RLEMMO: Evolutionary Multimodal Optimization Assisted By Deep Reinforcement Learning
2404.08242
0
0
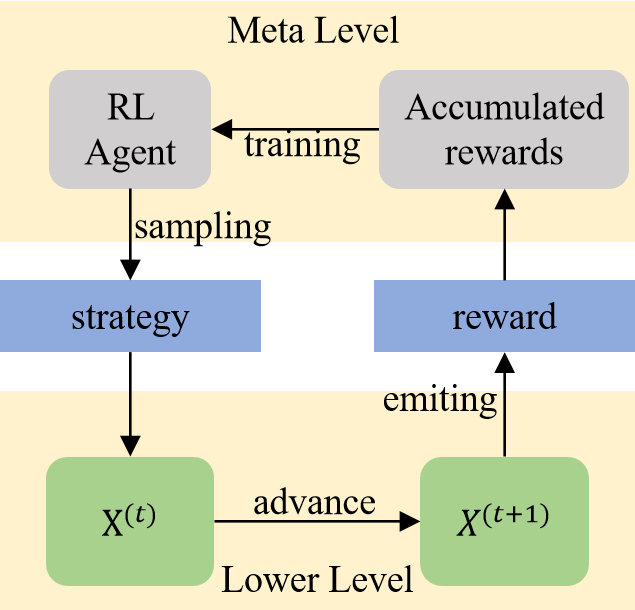
Abstract
Solving multimodal optimization problems (MMOP) requires finding all optimal solutions, which is challenging in limited function evaluations. Although existing works strike the balance of exploration and exploitation through hand-crafted adaptive strategies, they require certain expert knowledge, hence inflexible to deal with MMOP with different properties. In this paper, we propose RLEMMO, a Meta-Black-Box Optimization framework, which maintains a population of solutions and incorporates a reinforcement learning agent for flexibly adjusting individual-level searching strategies to match the up-to-date optimization status, hence boosting the search performance on MMOP. Concretely, we encode landscape properties and evolution path information into each individual and then leverage attention networks to advance population information sharing. With a novel reward mechanism that encourages both quality and diversity, RLEMMO can be effectively trained using a policy gradient algorithm. The experimental results on the CEC2013 MMOP benchmark underscore the competitive optimization performance of RLEMMO against several strong baselines.
Create account to get full access
Overview
- This paper presents a new method called RLEMMO (Reinforcement Learning-Assisted Evolutionary Multimodal Optimization) that combines evolutionary algorithms and deep reinforcement learning to tackle multimodal optimization problems.
- The key idea is to use a deep reinforcement learning agent to adaptively configure the parameters of an evolutionary algorithm, allowing it to better navigate complex multimodal landscapes.
- The authors demonstrate the effectiveness of RLEMMO on a variety of benchmark problems and show that it outperforms traditional evolutionary approaches as well as state-of-the-art multimodal optimization algorithms.
Plain English Explanation
The paper describes a new way to solve optimization problems that have multiple good solutions, called "multimodal" problems. Optimization problems often have a single best solution, but in the real world, many problems have multiple valid solutions that are all good in their own way.
The new method, called RLEMMO, combines two powerful techniques: evolutionary algorithms and deep reinforcement learning. Evolutionary algorithms work by randomly trying out different solutions and keeping the best ones, similar to how natural selection works. Deep reinforcement learning uses artificial intelligence to learn how to make good decisions.
The key insight of RLEMMO is to use the reinforcement learning system to figure out the best way to configure the parameters of the evolutionary algorithm as it's searching for solutions. This allows the algorithm to adapt and navigate the complex landscape of possible solutions more effectively.
The researchers tested RLEMMO on a variety of benchmark problems and showed that it outperformed traditional evolutionary approaches as well as other state-of-the-art multimodal optimization algorithms. This suggests that the combination of evolutionary algorithms and deep reinforcement learning can be a powerful tool for solving real-world optimization problems with multiple good solutions.
Technical Explanation
The paper introduces a new method called RLEMMO (Reinforcement Learning-Assisted Evolutionary Multimodal Optimization) that combines evolutionary algorithms and deep reinforcement learning to tackle multimodal optimization problems.
The core idea is to use a deep reinforcement learning agent to adaptively configure the parameters of an evolutionary algorithm, allowing it to better navigate complex multimodal landscapes. The reinforcement learning agent observes the performance of the evolutionary algorithm and learns to adjust its parameters, such as mutation rate and population size, to improve its ability to find multiple optima.
The authors evaluate RLEMMO on a suite of benchmark multimodal optimization problems and compare its performance to traditional evolutionary approaches as well as state-of-the-art multimodal optimization algorithms, such as DEMO and OMNI-SMOLA. Their results show that RLEMMO consistently outperforms these other methods, demonstrating the benefits of the combined evolutionary and reinforcement learning approach.
Critical Analysis
The paper provides a comprehensive evaluation of RLEMMO and convincingly demonstrates its advantages over existing multimodal optimization methods. However, there are a few potential limitations and areas for future research worth considering:
-
The paper does not provide a detailed analysis of the computational complexity and runtime of RLEMMO compared to the other algorithms. This information would be valuable for understanding the practical feasibility of deploying RLEMMO in real-world applications.
-
The authors only test RLEMMO on synthetic benchmark problems, which may not fully capture the challenges of real-world multimodal optimization tasks. Further evaluation on more diverse and realistic problem domains would help validate the generalizability of RLEMMO's performance.
-
The paper does not discuss potential limitations or failure modes of the RLEMMO approach. It would be helpful to understand under what conditions the reinforcement learning agent may struggle to effectively configure the evolutionary algorithm, and how these issues could be mitigated.
