LCQ: Low-Rank Codebook based Quantization for Large Language Models

0

Sign in to get full access
Overview
- This paper introduces a new quantization technique called Low-Rank Codebook based Quantization (LCQ) for efficiently compressing large language models (LLMs).
- LCQ leverages a low-rank codebook structure to achieve accurate and efficient low-bitwidth quantization of LLM parameters, enabling significant model size reduction without significant accuracy loss.
- The paper presents extensive experiments demonstrating the effectiveness of LCQ on a range of LLMs and benchmarks, including QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models, Feature-Based Low-Rank Compression for Large Language Models, and LLM-QBench: A Benchmark Towards Best Practices for Post-Training Quantization of Large Language Models.
Plain English Explanation
The paper discusses a new way to efficiently compress large language models (LLMs) by reducing the amount of memory they require. LLMs are complex AI models that can understand and generate human-like text, but they often require a lot of storage space, which can make them difficult to deploy on devices with limited resources.
The key idea behind the LCQ (Low-Rank Codebook based Quantization) technique is to represent the model's parameters (the numbers that define how the model works) using a smaller set of values, called a "codebook." This codebook is designed to have a low-rank structure, meaning that it can be expressed using a small number of underlying factors. By using this low-rank codebook, the researchers were able to significantly reduce the size of the model without losing too much of its original performance.
The paper shows that LCQ outperforms other compression techniques, especially on a range of LLM benchmarks. This means that LCQ can make LLMs more efficient and accessible, potentially allowing them to be deployed on a wider range of devices, from smartphones to embedded systems.
Technical Explanation
The paper introduces a new quantization technique called Low-Rank Codebook based Quantization (LCQ) that aims to efficiently compress large language models (LLMs) without significant accuracy loss.
The core idea of LCQ is to leverage a low-rank codebook structure to represent the model parameters. Specifically, the authors propose to decompose the weight matrix of each layer in the LLM into a product of two low-rank matrices, effectively reducing the number of parameters required to represent the original weight matrix.
During the quantization process, the authors first learn the low-rank codebook from the original weight matrices using a novel optimization-based approach. They then quantize the codebook entries to low-bitwidth representations, which can be efficiently stored and used for inference.
The paper presents extensive experiments evaluating LCQ on a range of LLMs and benchmarks, including QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models, Feature-Based Low-Rank Compression for Large Language Models, and LLM-QBench: A Benchmark Towards Best Practices for Post-Training Quantization of Large Language Models. The results show that LCQ can achieve significant model size reduction (up to 16x) with minimal accuracy degradation, outperforming other state-of-the-art quantization techniques.
Critical Analysis
The paper presents a well-designed and comprehensive evaluation of the LCQ technique, considering a range of LLMs and benchmark tasks. The authors have also provided detailed comparisons with other state-of-the-art quantization methods, which helps to contextualize the performance of their approach.
One potential limitation of the LCQ technique is that it relies on a low-rank decomposition of the weight matrices, which may not be optimal for all types of LLMs. The authors acknowledge this and suggest that further research is needed to explore more flexible codebook structures that can better capture the complexity of LLM parameters.
Additionally, the paper does not delve into the computational and memory overhead of the LCQ training and inference processes. It would be valuable to understand the trade-offs between the model size reduction and the additional computational costs required to implement the technique, especially for resource-constrained deployment scenarios.
Further research could also investigate the robustness of LCQ to different types of model fine-tuning or domain shifts, as the performance of quantization techniques can be sensitive to such changes.
Conclusion
The LCQ technique presented in this paper offers a promising approach for efficiently compressing large language models without significant accuracy loss. By leveraging a low-rank codebook structure, the authors have demonstrated significant model size reduction (up to 16x) across a range of LLMs and benchmarks.
