Lazy Safety Alignment for Large Language Models against Harmful Fine-tuning

0

Sign in to get full access
Overview
- This paper proposes a technique called "Lazy Safety Alignment" to mitigate the risks of harmful fine-tuning of large language models.
- Large language models trained on general internet data can exhibit biases and generate harmful content when fine-tuned on specific datasets.
- The authors introduce a novel approach to constrain the fine-tuning process and ensure the resulting model remains aligned with safety principles.
Plain English Explanation
Large language models, like GPT-3, are powerful AI systems that can generate human-like text on a wide range of topics. However, when these models are fine-tuned (further trained) on specific datasets, they can sometimes produce biased or harmful content. This is a significant concern as these models are increasingly being used in real-world applications.
To address this issue, the researchers developed a technique called "Lazy Safety Alignment." The core idea is to constrain the fine-tuning process in a way that preserves the model's safety properties, even as it is adapted to a new task or dataset. This involves adding special "safety" components to the model that act as guardrails, ensuring the model's outputs remain aligned with certain ethical principles.
By using this approach, the researchers were able to fine-tune large language models on potentially harmful datasets, such as link to "Navigating the Safety Landscape: Measuring Risks of Fine-tuning Large Language Models", without the model generating content that violated safety guidelines. This is an important step towards making large language models more reliable and trustworthy for real-world applications.
Technical Explanation
The key components of the "Lazy Safety Alignment" approach are:
-
Safety Regularizer: The researchers introduce a "safety regularizer" that is added to the model's loss function during fine-tuning. This regularizer encourages the model to remain aligned with pre-defined safety criteria, such as avoiding the generation of toxic or biased content.
-
Safety Subspace: The authors also propose a "safety subspace" that defines a set of acceptable model behaviors. During fine-tuning, the model's updates are constrained to remain within this subspace, ensuring the model's safety properties are maintained.
-
Iterative Fine-tuning: Instead of a single fine-tuning step, the researchers use an iterative fine-tuning process. After each step, the model's outputs are evaluated for safety, and the fine-tuning is adjusted accordingly.
The researchers evaluated their approach on several benchmark datasets and found that it was effective in mitigating the risks of harmful fine-tuning, while still allowing the model to adapt to the target task. The resulting models exhibited significantly reduced levels of toxicity, bias, and other undesirable behaviors compared to standard fine-tuning methods.
Critical Analysis
The "Lazy Safety Alignment" approach presented in this paper is a promising step towards making large language models more robust and trustworthy. By incorporating safety considerations directly into the fine-tuning process, the researchers have developed a practical technique to address a critical challenge in the field of AI safety.
However, it's important to note that this is an early-stage approach, and there are still several areas for further research and improvement. For example, the specific safety criteria used in the regularizer and subspace may need to be refined and expanded to cover a broader range of safety concerns. Additionally, the iterative fine-tuning process could potentially be optimized for efficiency, as it may be computationally intensive for larger models.
Another potential limitation is that the approach relies on pre-defined safety guidelines, which may not capture all possible safety considerations. As the field of AI safety continues to evolve, there may be a need to develop more flexible and adaptive approaches that can handle emerging safety challenges.
Despite these caveats, the "Lazy Safety Alignment" technique represents an important contribution to the ongoing efforts to make large language models more reliable and trustworthy. By addressing the risks of harmful fine-tuning, this research helps pave the way for the safe and responsible deployment of these powerful AI systems in real-world applications.
Conclusion
The "Lazy Safety Alignment" approach proposed in this paper is a significant advancement in the field of AI safety. By incorporating safety considerations directly into the fine-tuning process, the researchers have developed a practical technique to mitigate the risks of harmful content generation by large language models.
As these models continue to grow in power and influence, it is essential that we have robust mechanisms in place to ensure their safe and responsible use. The "Lazy Safety Alignment" approach represents an important step towards that goal, and the insights gained from this research can inform future work in AI safety and alignment.
Looking ahead, it will be crucial for the research community to build upon these foundational ideas and develop even more sophisticated and comprehensive solutions to the challenges of AI safety. By working collectively to address these issues, we can unlock the full potential of large language models while minimizing the risks and ensuring their beneficial impact on society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lazy Safety Alignment for Large Language Models against Harmful Fine-tuning
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Ling Liu
Recent studies show that Large Language Models (LLMs) with safety alignment can be jail-broken by fine-tuning on a dataset mixed with harmful data. First time in the literature, we show that the jail-broken effect can be mitigated by separating states in the finetuning stage to optimize the alignment and user datasets. Unfortunately, our subsequent study shows that this simple Bi-State Optimization (BSO) solution experiences convergence instability when steps invested in its alignment state is too small, leading to downgraded alignment performance. By statistical analysis, we show that the textit{excess drift} towards consensus could be a probable reason for the instability. To remedy this issue, we propose textbf{L}azy(textbf{i}) textbf{s}afety textbf{a}lignment (textbf{Lisa}), which introduces a proximal term to constraint the drift of each state. Theoretically, the benefit of the proximal term is supported by the convergence analysis, wherein we show that a sufficient large proximal factor is necessary to guarantee Lisa's convergence. Empirically, our results on four downstream finetuning tasks show that Lisa with a proximal term can significantly increase alignment performance while maintaining the LLM's accuracy on the user tasks. Code is available at url{https://github.com/git-disl/Lisa}.