Overall, the RLEMMO method represents an intriguing and promising direction for enhancing multimodal optimization capabilities. The authors have made a valuable contribution, but there remains room for further research and refinement of the approach.
Conclusion
This paper presents a novel method called RLEMMO that combines evolutionary algorithms and deep reinforcement learning to tackle multimodal optimization problems. The key innovation is the use of a reinforcement learning agent to adaptively configure the parameters of the evolutionary algorithm, allowing it to more effectively navigate complex multimodal landscapes.
The authors demonstrate the effectiveness of RLEMMO on a variety of benchmark problems, showing that it outperforms traditional evolutionary approaches as well as state-of-the-art multimodal optimization algorithms. This suggests that the integration of evolutionary and reinforcement learning techniques can be a powerful tool for solving real-world optimization problems with multiple valid solutions.
While the paper provides a strong technical foundation, there are opportunities for further research to address potential limitations and expand the application of RLEMMO to more diverse problem domains. Overall, this work represents an exciting advancement in the field of multimodal optimization and AI-assisted optimization more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Next Era of Multi-objective Optimization: Large Language Models as Architects of Evolutionary Operators
Yuxiao Huang, Shenghao Wu, Wenjie Zhang, Jibin Wu, Liang Feng, Kay Chen Tan
0
0
Multi-objective optimization problems (MOPs) are prevalent in various real-world applications, necessitating sophisticated solutions that balance conflicting objectives. Traditional evolutionary algorithms (EAs), while effective, often rely on domain-specific expert knowledge and iterative tuning, which can impede innovation when encountering novel MOPs. Very recently, the emergence of Large Language Models (LLMs) has revolutionized software engineering by enabling the autonomous development and refinement of programs. Capitalizing on this advancement, we propose a new LLM-based framework for evolving EA operators, designed to address a wide array of MOPs. This framework facilitates the production of EA operators without the extensive demands for expert intervention, thereby streamlining the design process. To validate the efficacy of our approach, we have conducted extensive empirical studies across various categories of MOPs. The results demonstrate the robustness and superior performance of our LLM-evolved operators.
6/14/2024
💬
Large Language Model-Aided Evolutionary Search for Constrained Multiobjective Optimization
Zeyi Wang, Songbai Liu, Jianyong Chen, Kay Chen Tan
0
0
Evolutionary algorithms excel in solving complex optimization problems, especially those with multiple objectives. However, their stochastic nature can sometimes hinder rapid convergence to the global optima, particularly in scenarios involving constraints. In this study, we employ a large language model (LLM) to enhance evolutionary search for solving constrained multi-objective optimization problems. Our aim is to speed up the convergence of the evolutionary population. To achieve this, we finetune the LLM through tailored prompt engineering, integrating information concerning both objective values and constraint violations of solutions. This process enables the LLM to grasp the relationship between well-performing and poorly performing solutions based on the provided input data. Solution's quality is assessed based on their constraint violations and objective-based performance. By leveraging the refined LLM, it can be used as a search operator to generate superior-quality solutions. Experimental evaluations across various test benchmarks illustrate that LLM-aided evolutionary search can significantly accelerate the population's convergence speed and stands out competitively against cutting-edge evolutionary algorithms.
5/10/2024

R2 Indicator and Deep Reinforcement Learning Enhanced Adaptive Multi-Objective Evolutionary Algorithm
Farajollah Tahernezhad-Javazm, Farajollah Tahernezhad-Javazm, Naomi Du Bois, Alice E. Smith, Damien Coyle
0
0
Choosing an appropriate optimization algorithm is essential to achieving success in optimization challenges. Here we present a new evolutionary algorithm structure that utilizes a reinforcement learning-based agent aimed at addressing these issues. The agent employs a double deep q-network to choose a specific evolutionary operator based on feedback it receives from the environment during optimization. The algorithm's structure contains five single-objective evolutionary algorithm operators. This single-objective structure is transformed into a multi-objective one using the R2 indicator. This indicator serves two purposes within our structure: first, it renders the algorithm multi-objective, and second, provides a means to evaluate each algorithm's performance in each generation to facilitate constructing the reinforcement learning-based reward function. The proposed R2-reinforcement learning multi-objective evolutionary algorithm (R2-RLMOEA) is compared with six other multi-objective algorithms that are based on R2 indicators. These six algorithms include the operators used in R2-RLMOEA as well as an R2 indicator-based algorithm that randomly selects operators during optimization. We benchmark performance using the CEC09 functions, with performance measured by inverted generational distance and spacing. The R2-RLMOEA algorithm outperforms all other algorithms with strong statistical significance (p<0.001) when compared with the average spacing metric across all ten benchmarks.
4/15/2024
🧠
Leader Reward for POMO-Based Neural Combinatorial Optimization
Chaoyang Wang, Pengzhi Cheng, Jingze Li, Weiwei Sun
0
0
Deep neural networks based on reinforcement learning (RL) for solving combinatorial optimization (CO) problems are developing rapidly and have shown a tendency to approach or even outperform traditional solvers. However, existing methods overlook an important distinction: CO problems differ from other traditional problems in that they focus solely on the optimal solution provided by the model within a specific length of time, rather than considering the overall quality of all solutions generated by the model. In this paper, we propose Leader Reward and apply it during two different training phases of the Policy Optimization with Multiple Optima (POMO) model to enhance the model's ability to generate optimal solutions. This approach is applicable to a variety of CO problems, such as the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Flexible Flow Shop Problem (FFSP), but also works well with other POMO-based models or inference phase's strategies. We demonstrate that Leader Reward greatly improves the quality of the optimal solutions generated by the model. Specifically, we reduce the POMO's gap to the optimum by more than 100 times on TSP100 with almost no additional computational overhead.
5/24/2024