The findings of this work have important implications for the deployability and accessibility of LLMs, as they can enable these powerful AI models to be used on a wider range of devices with limited resources, such as smartphones or embedded systems. As the field of natural language processing continues to advance, techniques like LCQ will play a crucial role in making large, complex language models more practical and widely available.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LCQ: Low-Rank Codebook based Quantization for Large Language Models
Wen-Pu Cai, Wu-Jun Li
Large language models~(LLMs) have recently demonstrated promising performance in many tasks. However, the high storage and computational cost of LLMs has become a challenge for deploying LLMs. Weight quantization has been widely used for model compression, which can reduce both storage and computational cost. Most existing weight quantization methods for LLMs use a rank-one codebook for quantization, which results in substantial accuracy loss when the compression ratio is high. In this paper, we propose a novel weight quantization method, called low-rank codebook based quantization~(LCQ), for LLMs. LCQ adopts a low-rank codebook, the rank of which can be larger than one, for quantization. Experiments show that LCQ can achieve better accuracy than existing methods with a negligibly extra storage cost.
Read more6/3/2024
💬
0
Foundations of Large Language Model Compression -- Part 1: Weight Quantization
Sean I. Young
In recent years, compression of large language models (LLMs) has emerged as an important problem to allow language model deployment on resource-constrained devices, reduce computational costs, and mitigate the environmental footprint of large-scale AI infrastructure. In this paper, we present the foundations of LLM quantization from a convex optimization perspective and propose a quantization method that builds on these foundations and outperforms previous methods. Our quantization framework, CVXQ, scales to models containing hundreds of billions of weight parameters and provides users with the flexibility to compress models to any specified model size, post-training. A reference implementation of CVXQ can be obtained from https://github.com/seannz/cvxq.
Read more9/4/2024
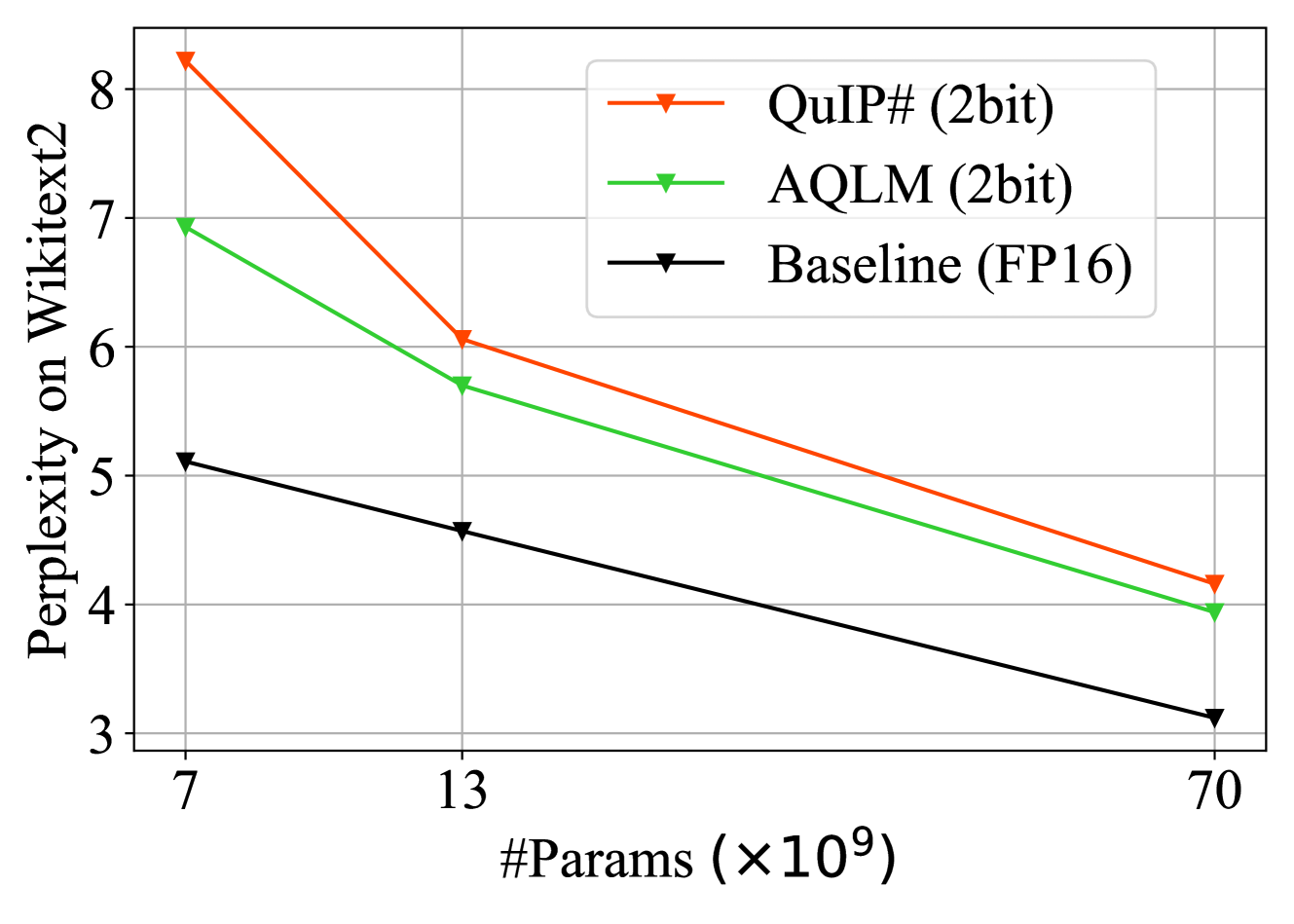
0
Extreme Compression of Large Language Models via Additive Quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh
The emergence of accurate open large language models (LLMs) has led to a race towards performant quantization techniques which can enable their execution on end-user devices. In this paper, we revisit the problem of extreme LLM compression-defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter-from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our algorithm, called AQLM, generalizes the classic Additive Quantization (AQ) approach for information retrieval to advance the state-of-the-art in LLM compression, via two innovations: 1) learned additive quantization of weight matrices in input-adaptive fashion, and 2) joint optimization of codebook parameters across each transformer blocks. Broadly, AQLM is the first scheme that is Pareto optimal in terms of accuracy-vs-model-size when compressing to less than 3 bits per parameter, and significantly improves upon all known schemes in the extreme compression (2bit) regime. In addition, AQLM is practical: we provide fast GPU and CPU implementations of AQLM for token generation, which enable us to match or outperform optimized FP16 implementations for speed, while executing in a much smaller memory footprint.
Read more9/12/2024

0
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices
Jung Hyun Lee, Jeonghoon Kim, June Yong Yang, Se Jung Kwon, Eunho Yang, Kang Min Yoo, Dongsoo Lee
With the commercialization of large language models (LLMs), weight-activation quantization has emerged to compress and accelerate LLMs, achieving high throughput while reducing inference costs. However, existing post-training quantization (PTQ) techniques for quantizing weights and activations of LLMs still suffer from non-negligible accuracy drops, especially on massive multitask language understanding. To address this issue, we propose Low-Rank Quantization (LRQ) $-$ a simple yet effective post-training weight quantization method for LLMs that reconstructs the outputs of an intermediate Transformer block by leveraging low-rank weight-scaling matrices, replacing the conventional full weight-scaling matrices that entail as many learnable scales as their associated weights. Thanks to parameter sharing via low-rank structure, LRQ only needs to learn significantly fewer parameters while enabling the individual scaling of weights, thus boosting the generalization capability of quantized LLMs. We show the superiority of LRQ over prior LLM PTQ works under (i) $8$-bit weight and per-tensor activation quantization, (ii) $4$-bit weight and $8$-bit per-token activation quantization, and (iii) low-bit weight-only quantization schemes. Our code is available at url{https://github.com/onliwad101/FlexRound_LRQ} to inspire LLM researchers and engineers.
Read more7/17/2024