generation.
- A language model that can understand natural language instructions and map them to specific image regions and edits, building on the insights from Harnessing the Power of Large Vision-Language Models for Synthetic Image Generation.
- An interactive interface that allows users to click on regions of the image and provide textual instructions for targeted edits.
The ClickDiffusion framework combines these components to enable a seamless and precise image editing experience, where users can iteratively refine the image by making localized changes based on their natural language inputs.
Critical Analysis
The ClickDiffusion approach addresses several limitations of existing image editing tools, such as the need for specialized skills and the difficulty of making targeted changes. By leveraging the capabilities of large language models, ClickDiffusion offers a more intuitive and accessible way for users to edit images.
However, the paper acknowledges that ClickDiffusion is not without its challenges. The performance of the system is heavily dependent on the quality and robustness of the underlying language and diffusion models. Additionally, the system may struggle with complex or ambiguous language instructions, and ensuring consistent and coherent image edits across multiple iterations can be challenging.
Further research is needed to address these limitations and improve the reliability and scalability of ClickDiffusion. Exploring ways to better integrate user feedback and contextual information into the editing process, as well as investigating the potential biases and ethical considerations of such a system, could also be valuable areas for future work.
Conclusion
ClickDiffusion represents a promising advancement in the field of interactive image editing, leveraging the power of large language models to enable a more intuitive and precise editing experience. By bridging the gap between natural language understanding and high-quality image generation, ClickDiffusion offers a novel approach that could significantly enhance the way people create and modify visual content.
As the field of language-guided image manipulation continues to evolve, research like ClickDiffusion highlights the exciting potential of combining the strengths of different AI models to push the boundaries of what is possible in creative and personalized image editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
Alec Helbling, Seongmin Lee, Polo Chau
Recently, researchers have proposed powerful systems for generating and manipulating images using natural language instructions. However, it is difficult to precisely specify many common classes of image transformations with text alone. For example, a user may wish to change the location and breed of a particular dog in an image with several similar dogs. This task is quite difficult with natural language alone, and would require a user to write a laboriously complex prompt that both disambiguates the target dog and describes the destination. We propose ClickDiffusion, a system for precise image manipulation and generation that combines natural language instructions with visual feedback provided by the user through a direct manipulation interface. We demonstrate that by serializing both an image and a multi-modal instruction into a textual representation it is possible to leverage LLMs to perform precise transformations of the layout and appearance of an image. Code available at https://github.com/poloclub/ClickDiffusion.
Read more4/9/2024
🖼️
0
LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
Paramanand Chandramouli, Kanchana Vaishnavi Gandikota
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
Read more5/7/2024
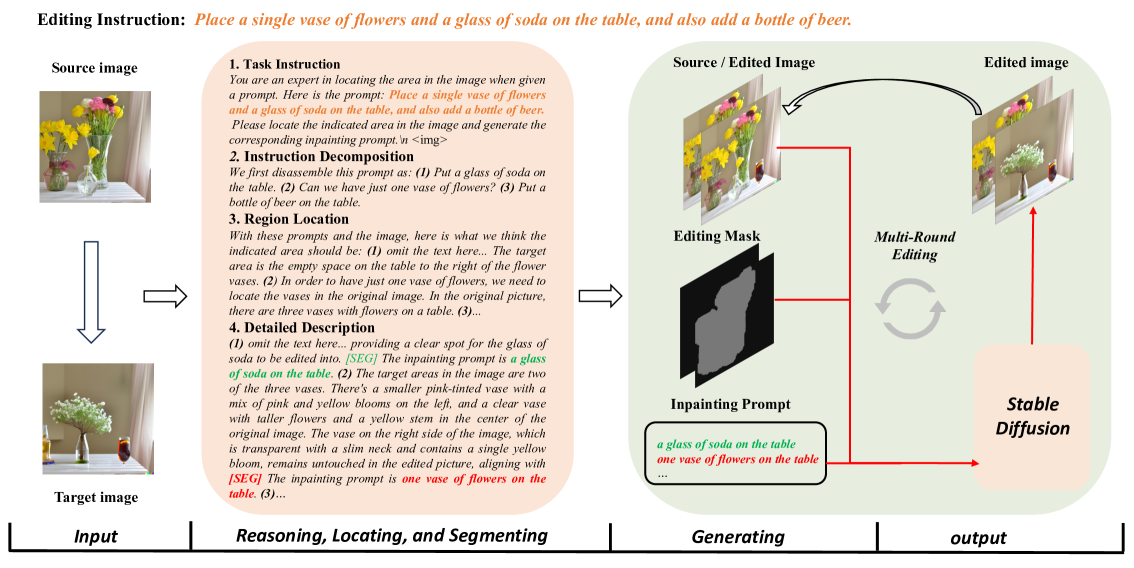
0
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Read more5/28/2024

0
LLM4GEN: Leveraging Semantic Representation of LLMs for Text-to-Image Generation
Mushui Liu, Yuhang Ma, Yang Zhen, Jun Dan, Yunlong Yu, Zeng Zhao, Zhipeng Hu, Bai Liu, Changjie Fan
Diffusion models have exhibited substantial success in text-to-image generation. However, they often encounter challenges when dealing with complex and dense prompts involving multiple objects, attribute binding, and long descriptions. In this paper, we propose a novel framework called textbf{LLM4GEN}, which enhances the semantic understanding of text-to-image diffusion models by leveraging the representation of Large Language Models (LLMs). It can be seamlessly incorporated into various diffusion models as a plug-and-play component. A specially designed Cross-Adapter Module (CAM) integrates the original text features of text-to-image models with LLM features, thereby enhancing text-to-image generation. Additionally, to facilitate and correct entity-attribute relationships in text prompts, we develop an entity-guided regularization loss to further improve generation performance. We also introduce DensePrompts, which contains $7,000$ dense prompts to provide a comprehensive evaluation for the text-to-image generation task. Experiments indicate that LLM4GEN significantly improves the semantic alignment of SD1.5 and SDXL, demonstrating increases of 9.69% and 12.90% in color on T2I-CompBench, respectively. Moreover, it surpasses existing models in terms of sample quality, image-text alignment, and human evaluation.
Read more8/28/2024