Leader Reward for POMO-Based Neural Combinatorial Optimization
2405.13947
0
0
🧠
Abstract
Deep neural networks based on reinforcement learning (RL) for solving combinatorial optimization (CO) problems are developing rapidly and have shown a tendency to approach or even outperform traditional solvers. However, existing methods overlook an important distinction: CO problems differ from other traditional problems in that they focus solely on the optimal solution provided by the model within a specific length of time, rather than considering the overall quality of all solutions generated by the model. In this paper, we propose Leader Reward and apply it during two different training phases of the Policy Optimization with Multiple Optima (POMO) model to enhance the model's ability to generate optimal solutions. This approach is applicable to a variety of CO problems, such as the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Flexible Flow Shop Problem (FFSP), but also works well with other POMO-based models or inference phase's strategies. We demonstrate that Leader Reward greatly improves the quality of the optimal solutions generated by the model. Specifically, we reduce the POMO's gap to the optimum by more than 100 times on TSP100 with almost no additional computational overhead.
Create account to get full access
Overview
- Deep neural networks based on reinforcement learning (RL) have shown promise in solving combinatorial optimization (CO) problems, often outperforming traditional solvers.
- Existing methods focus on the optimal solution provided by the model within a specific time, rather than considering the overall quality of all solutions generated.
- This paper proposes a new approach called "Leader Reward" to enhance the model's ability to generate optimal solutions for various CO problems.
Plain English Explanation
Combinatorial optimization (CO) problems are a type of problem where the goal is to find the best solution from a large number of possible options. Examples include the Traveling Salesman Problem (finding the shortest route to visit multiple locations) and the Capacitated Vehicle Routing Problem (planning the most efficient routes for a fleet of vehicles).
Researchers have been developing deep neural networks using reinforcement learning (RL) to tackle these types of problems. These AI models are able to learn how to solve CO problems by trial and error, often matching or even outperforming traditional optimization algorithms.
However, the existing RL-based approaches have a key limitation: they focus solely on the best solution the model comes up with, rather than considering the overall quality of all the solutions the model generates. This paper proposes a new technique called "Leader Reward" to address this issue.
The idea behind Leader Reward is to not just reward the model for finding the optimal solution, but also to encourage it to generate a diverse set of high-quality solutions. By doing so, the model can learn to be more reliable and consistent in its problem-solving abilities.
The authors demonstrate that applying Leader Reward during the training of a POMO-based RL model can significantly improve its performance on a variety of CO problems, including the Traveling Salesman Problem, the Capacitated Vehicle Routing Problem, and the Flexible Flow Shop Problem.
Technical Explanation
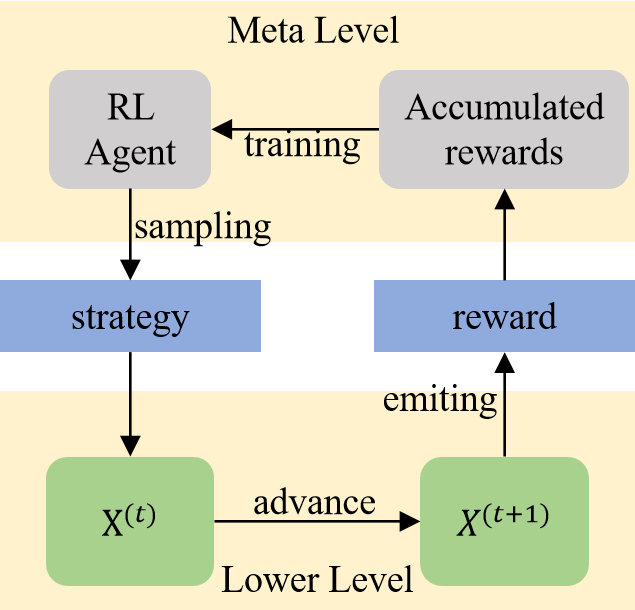
The paper focuses on the Policy Optimization with Multiple Optima (POMO) model, which is a reinforcement learning-based approach for solving combinatorial optimization problems. POMO uses a neural network to learn a policy that can generate multiple high-quality solutions for a given problem instance.
The key innovation in this paper is the introduction of the "Leader Reward" technique, which is applied during two different training phases of the POMO model:
-
Policy Training Phase: In this phase, the model is trained to generate diverse, high-quality solutions. The Leader Reward encourages the model to not just find the optimal solution, but to also generate a diverse set of near-optimal solutions.
-
Value Network Training Phase: In this phase, the model learns to accurately evaluate the quality of the generated solutions. The Leader Reward ensures that the model places more importance on the quality of the overall solution set, rather than just the single best solution.
The authors demonstrate the effectiveness of Leader Reward on several combinatorial optimization problems, including the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Flexible Flow Shop Problem (FFSP). They show that the POMO model with Leader Reward can significantly outperform the original POMO model, reducing the gap to the optimal solution by more than 100 times on the TSP100 problem with almost no additional computational overhead.