Read more6/28/2024
0
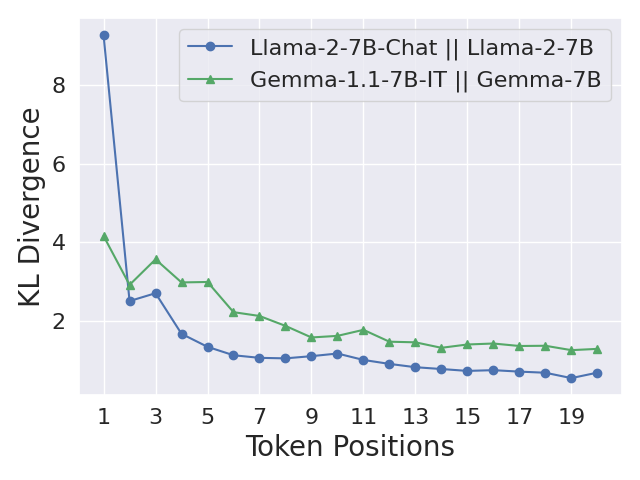
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson
The safety alignment of current Large Language Models (LLMs) is vulnerable. Relatively simple attacks, or even benign fine-tuning, can jailbreak aligned models. We argue that many of these vulnerabilities are related to a shared underlying issue: safety alignment can take shortcuts, wherein the alignment adapts a model's generative distribution primarily over only its very first few output tokens. We refer to this issue as shallow safety alignment. In this paper, we present case studies to explain why shallow safety alignment can exist and provide evidence that current aligned LLMs are subject to this issue. We also show how these findings help explain multiple recently discovered vulnerabilities in LLMs, including the susceptibility to adversarial suffix attacks, prefilling attacks, decoding parameter attacks, and fine-tuning attacks. Importantly, we discuss how this consolidated notion of shallow safety alignment sheds light on promising research directions for mitigating these vulnerabilities. For instance, we show that deepening the safety alignment beyond just the first few tokens can often meaningfully improve robustness against some common exploits. Finally, we design a regularized finetuning objective that makes the safety alignment more persistent against fine-tuning attacks by constraining updates on initial tokens. Overall, we advocate that future safety alignment should be made more than just a few tokens deep.
Read more6/11/2024
👀
0
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models
Yongshuo Zong, Ondrej Bohdal, Tingyang Yu, Yongxin Yang, Timothy Hospedales
Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
Read more6/19/2024
0
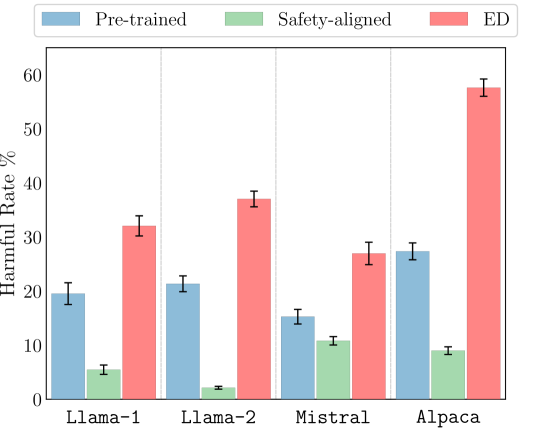
Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
Large language models (LLMs) undergo safety alignment to ensure safe conversations with humans. However, this paper introduces a training-free attack method capable of reversing safety alignment, converting the outcomes of stronger alignment into greater potential for harm by accessing only LLM output token distributions. Specifically, our method achieves this reversal by contrasting the output token distribution of a safety-aligned language model (e.g., Llama-2-chat) against its pre-trained version (e.g., Llama-2), so that the token predictions are shifted towards the opposite direction of safety alignment. We name this method emulated disalignment (ED) because sampling from this contrastive distribution provably emulates the result of fine-tuning to minimize a safety reward. Our experiments with ED across three evaluation datasets and four model families (Llama-1, Llama-2, Mistral, and Alpaca) show that ED doubles the harmfulness of pre-trained models and outperforms strong baselines, achieving the highest harmful rates in 43 out of 48 evaluation subsets by a large margin. Eventually, given ED's reliance on language model output token distributions, which particularly compromises open-source models, our findings highlight the need to reassess the open accessibility of language models, even if they have been safety-aligned. Code is available at https://github.com/ZHZisZZ/emulated-disalignment.
Read more6/7/2024