Critical Analysis
The paper presents a novel and promising approach to enhancing the performance of deep neural networks for combinatorial optimization problems. The key strength of the Leader Reward technique is that it focuses on improving the overall quality of the solutions generated by the model, rather than just optimizing for the single best solution.
However, the paper does not provide a comprehensive analysis of the limitations or potential drawbacks of the proposed method. For example, it would be interesting to understand how the Leader Reward technique performs on larger-scale problems or more complex CO problems, and whether there are any trade-offs in terms of computational efficiency or training complexity.
Additionally, the paper could have explored the potential for combining Leader Reward with other RL-based optimization techniques, such as evolutionary algorithms or proximal policy optimization, to further enhance the model's performance and robustness.
Overall, the Leader Reward approach is a promising contribution to the field of deep learning for combinatorial optimization, and the authors have demonstrated its effectiveness on several benchmark problems. However, further research and analysis would be needed to fully understand the strengths, limitations, and potential applications of this technique.
Conclusion
This paper introduces a new technique called "Leader Reward" to enhance the performance of deep neural networks based on reinforcement learning for solving combinatorial optimization problems. The key idea is to not just focus on finding the optimal solution, but to also encourage the model to generate a diverse set of high-quality solutions.
The authors demonstrate that applying Leader Reward during the training of a POMO-based RL model can significantly improve its performance on a variety of CO problems, including the Traveling Salesman Problem, the Capacitated Vehicle Routing Problem, and the Flexible Flow Shop Problem. This approach has the potential to make AI-powered optimization more reliable and consistent, with far-reaching applications in fields like logistics, scheduling, and resource allocation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RLEMMO: Evolutionary Multimodal Optimization Assisted By Deep Reinforcement Learning
Hongqiao Lian, Zeyuan Ma, Hongshu Guo, Ting Huang, Yue-Jiao Gong
0
0
Solving multimodal optimization problems (MMOP) requires finding all optimal solutions, which is challenging in limited function evaluations. Although existing works strike the balance of exploration and exploitation through hand-crafted adaptive strategies, they require certain expert knowledge, hence inflexible to deal with MMOP with different properties. In this paper, we propose RLEMMO, a Meta-Black-Box Optimization framework, which maintains a population of solutions and incorporates a reinforcement learning agent for flexibly adjusting individual-level searching strategies to match the up-to-date optimization status, hence boosting the search performance on MMOP. Concretely, we encode landscape properties and evolution path information into each individual and then leverage attention networks to advance population information sharing. With a novel reward mechanism that encourages both quality and diversity, RLEMMO can be effectively trained using a policy gradient algorithm. The experimental results on the CEC2013 MMOP benchmark underscore the competitive optimization performance of RLEMMO against several strong baselines.
4/15/2024
Self-Improved Learning for Scalable Neural Combinatorial Optimization
Fu Luo, Xi Lin, Zhenkun Wang, Xialiang Tong, Mingxuan Yuan, Qingfu Zhang
0
0
The end-to-end neural combinatorial optimization (NCO) method shows promising performance in solving complex combinatorial optimization problems without the need for expert design. However, existing methods struggle with large-scale problems, hindering their practical applicability. To overcome this limitation, this work proposes a novel Self-Improved Learning (SIL) method for better scalability of neural combinatorial optimization. Specifically, we develop an efficient self-improved mechanism that enables direct model training on large-scale problem instances without any labeled data. Powered by an innovative local reconstruction approach, this method can iteratively generate better solutions by itself as pseudo-labels to guide efficient model training. In addition, we design a linear complexity attention mechanism for the model to efficiently handle large-scale combinatorial problem instances with low computation overhead. Comprehensive experiments on the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 100K nodes in both uniform and real-world distributions demonstrate the superior scalability of our method.
5/3/2024

DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Li Zhao, Di He, Jiang Bian, Liwei Wang
0
0
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
4/30/2024

GLHF: General Learned Evolutionary Algorithm Via Hyper Functions
Xiaobin Li, Kai Wu, Yujian Betterest Li, Xiaoyu Zhang, Handing Wang, Jing Liu
0
0
Pretrained Optimization Models (POMs) leverage knowledge gained from optimizing various tasks, providing efficient solutions for new optimization challenges through direct usage or fine-tuning. Despite the inefficiencies and limited generalization abilities observed in current POMs, our proposed model, the general pre-trained optimization model (GPOM), addresses these shortcomings. GPOM constructs a population-based pretrained Black-Box Optimization (BBO) model tailored for continuous optimization. Evaluation on the BBOB benchmark and two robot control tasks demonstrates that GPOM outperforms other pretrained BBO models significantly, especially for high-dimensional tasks. Its direct optimization performance exceeds that of state-of-the-art evolutionary algorithms and POMs. Furthermore, GPOM exhibits robust generalization capabilities across diverse task distributions, dimensions, population sizes, and optimization horizons.
5/8/2024